2024. 9. 26. 09:49ㆍPaper Review/Large Language Model (LLM)
Direct Preference Optimization: Your Language Model is Secretly a Reward Model, Advances in Neural Information Processing Systems (Neurips,'24). Rafailov, R., Sharma, A., Mitchell, E., Manning, C. D., Ermon, S., & Finn, C.
https://arxiv.org/abs/2305.18290
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
While large-scale unsupervised language models (LMs) learn broad world knowledge and some reasoning skills, achieving precise control of their behavior is difficult due to the completely unsupervised nature of their training. Existing methods for gaining s
arxiv.org
* 논문 중간 중간 (파란색글씨)는 논문을 읽고 제가 이해한 것을 바탕으로 작성된 내용입니다. 개인적인 견해이므로 잘못된 내용을 포함할 수 있습니다.
Abstract
대규모 비지도학습 (unsupervised) 기반의 LM (Language Model)들은 폭넓은 지식을 학습했지만, 답변의 미세 조정은 여전히 어려움. 최근 연구들은 강화학습 기법을 기반으로 사람들의 선호도를 모델 Alignment에 이용하는 Reinforcement Learning from Human Feedback (RLHF) 방식을 많이 활용함. 하지만, RLHF 방식은 매우 복잡하고 학습 과정도 안정적이지 못 함. 따라서, 본 논문에서는 간단한 classification loss만을 활용해서 보다 쉽게 RLHF 방식을 적용할 수 있는 새로운 접근법인 Direct Preferecne Optimization (DPO)을 소개함. DPO 기법은 안정적이며, 연산도 효율적임. 실제 실험 결과도 이전 기법들과 비슷하거나 더 좋은 성능을 보임.
Q. LLM (Large Language Model) 모델에 항상 등장하는 Alignment! 그 의미는?
A. Alignment는 LLM이 생성하는 출력이 사람의 선호에 더욱 가깝게 조정하는 방법을 말합니다. 즉, 모델이 우리가 원하는 형태로 답변할 수 있게끔 조정하는 것으로 이해하면 되겠네요.
1. Introduction
대규모 비지도학습 LM들은 아주 큰 규모의 데이터를 기반으로 학습되어 높은 성능을 자랑함. 이런 데이터들 안에는 다양한 목적과 기술들이 포함되어 있는데, 특정 부분에서는 모델이 이를 그대로 표방하지 않기를 바라는 경우가 생김. 예를 들어, 50% 사람들이 잘못 알고 있는 오류적 지식이 있다고 가정하면, 모델이 이를 그대로 믿기보다는 잘못된 지식임을 인지하길 바라는 것임. 즉, 모델이 '어떻게 문제를 수행하고, 어떤 형식으로 답변했으면 좋겠는가'를 결정하는것은 매우 중요한 문제임. 지금까지의 방법론들은 대게 강화학습을 이용함. 저자는 본 논문에서 아주 간단한 binary cross-entropy objective만을 활용하여 강화학습을 이용하는 것을 보여줌.
사람들이 원하는 답변 형식으로 모델을 tuning하는 과정은 대규모의 text 데이터를 기반으로 모델을 pre-training한 이후에 진행됨. 가장 효과적인 방식은 사람 혹은 AI가 직접 답변에 대한 feedback주는 방법으로 RLHF/RLAIF가 있음. 사람들의 선호도를 기반으로 reward 모델을 구축해서 더 높은 보상을 받을 수 있는 (사람들이 더 선호하는 답변을 할 수 있는) 방식으로 모델을 학습시킴. 이렇게 학습시킨 모델은 높은 성능을 자랑하지만, 지도 학습에 비해 더 복잡하고 더 많은 연산을 필요로 함.
따라서, 본 논문에서는 이런 보상 모델이나 강화학습 없이 어떻게 사람의 선호도를 바로 모델에 주입할 수 있는지 보여줌. 그것이 바로 Direct Preference Optimization (DPO) 기법임. RLHF와 같은 목표를 가지고 있지만, 훨씬 적용이 쉽고 직관적임. 모델의 답변에 대한 사람들의 선호도가 반영된 데이터를 기반으로 DPO는 간단한 binary cross entropy objective만을 활용하여 선호도 데이터에 모델을 최적화 시킴.
Sentiment modulatiion, summarization, 그리고 dialogue 등의 task에서는 PPO (Proximal Policy Optimiaztion) 기반의 RLHF에 비해서도 높은 성능을 자랑함.

2. Related Work
자기지도학습 (Self-supervised) LM모델들은 모델의 사이즈를 키워 pre-training단계에서 zero-shot 혹은 few-shot task를 학습함. 하지만, downstream task나 사용자의 목적에 맞게 모델을 alignment하는 과정은 [Instruction-human written completion] 데이터셋을 바탕으로 한 fine-tuning 단계에서 주로 성능 향상이 이루어짐. 이런 'Instruction-tuning' 과정은 LLM 모델들이 Instruction에 대해 일반적으로 잘 작동할 수 있도록 만들어줌. Instruction-tuning 방식이 매우 효과적인 학습 기법이지만, 때론 답변에 대한 사람들의 판단이 훨씬 쉽게 얻어질 수 있음 (전문가의 의견을 받아 Instruction을 구축하는 것보다 사람들의 즉각적인 반응들을 수집하는게 용이할 수 있음). 따라서, 이 선호도를 기반으로 모델을 fine-tuning 하면 효과적일 수 있음. 선호도에 따른 최적화 방식은 아래와 같음.
1) Bradely-Terry model과 같은 선호도 모델을 기반으로 보상 함수를 최적화함.
2) 강화학습 기법을 활용하여 주어진 보상을 최대화 할 수 있도록 모델을 학습함.
사람들의 선호도를 바탕으로 모델을 학습하는 것은 매우 매력적인 일이지만, 여전히 강화학습을 통해 대규모의 언어 모델을 학습하는데는 많은 어려움이 따름. 따라서, 본 논문에서는 사람의 선호도를 강화학습 기법 없이 학습하는 방안에 대해서 고안함.
언어 맥락을 벗어나서도 선호도 기반의 학습 방식은 연구되어 옴. 그 중 하나는 'Contextual bandit learning'임. Contextual bandit learning은 보상이라는 개념보다는 선호, 행동의 우선 순위를 사용함. 절대적인 보상 대신 von Neumann winner 개념을 활용 - 다른 정책에 대해 예상 승률이 최소 50%인 정책. 비슷하게 preferance-based RL (PbRL)도 보상보다는 알려지지 않은 scoring 함수에 따른 binary 선호도를 기반으로 학습함. 하지만, 이 방법 역시도 잠재적인 점수 함수 (보상 함수와 같은)를 추정한 후, 이를 최적화하는 과정을 포함함.
★선행 연구를 요약하자면, 언어 모델을 떠나서 또는 포함해서 선호도를 바탕으로 학습하는 여러 기법들이 있지만 이전의 기법들은 본 논문에서 소개하는 DPO 학습 기법과 비교하면 복잡하거나 많은 연산이 필요함. DPO가 훨씬 효율적인 학습 기법임!
Q. Bradely-Terry model은 뭔가요?
A. Bradely-Terry model을 검색하면, 응답자의 두 아이템 간의 선호도를 설명하기 위하여 제안된 모델이라는 설명이 나옵니다. Bradely-Terry model을 활용하여 응답자가 어떤 답변을 더 선호하는지, 그 확률값을 계산해볼 수 있는 것으로 이해했습니다
3. Preliminaries
DPO 소개에 앞서 RLHF 학습 기법에 대해서 살펴보자.
RLHF는 다음과 같은 3가지 단계를 거쳐 학습함.
1) Supervised fine-tuning (SFT)
- RLHF 모델은 기본적으로 pre-trained LM 모델에 downstream task를 수행할 수 있는 질 좋은 데이터를 바탕으로 지도 학습을 진행 함. SFT된 모델을 얻기 위한 과정.
2) Reward Modelling (RM)
- 얻어진 SFT 모델을 기반으로 답변 pair를 생성함. 이런 답변들은 human labelers에게 보여주고 선호되는 하나의 답변을 선택하도록 함. 이런 선호도는 어떠한 보상 모델 (reward model; rm)을 통해 생성된 것으로 가정. 선호도 모델에는 여러 가지 접근법이 있고 그 중 하나가 Bradly-Terry model. (결국 2번째 단계에서는 사람의 선호도를 바탕으로 보상 모델을 학습한다고 생각하면 됨.)
3) RL fine-tuning / optimization
- 강화학습 단계에서는, 학습된 보상 모델이 언어 모델에게 feedback을 제공함. (즉, 언어 모델이 생성한 답변이 보상 모델로 부터 얼마나 좋은 평가를 받는지 확인할 수 있음.) 강화학습 단계에서는 PPO 알고리즘이 적용됨. 이는 모델이 보상을 극대화하는 쪽으로 학습하는 동시에 너무 보상 모델의 결과에만 치중되어 답변이 질이 떨어지는 것을 방지하기 위해 SFT모델의 출력도 어느 정도 유지하도록 하는 방식임.
4. Direct Preference Optimization
대규모 데이터에 강화학습을 적용하는 것에 대한 어려움을 해결하고자 본 연구의 목표는 간단한 방식으로 선호도를 직접적으로 반영할 수 있는 정책 최적한 방식을 탐색함. 이전의 RLHF 방법론 (보상 모델을 학습하고 강화학습을 통해 이를 최적화하는)과 달리 DPO는 강화학습 없이 최적화 정책을 도출함. 이를 통해 강화학습에서 보상 함수를 따로 최적화하지 않고, 보상 함수를 손실 함수로 변환함으로써 최적 정책을 도출하는 것이 가능해짐.
이제 이를 수식적으로 이해해봅시다. (이 부분은 저도 너무 어렵네요.)
Deriving the DPO objective.
신기하게도 RL의 objective를 변경하면 최종적으로 아래와 같은 DPO의 objective인 DPO 손실함수를 도출할 수 있음.
이때, Bradely-Terry model을 활용하기 때문에 보상 모델이 아닌 손실함수임에도 사람의 선호도를 반영하는 것을 알 수 있음.

- π_θ: 업데이트 모델
- π_ref: 참조 모델 (기준이 되는 모델) = SFT 모델
- y_w : y_win으로 모델의 답변 중에서 승리한, 즉 선택된 답변으로 선호되는 답변을 의미.
- y_l : y_lose으로 모델의 답변 중에서 실패한, 즉 선택되지 않은 답변으로 비 선호되는 답변을 의미.
이 수식은 선호된 답변의 확률을 높이고, 선호되지 않은 답변의 확률을 낮추는 방향으로 정책을 최적화 함.
What does the DPO update to?
DPO를 잘 이해하기 위해서 DPO 손실함수가 어떻게 gradient를 최적화시키는지 아는 것이 좋음.
일반적인 loss function과 gradient descent의 원리를 잘 알면 이해하는데 조금 도움이 되지 않을까 싶습니다.

여기서는 간략하게 언급하고 5장에서 각각의 의미를 조금 더 자세히 다루기로함.

* 저는 이 식에서 가장 혼동이 많이 왔습니다. 분명 DPO는 RLHF모델과 달리 보상 모델을 사용하지 않는데, 수식을 살펴보면 r θ (reward)와 같은 보상 모델이 표기되어 있습니다. 이는 DPO에서 보상이라는 방식을 '명시적'으로 활용하지 않지만 '암묵적'으로 (모델 내부 프로세스에서) 활용하고 있기 때문이라고 이해하였습니다.
- π_θ (y|x): 현재 언어 모델이 주어진 입력 x에 대해 출력 y를 생성할 확률
- π_ref (y|x): 참조 모델 (SFT model)이 동일한 입력 x에 대해 출력 y를 생성할 확률
즉, 위 DPO 수식에서 나타나는 보상 함수는 언어 모델과 참조 모델 간의 출력 확률 비율을 기반으로 보상처럼 작동하는 것.
Q. 그렇다면 그라디언트는 어떻게 계산될까요? 손실 함수는 어떻게 작용할까요?
A. log확률 값을 보면 선호 답변 (y_w)의 확률을 증가 시키고, 반대로 선호되지 않은 답변 ( y_l )의 확률을 낮추는 방식으로 업데이트가 이루어짐 (모델이 선호하는 쪽으로 답변할 수 있게 하기 위함이라고 이해). 추가로 수식 앞쪽에 위치한 시그모이드 함수에 의하여 보상 함수가 답변을 얼마나 잘 판단했는지에 따라 가중치가 부여됨. 만약, 보상 모델이 답변을 잘못 판단하고 있다면, 해당 예시가 가중치를 크게 받아, 모델업데이트가 더 많이 일어나게 되는 것.
결국, 여기까지 요약하자면 DPO 수식에 나타나는 보상 모델은 해당 모델이 답변에 대해서 얼마나 잘 판단하고 있는가를 확인하기 위한 함수 같음. 판단을 잘 해야지만 선호하는 답변과 비 선호하는 답변에 대해 정확한 확률값 계산이 이뤄지지 않을까?
DPO outline.
일반적인 DPO는 아래와 같은 pipeline을 따름.
1) 모든 프롬프트 x (=질문이라고 생각)에 대해 사람의 선호도가 반영된 offline dataset D = {x, y_w, y_l}
(여기서 offline dataset인 이유는 이미 만들어진 데이터셋이라고 생각하고, 각 질문에 대해 두 가지 답변이 존재하며, 하나는 선택된 응답 (즉, 사람이 선호하는 답변) 나머지 하나는 선택되지 않은 답변 (즉, 사람이 선호하지 않는 답변)으로 구성된 데이터셋임.)
2) π_θ (언어모델 - 우리가 최종적으로 만들고자 하는 모델)을 참조 모델 π_ref (앞서 Instruntion-tuning 등 Supervised Finetuned된 모델)에 대해 DPO 손실함수를 최소화하는 방식으로 최적화
(여기서 참조모델이 SFT모델인 이유는 우리는 새로운 데이터셋을 구축하기보다 이전 모델에 대해 선호도가 표기된 데이터셋을 활용하는 것을 원함. 이때, 데이터셋의 답변을 생성한 모델이 SFT모델이기 때문에 이를 참조 모델로 하는 것)
5. Theoretical Analysis of DPO
5장은 4장에서 언급한 DPO에 대해 이론적 배경, 조금 더 깊은 해석을 동반함.
한마디로 증명의 과정임. 쓰여진 그대로 읽어도 ? ?? ?????????? 하기 때문에 제가 이해한 것을 토대로 설명하겠습니다.
5.1 Your Language Model Is Secretely a Reward Model
DPO는 maximum likelihood 방법만을 사용해서 명시적인 보상 모델을 사용하는 것도, 아주 복잡한 강화학습 과정을 진행하는 것도 우회할 수 있음. 이를 증명하기 위해서 equivalence 라는 정의와 몇 가지 명제가 나옴 .
Definition1. 두 보상 함수가 어떤 함수의 차이로 표현될 수 있다면 두 보상 함수를 우리는 동등한 클래스에 속한다고 할 수 있음 (equivalence class).
Lemma1. Plackett-Luce나 Bradley-Terry 모델의 선호 프레임워크에서, 동등 클래스에 속하는 두 보상함수는 동일한 선호 분포를 생성.
Lemma2. 동등 클래스에 속하는 두 보상 함수는 RL 문제에서 동일한 최적 정책을 유도.
THeorem1. 보상 함수의 재매개변수화.
결국 이 모든 것은 우리가 RLHF에서 사용했던 보상 함수, 또 강화학습 방식을 DPO로 넘어오면서 단순화하는 작업이 필요하기 때문. 기능은 유지되면서 수식만 간단해지는 것을 설명하기 위한 과정이라고 생각함.
5.2 Instability of Actor-Critic Algorithms
PPO와 같은 표준 actor-critic 알고리즘에서 발생하는 불안정성은 주로 정책 그래디언트의 높은 분산 때문임 (KL divergence라는 개념을 여기서 이해해야 하는 것 같음). 그래서 우리는 정규화항을 이용하여 학습에 안정성을 높이려고하는데, DPO의 경우 추가적인 기준 없이도 자동으로 보상을 정규화할 수 있기 때문에 학습의 안정성을 높일 수 있는것.
6. Experiments
이번 장에서는 실제로 DPO가 선호도를 기반으로 얼마나 잘 정책을 학습하는지 검증함. 먼저, PPO와 같은 다른 선호도 알고리즘에 비해 얼마나 잘 DPO가 보상을 최대화하고 동시에 KL-divergence를 최소화하는지 확인 함. 다음으로는 더 큰 모델에서, RLHF와 같은 학습 기법과 비교해도 성능이 좋은지 검증함. 결과적으로, 기본적인 PPO 알고리즘에에 비해 더 좋은 성능을 보임.
아래와 같이 총 세 가지 task를 진행하여 DPO 학습을 위해 모두 D = {x, y_w, y_l} 형태의 데이터셋을 사용함.
Task1. Sentiment generation
- 여기서 x는 IMDb dataset에서 영화의 앞 부분을 가져옴. 정책은 반드시 긍정적인 감정으로 문장을 생성해야 함. 선호도 데이터셋을 생성하기 위해 sentiment classifier를 활용해 더 높은 긍정 감정을 가진 답변을 y_w, 낮은 긍정 감정을 가진 답변을 y_l로 설정함. 참조 모델로는 GPT-2 모델을 fine-tuning하여 사용함.
Task2. Summarization
- x는 Reddit의 post를 사용함. 정책은 이를 잘 요약해야 함. 선호도 데이터는 이전에 만들어진 데이터가 있으므로 그걸 사용함 (Stiennon et al.).
Task3. Single-turn dialogue
- x는 사람의 질문이고 정책은 해당 질문에 대해 도움이 되는 답변이어야 함. Anthropic Helpful and Harmless dialogue dataset을 사용. 170K개의 대화로 구성된 데이터셋. SFT 모델 사용이 어려웠기 때문에 선호되는 답변만을 활용하여 fine-tuning한 모델을 활용함.
Evaluation
DPO의 성능에 대한 평가는 두 가지 방식을 사용함. → 각 task마다 환경이 다르기 때문에 (보상 함수의 작동원리를 알 때와 모를 때로 나뉨)
1) frontier of achieved reward and KL-divergence
frontier라는 값을 통해 모델이 얼마나 보상을 잘 최대화하고 동시에 KL발산을 최소화하는지를 평가함. Task1을 해당 방식을 활용하여 평가할 수 있는데 이는 우리가 보상 함수가 어떻게 작용하는지 실험 특성상 알고 있기 때문 (감정 분류기를 바탕으로 긍정 감정이 더 높은 것을 택하는 방식).
2) win rate
하지만, 대부분 실제 환경에서는 보상 함수가 어떻게 작동하는지 알 수 없는 경우가 많음. Task 2 & 3이 여기에 해당함. 따라서, 각 알고리즘이 기준 정책과 비교하여 얼마나 승리하는지 승률을 평가 지표로 사용함. 이때, GPT-4를 사람을 대신하여 평가자로 활용함. 실제 GPT-4는 사람이 답변을 고르는 것과 매우 높은 일치도를 보였음.
6.1 How well can DPO optimize the RLHF objective?
일반적인 RLHF에서 KL-constrained reward maximization 목표는 reward와 reference policy 사이에서 적절한 balance를 잡는 것. 즉, 모델을 학습할 때, reward를 최대화하는 것과 동시에 KL discrepancy도 함께 고려해야 함. 보상을 최대화하더라도 KL discrepency가 증가한다면, 이건 좋은 상황이 아닌 것. Figure2를 보면 다른 학습 기법에 비해 DPO가 낮은 KL값에 높은 reward를 유지하는 것을 볼 수 있음. 잘 학습하고 있다는 것을 뜻함.
(이때, Sentiment Generation에 대한 결과만 해당 그래프로 표현되어 있는 것은 앞서 말한대로 reward & KL 값 계산이 해당 task에서만 가능했기 때문)
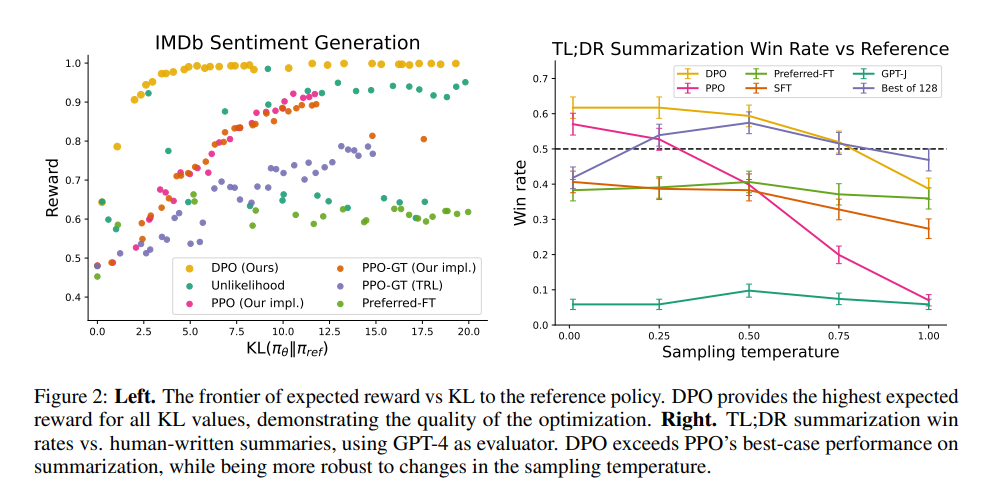
6.2 Can DPO scale to real preference datasets?
다음으로는 요약 (summarization)과 단일-턴 대화 (single-turn dialogue) task에서의 DPO 성능을 평가해 봄. 보통 요약 task에서는 ROUGE 스코어를 많이 활용하는데, ROUGE 스코어는 사람의 선호도와 다른 경우가 많음 (ROUGE 스코어는 요약의 결과가 토큰 기준으로 얼마나 똑같은지를 비교하기 때문에 문맥에 대한 이해도를 평가하지 못함). 그래서, test 데이터셋에서 sample 답변을 추출한 후, 각 모델의 답변과 비교하여 승률이 얼마나 되는지를 측정 지표로 삼음. Single-turn dialogue task도 비슷한 방식으로 진행함. 최종 평가는 사람 대신 GPT-4가 진행함.
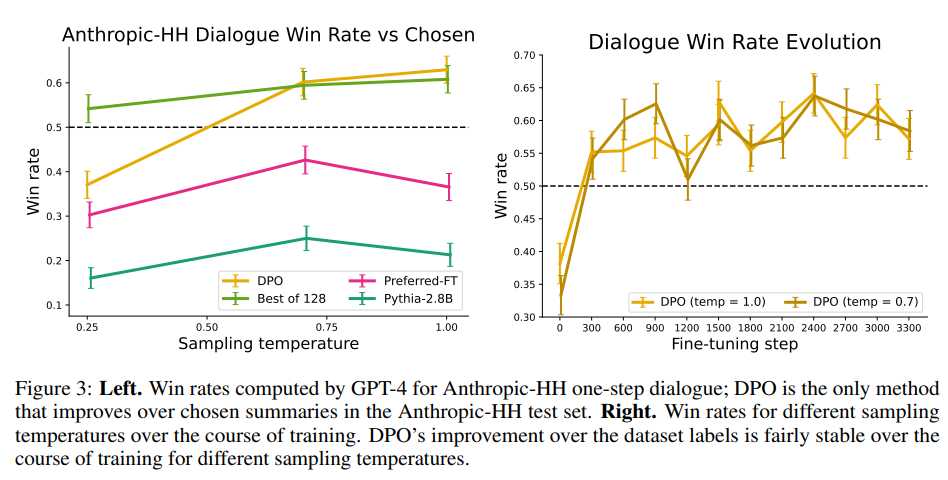
6.3 Generalization to a new input distribution
DPO가 일반적으로 성능이 잘 나오지 확인하기 위해 다른 분포를 가진 데이터를 활용하여 추가 실험을 진행함. 따라서, Reddit 데이터가 아닌 CNN/DailyMail과 같은 뉴스 기사를 활용함. 다른 분포의 데이터에서도 DPO가 PPO 방식에 비해 더 높은 성능을 자랑함.
6.4 Validating GPT-4 Judgements with human judgments
GPT-4를 답변의 평가자로 활용하고 있기 때문에 실제 GPT-4가 답변의 평가자로 적절한지 추가 실험을 진행함. GPT prompt를 2가지 버전으로 작성하여 사람 평가자와 비교해 봄. GPT-4 (S)는 simple한 prompt를 의미하고, 여기서는 단순히 GPT에게 두 답변을 보여주고 더 나은 답변을 선택하도록 함 (요약의 경우, 두 가지 요약 답변, dialogue의 경우, 두 가지 답변). GPT-4 (C)는 concise의 의미로 두 가지 답변 중 어떤 것이 더 간결하냐 (단순히 짧은 것을 의미하는 것은 아님. 내용이 다 들어가면서도 간결하게 답변하는 것을 말함)를 물어봄. GPT-4 (S)의 경우, GPT가 일반적으로 더 긴 답변을 선호하는 경향이 있었기 때문에 이를 방지하기 위한 prompt였음. 결과적으로 GPT-4 (C)가 사람 평가자와 조금 더 비슷하게 평가하는 경향이 있었음. 이 결과를 바탕으로, GPT-4가 사람 평가자를 대신하여 평가할 수 있다는 것을 증명해 냄.
저를 늪으로 빠트린 KL-divergence에 대해서도 한 번 더 알아보도록 합시다!
Q1. Kullback-Leibler divergence (KL-Divergence)?
정보 이론에서 등장하는 KL-divergence의 이론적인 의미는 두 분포의 유사도를 계산하는 방식이다. 즉, KL-divergence의 값이 작을 수록 두 분포가 유사하고, 값이 클 수록 두 분포가 유사하지 않은 것을 의미한다.
Q2. 그렇다면 대체 이 개념이 LLM 모델을 학습하는 과정, 그 중에서도 강화학습 과정에서 왜 계속 등장하는 것일까?
본 논문에서도 계속해서 reward를 maximize하면서 KL-divergence는 minimize할 수 있도록 학습하는 것을 강조하고 있다. KL-divergence가 최소가 되어야한다는 것은 곧 우리가 만들고자 하는 최종 언어 모델 π_θ가 우리가 참조하는 모델 π_ref와 답변 분포가 크게 다르지 않아야 한다는 것처럼 느껴지는데, 학습을 시키는데 왜 분포가 달라지면 안될까? 생각하게 된다.
논문을 벗어나 몇가지 이유를 찾아보았다.
1. 기존 모델과의 차이를 제어하기 위함.
우리는 현재 pretrained 모델에 사람의 선호도를 집어 넣는 과정을 수행하고 있다. 하지만, 만약 선호도만 위주로 계속 학습을 진행해서 이전 모델의 답변 성능을 잃어버리게 된다면? 오히려 답변의 성능을 떨어트릴 수 있다. 따라서, 기존 모델이 가지고 있는 언어적 지식을 파괴하지 않는 선에서 (보존하면서) 스타일만 우리가 원하는 형식으로 학습 시키기 위해서 KL-divergence를 최소화하도록 학습하는 것이다.
2. 학습의 안정성을 위함.
이 이유는 본 논문에서도 여러번 언급이 되었다. KL-divergence가 지나치게 커지면 모델 학습이 불안정해질 수 있다. 보상 모델이 잘못 설계된 경우, 모델이 지나치게 파라미터를 업데이트하거나하면서 과적합이 발생할 수도 있는 문제. 이런걸 방지하기 위해 KL-divergence를 최소화한다.
종합해보자면, KL-divergence를 최소함함으로써 우리는 모델이 새로운 정보 (우리가 선호하는 답변 스타일)를 받아들이는데 있어서 보다 안정적으로 학습할 수 있게 돕고, 그 방향 역시 기존 모델이 가지고 있는 지식을 해치지 않는 선에서 효율적으로 학습할 수 있도록 돕는 것이다.
7. Discussion
선호를 기반으로 한 학습은 모델을 alignment하는데 있어서 굉장히 효과적인 방법론임. 본 논문에서는 강화학습 없이, 간단하게 이를 수행할 수 있는 DPO를 소개함. DPO는 언어 모델 정책과 보상 함수를 매핑해서 cross-entropy loss값을 바탕으로 언어 모델이 직접 사람의 선호도를 학습할 수 있도록 함. Hyperparameter tuning 없이, DPO는 RLHF 알고리즘과 비슷하거나 더 높은 성능을 보였음. 따라서, DPO는 더 많은 언어 모델들이 사람의 선호도를 학습 시키는 데 기여할 수 있음.
간단한 아이디어라도 아이디어를 수학적으로 풀어나가는 것은 정말 어렵네요.
그것을 이해하는 것 조차 정말 어려운 것 같습니다.
나만 못해, DPO
