2024. 9. 30. 11:00ㆍPaper Review/Large Language Model (LLM)
What Language Model Architecture and Pretraining Objectvie Work Best for Zero-Shot Generalization, International Conference on Machine Learning, PMLR (Proceedings of Machine Learning Research), 2022.
https://arxiv.org/abs/2204.05832
What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?
Large pretrained Transformer language models have been shown to exhibit zero-shot generalization, i.e. they can perform a wide variety of tasks that they were not explicitly trained on. However, the architectures and pretraining objectives used across stat
arxiv.org
Big-tech 기업들이 왜 GPT (decoder-only)계열 LLM에 열을 올리는지 궁금해서 읽게 된 논문입니다.
실제 저자들도 Hugging Face, Google, Allen Institute for AI 등 대기업과 AI 연구소가 함께 참여했네요.
저와 같은 궁금증을 지니셨던 분인데, 이 분의 글을 먼저 읽고 논문을 읽어도 도움이 많이 될 것 같습니다.
https://medium.com/@yumo-bai/why-are-most-llms-decoder-only-590c903e4789
Why are most LLMs decoder-only?
Dive into the rabbit hole of recent advancement in Large Language Models
medium.com
* 개인의 견해가 들어간 문구는 파란색으로 처리하였습니다.
Abstract
대규모 Transformer 계열의 모델들은 zero-shot generalization에서 성능을 보임. 즉, 이전에 학습하지 않았던 task에서도 일반적인 성능으로 task 수행이 가능해진 것. 하지만, state-of-art (SOTA) 모델들간 구조와 training 기법이 다른데, 이런 것들에 대한 비교는 잘 이뤄지지 않음 (즉, transformer 모델을 보면, encoder only, decoder only, encoder-decoder 구조를 가진 모델들이 있는데, 어떤 구조를 가진 모델이 가장 성능이 좋은지에 대해서는 다뤄지지 않음). 본 논문에서는, 모델 선택 부터 어떤 모델이 zero-shot generalization에서 가장 높은 성능을 자랑하는지 다방면에서 평가함. 특별히, text-to-text 모델에만 집중해서 세 가지 구조를 가진 모델을 비교함 (causal decoder-only, non-causal decoder only, encoder-decoder). 5B 이상의 모델에, 170B 토큰을 기반으로 훈련. 따라서, 모델의 크기 커지는 것에 따라서도 어느 정도 일반화가 가능함. 실험결과, auto-regressive 방식으로 훈련된 causal decoder only 구조의 모델이 가장 높은 성능을 보임. 하지만, non-causal visibility 모델이 maksed language modeling (MLM)으로 사전 학습된 이후, multi-task finetuning을 거쳤을 때, 모든 실험에서 가장 높은 성능을 보임.
이번 논문 리뷰는 이해를 돕기 위해 Background를 먼저 설명하고 Introduction으로 넘어가고자해요.
우리가 알아야하는 정말 다양한 용어가 나오기 때문에 이 부분을 먼저 집고 넘어가면 좋을 것 같습니다.
2 Background
저는 여기서 처음으로 non-causal decoder의 개념을 알아갔습니다.
지금까지 BERT 계열의 encoder는 양방향성, GPT 계열의 decoder는 일방향성이라고 철썩같이 믿고 있었는데, 철썩 맞았네요.
하지만, 논문의 결과가 더 신기한건 그럼에도 불구하고 초기 모델 설정은 단방향성 계열의 GPT가 더 성능이 좋다는 것입니다...!
2.1 Architectures
Transformer.
실상 현재까지의 모든 SOTA LLM 모델들은 모두 transformer 구조 기반임. Transformer 구조의 핵심은 multi-headed self attention, layer normalization, a dense two-layer feedforward network로 이루어진 transformer 블록임. Transformer는 결국 이런 블록들이 쌓여진 구조. Transformer가 2017년도에 처음 발표된 이후, 다양한 변형 구조들이 제안됨. 모델들 간 가장 큰 차이점은 input으로 받는 토큰에 대한 masking 패턴임. 이런 input은 모델이 그 다음을 예측하는 맥락을 제공함. Figure2를 통해 세 가지 모델간 masking 패턴의 차이를 알 수 있음.

* 약간, 아니 조금 많이 불친절한 그림덕에 또 애를 먹었습니다. 제 해석이 궁금하신 분만 읽어주세요.
Q1. Causal Decoder, Non-causal Decoder, Encoder-Decoder간 Attention pattern의 차이는?
A1. Figure2에서 말하고 싶은 바는 명확합니다. 내가 다음 토큰을 예측할 때, 어디를 attention, 눈 부릅 뜨고 살펴보겠냐예요. Causal Decoder는 무난하게 이해합니다. 예를 들어 문장 속 'I'는 이전에 다른 단어가 없기 때문에 살펴볼게 없죠. 하지만 'decoder'는 이전의 'I', 'am', 'a', 'causal'이 있으니깐 앞에 나온 이 단어들을 기반으로 예측을 하게 됩니다. 노란색 사각형 블록들이 내가 살펴볼 수 있는 (즉, 맥락을 볼 수 있는) 단어/토큰들인거죠.
반면, Non-causual Decoder 그림을 보면, 여기서 부터 엥? 하게 됩니다. Non-causal - 비인과적인 관계를 지닌 모델이니깐 단어를 예측할 때, 꼭 앞이 아닌 뒤에서도 힌트를 얻을 수 있다는 건데 그림을 보면 노란색 사각형 블록이 'am' 에서 밖에 추가가 되지 않았어요. 그리고나서 Encoder-Decoder 모델을 보면 또 한 번 엥?? 하게 됩니다. 뭐야 그림이 똑같아... 하지만, 눈을 잘 떠보면 Encoder-Decoder 모델에는 Encoder와 Decoder 부분이 나눠 표시된 걸 볼 수 있어요.
이제 다시 Non-causal decoder와 Encoder-Decoder를 볼까요? 결국 Non-causal decoder는 decoder만 있는 구조이지만 Encoder-Decoder와 같이 특정 부분에서는 Encoder와 같이 뒷부분을 참조해서 다음 단어/토큰을 예측하고 이후에는 기존 decoder와 같이 앞 부분만을 참조해서 다음에 올 단어/토큰을 예측하는 거예요. (특정 부분이 아닌 전체적으로 양방향 학습이 가능한건지는 잘 모르겠습니다. 논문에서 해당 구조의 예시로 prefix language model을 들었기 때문에 특정 부분일 것이라고 추측했어요. 어쨋든 prefix language model 얘기가 나왔으니, 이 모델도 간단하게 살펴봅시다.)
*Prefix Language Model: Prefix-tuned Language Model이지 않을까 싶습니다. 2021년 stanford에서 fine-tuning시 연산의 효율성을 높이기 위한 방법으로 고안된 prefix-tuning 기법을 소개했습니다 (Li & Liang, 2021). 사전 학습된 대규모 언어 모델은 freeze한 상태에서 내가 필요한 부분만 학습하자는 취지의 논문입니다. 이때, 모델에 추가적으로 주입하는 정보가 prefix인데 이 prefix 부분이 양방향 학습이 가능하기 때문에 non-causal decoder only 모델에 예시로 설명한게 아닐까 싶습니다.
그러면, 또 다른 궁금증이 생깁니다.
Q2. Non-causal decoder, Encoder-Decoder 모두 양방향 학습이 가능하다면, 둘은 결국 같은게 아닌가?
A2. 양뱡향 학습이 같은 시퀀스 내에서 이뤄지는지, 다른 시퀀스 내에서 이뤄지는지가 이 둘의 가장 큰 차이가 아닐까 싶습니다. Encoder-Decoder 모델에서 양방향 학습이 이뤄지는 부분은 명확히 Encoder 부분입니다. Encoder를 통해서 들어온 input을 해석하는 과정에서 양방향 학습을 진행한 후, 해당 결과를 decoder에 넘겨주는 거죠. 반면, non-causal decoder는 같은 시퀀스 내에서 양방향, 단방향 학습이 모두 이뤄집니다.
Encoder-decoder.
처음 고안된 구조처럼 transformer는 encoder와 decoder로 구성되어 있음. 인코더는 연속적인 토큰들을 input으로 받고 output으로도 같은 길이의 연속적인 토큰을 반환함. 반한된 토큰은 decoder에서 autoregressive (자기회귀)방식을 통해 target 토큰을 예측함. Decoder의 self-attention layer에서는 causal masking pattern을 통해 다음 단어를 예측할 때, 미래의 단어는 모델이 보지 못하도록 마스킹처리를 함. Encoder-Decoder 구조의 모델에는 BART, T5 등이 있음. T5는 T0의 기초 모델 (foundation model)이며, multi-task finetuning을 거쳤을 때, decoder only 모델에 비해 더 높은 성능을 보임.
아주 기본적인 용어이긴 하지만 auto-regressive라는 단어도 살펴봅시다.
Q. Auto-regressive하다는 것이 뭔가요?
A. Auto-regressive를 한국말로 표현하면 자기회귀입니다. 딥러닝에서 회귀모델을 푼다라고 하면 x, y값 같이 주어진 데이터를 바탕으로 최적의 파라미터를 찾는 과정이 될 것 같아요. 이때, 자기회귀란 최적의 파라미터를 찾는 과정에서 자기 자신 역시 주어진 데이터로 본다는 의미입니다. 사실 decoder 모델이 다음 토큰을 예측하는 과정을 생각하면 아주 이해가 쉽습니다. 보통 decoder 모델은 이전 단어들을 기반으로 다음 단어를 예측하곤 하는데 사실 그 이전 단어조차 더 먼저 나온 단어들을 보고 예측된 단어입니다. 이처럼 자기 자신을 계속해서 변수로 삼고 다음을 예측하기 때문에 auto-regressive라는 말이 붙은 것 같네요.
Causal decoder-only.
본래 transformer 구조가 encoder-decoder 기반이긴 했지만, 최근 LLM 모델들은 대부분 decoder-only 모델 구조를 따르고 있음. 이런 모델들의 학습 방식은 전통적인 decoder 모델 학습 방식과 같이 다음 토큰을 예측하는 것임. Decoder-only 구조의 모델들은 입력과 출력을 다르게 두고 있지 않음. 모든 토큰들은 같은 방식으로 작동함. 하지만, causal masking pattern으로 과거 토큰에만 의존해서 다음 토큰을 예측하게 됨. 따라서 한편으로 한쪽만 보고 토큰을 예측하기 때문에 텍스트에 대한 이해도가 낮을 수 있지만, 아주 단순한 구조로 작동하기 때문에 auto-regressice한 환경에 딱 맞아떨어짐. 요즘에 나오는 대부분의 LLM이 해당 구조를 사용하고 있음.
Non-causal decoder-only.
저를 가장 당황시킨 부분이지만 위 그림을 다루면서 자세히 설명했기 때문에 부연 설명하지 않겠습니다. Decoder-only 구조 모델의 약점인 약한 input 정보를 보강하기 위해 attention mask를 살짝 수정하는 것이 제안됨. Input 정보를 받을 때, non-causal mask로 진행. 즉, 이제 더이상 attention이 이전 토큰들에만 국한되지 않는 다는 것임 (뒤도 볼 수 있다!). 때때로, 이를 prefix language model이라고 부름.
Encoder-only.
또 다른 변형 방법으로 BERT와 같이 encoder만 사용하는 모델도 있음. 하지만, 이 모델은 input으로 사용되기 때문에 같은 양의 토큰을 생성하는데는 한계가 있음. 특히, zero-shot setting에는 극히 드물게 사용되기 때문에 본 논문에서는 다루지 않을 것임.
Comparisions across architectures.
Decoder-only 모델은 input과 target text를 한 번에 받는 구조임. 반면에 encoder-decoder의 경우, encoder는 input만 decoder는 target만 취급함. 하지만, 결국 처리하는 토큰의 양은 동일하기 때문에 전반적인 연산량은 비슷할 것임. 하지만, encoder-decoder 모델의 parameter 수를 생각해보면 decoder-only 모델에 비해 2배가 더 많을 것이기 때문에 memory는 parameter 수 만큼 더 사용됨.
2.2 Pretraining objectives
Figure 3가 자세히 설명하고 있기 때문에 다른 설명은 생략하겠습니다. 간단히 full language modeling은 우리가 흔히 알고 있는 causal language modeling (=Next token prediction). Prefix language modeling (PLM)은 full language modeling (FLM)의 변형으로 non-causal training을 하고 싶을 경우, 이를 prefix로 random하게 지정하여 활용 가능하다고 함. Masked language modeling (MLM)은 주로 BERT계열의 encoder-only 모델에서 사용하는 pretraining 기법임.
2.3 Model adaptation
Adaptation은 다른 목적 혹은 구조를 가지고 pretraining을 연장하는 것을 말함. Finetuning과는 다르게 특정 downstream task에 대한 데이터가 사용되지 않고 pretraining 시킬 추가적인 데이터를 사용함. MLM으로 학습된 encoder-decoder 모델인 T5를 PLM 혹은 FLM으로 학습 시킨 것이 여기에 해당됨. Non-causal decoder-only모델을 causal decoder-only 모델로 변환하고 싶다면 간단히 attention mask만 변경하면 됨.
2.4 Multitask finetuning
여기서 의미하는 multitask finetuning은 instruction tuning 혹은 prompt tuning과 같음.
2.5 Zero-shot evaluation
LLM의 zero-shot 능력은 2019년도에 처음 언급됨. 충분한 크기의 언어 모델은 특정 supervised sample 없이 많은 task에서 성능을 낼 수 있다는 것. Zero-shot이 이렇게 각광받는 이유는 어떤 label된 데이터가 필요 없고, 모델을 finetuning 시킬 때 필요한 여러 문제들을 해결함. zero-shot 성능을 평가하기 위해 2가지 주요 benchmarks를 사용함 (Eleuther AI LM Evaluation Harness (EAI-Eval), evaluation set from T0 (T0-Eval)).
* 사실 어떻게 보면 우리가 다른 논문들에서 한 번씩 다 접해봤을 아이디어인데, 실상 논문들마다 각자의 용어로 정의를 내리다보니 용어 사용에 조금 혼동이 오는 것 같습니다.
1 Introduction
Unstructured data에서 pretraining한 LLM들이 다양한 task에서 우수한 성능을 보임. 우리는 이것을 zero-shot generalization이라고 일컷음. Zero-shot generalization은 현실에서 매우 유용한데, downstream task 수행 시 별도의 데이터가 필요하지 않기 때문. 이러한 이유로 LLM의 zero-shot generalization 성능을 높이기 위한 다양한 연구가 진행됨. 최근 연구에 의하면, pretrainng 후 multitask fintuning을 거쳤을 때, zero-shot 성능이 크게 올랐다고 함 (여기서 말하는 multitask finetuning이 곧 instruction tuning이라고 생각함).
기존 LLM들은 구분된 encoder와 decoder를 가진 transformer 기반의 모델이었지만, 최근 LLM들은 대부분 causal decoder-only (CD) 구조를 띄고 있음. 이후 다양한 연구에서 encoder-decoder가 decoder-only보다 성능이 좋다고 밝히거나, decoder-only 모델의 한계를 극복하기 위해 non-causal decoder-only 모델을 사용하는 등의 행보를 보임. 그렇다면 대체 zero-sho generalization에서 어떤 모델이 가장 성능이 좋을지에 대한 궁금증이 생김. 결국, 해당 논문은 어떤 구조를 가진 모델이 어떤 학습을 거쳤을 때, zero-shot generalization에서 가장 높은 성능을 보이는지을 실험한 연구임.
3 Methods
Model architecture, pretraining 기법, multitask finetuning 그리고 adaptation 방법에 따라 얼마나 zero-shot performance에 영향을 미치는지를 확인하기 위해 systematic large-scale study를 진행함. 모든 가능한 구조의 pair를 만들어서 C4 데이터에서 나온 168B 토큰에 학습 시킴.
연산에 들어가는 비용이나 학습 환경은 최대한 동일하게 진행하려고 함 (Google Cloud TPUv4s, T5X, JAZ, and Flax 사용).
3.1 Architecture
모델의 구조는 총 세 가지를 고려함. Causal decoder (CD), encoder-decoder (ED), 그리고 non-causal decoder (ND).
3.2 Pretraining
Pretraining 기법으로는 앞서 언급한 세 가지를 모두 활용했지만, 이것은 모델의 구조에 따라 다르게 적용함. CD의 경우, FLM 혹은 MLM. ND와 ED의 경우, PLM 혹은 MLM 중 하나를 선택함. 모든 모델들은 C4 데이터의 168B 토큰에서 학습됨.
3.3 Multitask finetuning
최근 연구들에 따르면, multitask finetuning이후 zero-shot generalization의 성능이 높아짐을 보임. Multitask finetuning을 진행한 T0나 FLAN 모델은 기본 구조가 다름. T0는 encoder-decoder 구조에 MLM 학습 방식을 진행한 모델이고 FLAN의 경우 decoder-only 구조에 FLM 학습 방식을 진행함. 따라서, 본 연구에서는 어떤 모델을 선택하는게 좋을지를 밝혀내고자 함. 다른 연구와의 차별점은 multitask finetuning 전에 adaptation을 진행하지 않았다는 것. Adaptation이 딱히 성능 향상에 영향을 주지 않아 해당 과정을 빼고 진행함.
3.4 Evaluation
우리 모델을 평가하기 위해 두 가지 zero-shot evaluation benchmarks를 활용함. 하나는 T0를 평가했을 때 사용한 데이터셋과 동일한 데이터셋, 두 번째는 Eleuther AI LM evaluation harness (EAI-Eval)임. T0-Eval이 task마다 여러 개의 prompt를 제공하는 반면, EAI-Eval은 task 별 하나의 prompt만 제공함. 따라서, T0-Eval의 경우 중앙값을 사용하여 정확도를 계산함.
4 Experiments
4.1 After unsupervised pretraining only
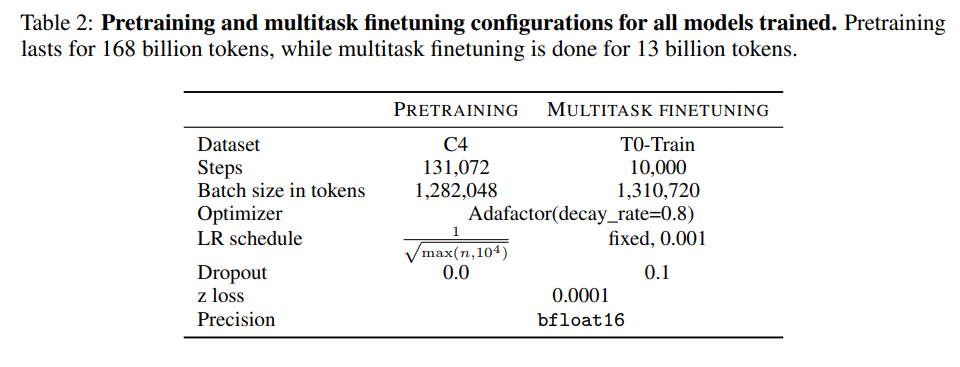
가장 먼저 어떤 구조의, 어떤 pretraining 기법이 zero-shot generalization에 영향을 미치는지 알아봄. MLM의 경우, zero-shot generalization 성능과는 직접적인 관계가 크게 없기 때문에 여기서는 FLM와 PLM만 고려함. 평가 데이터셋에 따르면, causal decoder 모델이 다른 구조에 비해 높은 성능을 보임. Non-causal decoder의 경우, 성능에 많은 차이를 보이지 않았지만, encoder-decoder의 경우, 크게 뒤떨어짐.
Finding 1. Causual decoder-only models pretrained with a full language modeling objective achieve best zero-shot generalization when evaluated immediately after unsupervised pre-training, in line with current common practices for large language models.

4.2 After multitask finetuning
Multitask finetuning을 진행하기 이전의 상태에서는 encoder-decoder 모델이 decoder-only 모델에 비해 성능이 좋지 않음을 4.1에서 확인함. 하지만, multitask finetuning을 진행한 후에는 encoder-decoder 모델이 가장 높은 성능을 자랑함. EAI-Eval 데이터셋에서는 encoder-decoder 모델이 가장 높은 성능을, non-causal decoder 모델이 그 뒤를 따름. T0-Eval에서는 그 차이가 더 두드러짐. Encoder-decoder 모델이 다른 모델들에 비해 훨씬 높은 성능을 보임.
Finding 2. Encoder-decoder models trained with masked language modeling achieve the best zero-shot performance after multitask finetuning. More broadly, approaches that perform well in the single-task finetuning setteing perform well on multitask finetuning.
4.3 Influence of the tasks and prompts used for zero-shot evaluation
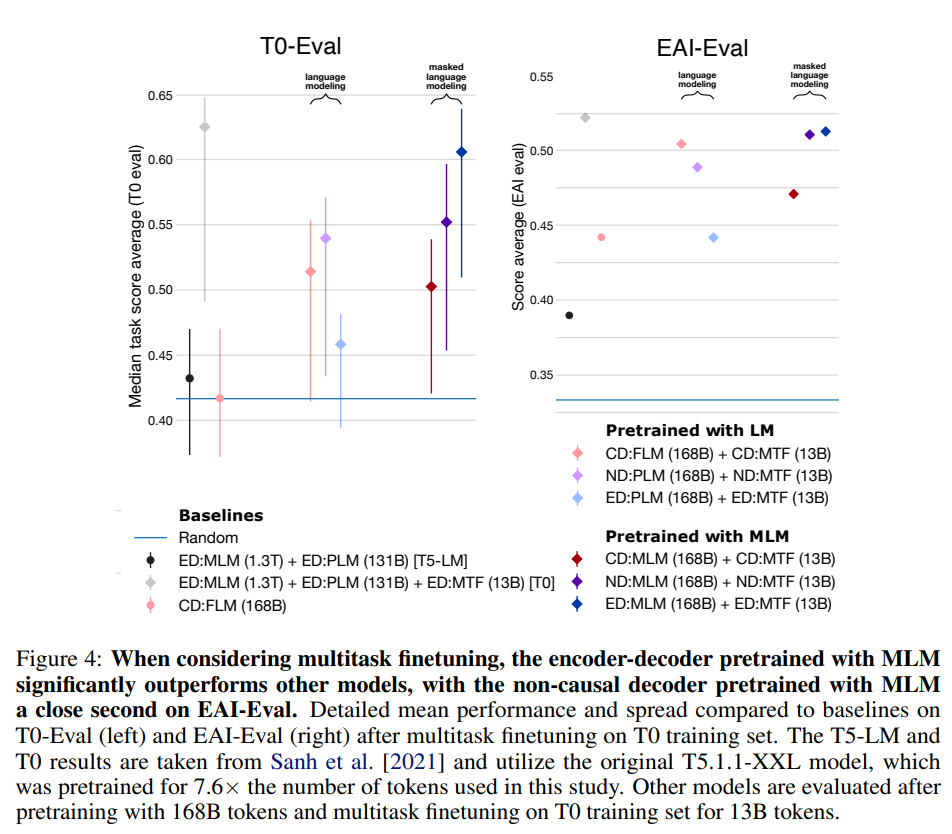
비록 EAI-Eval과 T0-Eval의 task가 많이 겹치지만, 두 데이터셋의 prompt는 다른 형식임 (task 11개 중 10개가 같음). EAI prompt는 GPT-3 모델의 성능을 높이기 위해 직접 작성된 것인 반면, T0-Eval prompt는 모델의 성능을 고려하지 않고 최대한 다양한 task를 할 수 있도록 community에서 가져온 source임. 결과적으로, EAI prompt가 T0에 비해 모든 모델에서 더 높은 성능을 보임 (prompt를 어떻게 구성하느냐에 따라서도 모델 성능 향상에 영향을 미칠 수 있다는 것을 시사하는 것일까?) EAI-Eval과 T0-Eval에서 task가 다른 하나에 대해서도 성능을 검증함. T0-Eval에 포함되지 않은 task에 대해서 causal decoder 모델이 엄청난 성능 향상을 보여줌 (특정 task에 대해서도 특정 구조가 성능이 높아짐을 시사하는 것 같음 → 하지만, 이건 LAMBADA라는 language modeling task이기 때문일 가능성이 큼. 그래도 결국 다른 task에서도 이런 차이를 보이는 task가 존재할 수 있지 않을까?)
5 Can models be adapted from one architecture/objective to another?
연구 결과를 바탕으로 한계점을 찾음. Encoder-decoder 구조의 모델이 finetuning 이후 가장 성능이 좋은 것을 밝혔지만, 이는 사실 효율적이지 못함. Decoder-only 모델 구조가 pretraining만 진행했을 경우, 가장 높은 zero-shot generalization 성능을 보인 것으로 보아 encoder-decoder 구조가 이처럼 multitask finetuning을 진행하지 못했을 경우, decoder-only 구조가 좋은 성능을 보인 다양한 task를 수행하지 못할 가능성이 있기 때문. 그래서 adaptation을 진행하기로 함. Pretraining을 다른 목적, 구조에서 연장해 보는 것임.
Language mdoeling adaptation.
먼저 MLM학습을 진행한 non-causal decoder 모델에 대해 causal decoder 구조의 FLM을 진행함. 모델 구조는 동일하게 두고 attention mask만 변경하는 것이기 때문에 간단함. 하지만, from scratch 부터 진행한 것에 비해 모델의 성능이 나오지 않음.
Non-causal masked language modeling adaptation.
이번엔 반대로 FLM으로 학습된 causal decoder 모델에 non-causal decoder 구조의 MLM 학습을 진행함. 기존 causal decoder 모델에 비해 좋은 성능을 보임. 추가로 아래 세 가지 모델의 성능을 비교 분석함.
1) 219B token - FLM pretraining causal decoder 모델
2) 219B token - FLM pretraining causal decoder 모델 + Multitask finetuning (non-causal decoder)
3) 168B token - FLM pretraining causal decoder 모델 + 51B - MLM adaptation - non-causal 모델 + Multitask finetuning
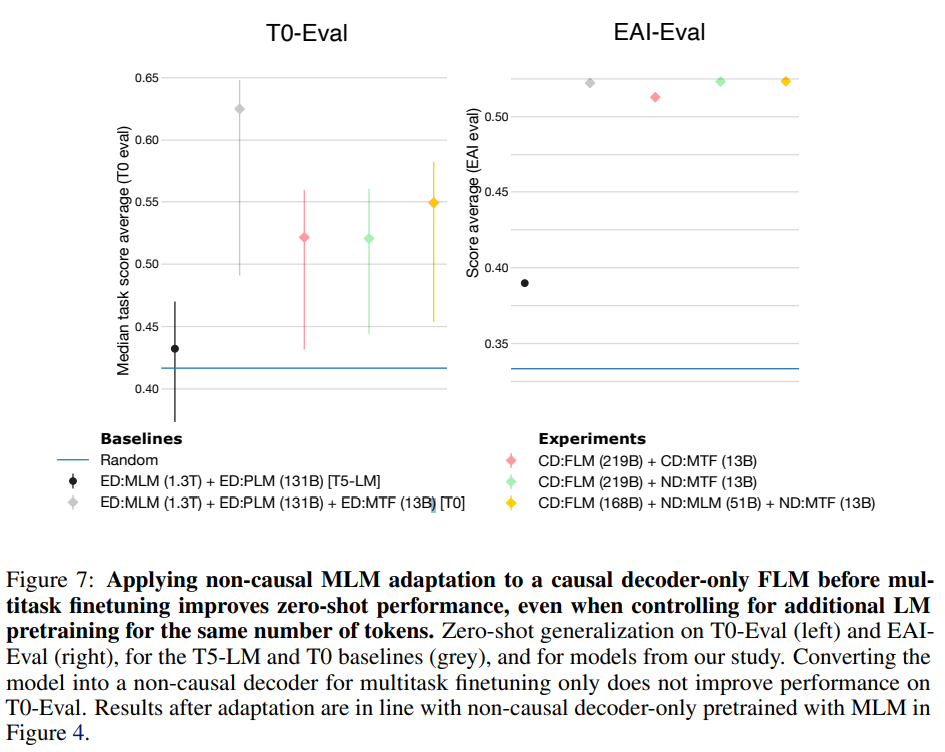
Finding 3. Decoder-only models can be efficiently adapted from one architecture/objective prior to the other. Specifically, to obtain both a generative and a multitask model with the smallest total compute budget possible, we recommend starting with a causal decoder-only model, pretraining it with a full language modeling objective, and then using non-causal masked language modeling adaptation before taking it through multitask finetuning.
6 Conclusion
여러 실험을 진행한 결과, causal decoder-only 모델을 full language modeling을 통해 pretraining한 이후에 non-causal decoder-only 모델과 같이 masked langauge modeling 기법으로 추가 pretraining을 진행할 경우, 가장 빠른 성능 향상을 보임. 해당 논문을 통해 어떻게 LLM 모델을 디자인하는게 좋을지 보임.
논문을 다 읽은 후에도 여전히 몇가지는 오리무중이에요.
특히, Figure 7을 보면 T0-Eval에서는 encoder-decoder 구조의 모델이 앞도적인 성능을 보이는데,
그렇다면 더 general한 task (논문에서 얘기하는 GPT-3에 성능을 올리기 위한 목적이 아닌 대중적인 prompt)에서 오히려 encoder-decoder 모델의 구조가 더 좋은게 아닌가요...??????
물론 computing resource도 무시할 수 없지만, 어떤 환경에서 어떤 데이터로 실험하느냐도 각 모델간 비교에 중요한 과제가 될 것 같은 느낌입니다.
결론은 오늘도 어렵다.
