2024. 10. 14. 10:57ㆍPaper Review/Large Language Model (LLM)
Zhiqiang Hu, Lei Wang, Yihuai Lan, Wanyu Xu, Ee-Peng Lim, Lidong Bing, Xing Xu, Soujanya Poria, and Roy Lee. 2023. LLM-Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 5254–5276, Singapore. Association for Computational Linguistics.
https://arxiv.org/abs/2304.01933
LLM-Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models
The success of large language models (LLMs), like GPT-4 and ChatGPT, has led to the development of numerous cost-effective and accessible alternatives that are created by finetuning open-access LLMs with task-specific data (e.g., ChatDoctor) or instruction
arxiv.org
모델 학습 전에 알아야 할 배경지식이 너무 많아요..
산 ^ 넘어 ^ 산
그래도 모르고 쓸 수 없어서 읽어봅니다.
Abstract
GPT-4, ChatGPT와 같은 대규모 언어 모델 (LLM)의 성공은 해당 모델을 대체할 수 있는 open-access LLM의 발전을 이끌음. Open-access LLM을 fine-tuning 시킬 수 있는 여러 방법 중 단연 인기있는 주제는 adapter-based parameter-efficient fine-tunging (PEFT)임. 적은 소스로 매우 좋은 성능을 보이기 때문. 따라서, 본 논문에서는 LLM에 적용해볼 수 있는 PEFT 기법을 소개하고, 어떤 task에 어떤 PEFT 기법이 적절한지 소개함. Open-access LLM으로는 LLaMA, BLOOM, GPT-J 등을 활용하고, PEFT 기법으로는 Series adapter, Parallel adapter, Prompt-based learning, 그리고 Reparametrization-based method를 소개함. 14개의 서로 다른 데이터셋에 해당 모델 및 PEFT 방법을 적용해보고 결과를 분석함. 결과, 7B 정도의 작은 크기의 LLM에 adapter-based PEFT를 적용한 결과 매우 높은 성능을 자랑함.
이번에도 낯선 용어들이 많이 등장하기 때문에 Intoduction 이전에 Section 2. PEFT Overview를 먼저 살펴보고 가면 좋을 것 같습니다.
Parameter Efficient Fine Tuning (PEFT) 팹프트!에 대해서 알아봅시다!
Q. PEFT?
A. PEFT란, 말 그대로 LLM을 Fine-tuning하는 기법 중 하나로 LLM을 조금 효율적으로 학습시키기 위해 파라미터를 조정하는 방식을 의미합니다. 보통 우리가 크기가 작은 모델을 학습시킬 때는 우리의 데이터 혹은 테스크에 맞춰 Full Fine Tuning (FFT)를 진행합니다. 모델이 작다면 모든 weight를 다 update하더라도 크게 힘들지 않기 때문이에요. 하지만 크기가 최소 1B에서 많게는 400B을 넘나드는 LLM 모델을 FFT한다고 가정하면, 정말 어마어마한 resource가 들게 됩니다. 따라서, 효율적으로 parameter를 업데이트 해보자!해서 나온게 바로 이 PEFT입니다.
Q. Adapter-based? Non-Adapter-based??
A. 본 논문 abstract에서부터 등장하는 adapter 기반의 PEFT! 그렇다면 adapter 기반이 아닌것도 있나요? PEFT를 크게 Adapter-based, Non-Adapter-based로 나누는지는 모르겠지만, 두 가지 방법 모두 존재합니다. 각 방법의 자세한 설명은 Section 2에서 할 것이기 때문에 가볍게 언급만하고 넘어갈게요. 먼저 Adapter-based 말 그대로 adapter를 적용해서 학습하자!하는 기법입니다. LLM 모델을 학습할 때 필요한 부분에 Adapter를 넣어 해당 부분에서만 parameter가 업데이트 될 수 있도록 하는 방법이에요. 그렇다면, 반대로 Non-Adapter based는 adapter를 사용하지 않습니다. 대표적인 에시로는 prefix-tunging, prompt-tuning 등이 있어요. 두 학습 방식의 가장 큰 차이라면, adapter-based의 경우, 기존 모델의 파라미터를 조정하지만, non-adapter-based의 경우는 기존 모델은 전혀 건들지 않는다는 것이에요.
2 PEFT Overview

본 장에서는 4가지의 parameter-efficient fine-tuning (PEFT)에 대해서 소개함.
*각 Adapter의 내용을 작동 방식 위주로 축약해서 작성하였지만, 논문에서는 각 방식의 대표적 방법론에 대해서도 언급하고 있으므로, 추가적으로 어떤 방법들이 있는지 궁금할 경우, 논문을 확인하시기를 바랍니다.
Prompt-based learning.
Prompt-based learning의 대표적인 예시는 Prefix-tuning. 그래서 앞으로 본문에서는 Prefix-tuning을 이용하여 실험을 진행함. Prefix-tuning은 모든 레이어의 히든 상태에 소프트 프롬프트를 추가하는 방식. Intrinsic prompt-tuning은 프롬프트를 오토인코더로 압축 및 복원하는 방식임.
Reparametrization-based method.
네트워크의 가중치 행렬을 저랭크 (저차원) 행렬로 분해하여 학습해야 할 모델 파라미터 수를 줄이는 방법. Intrinsic SAID, LoRA, KronA 방식 등이 대표적으로 있지만, 본 논문에서는 그 중에서도 LoRA를 대표 방법으로 사용함. LoRA는 가중치를 두 개의 저랭크 행렬로 분해하는 방식임. 여기서 저랭크의 차원을 결정하는 r이 매우 중요한 변수임.
Series Adapter.
하위 레이어에 학습 가능한 모듈 즉, adapter를 순차적으로 추가하여 학습하는 기법. 해당 방식은 모델의 성능은 유지하면서 학습 파라미터 수만 효과적으로 줄이는 것을 목표로 함. 학습 파라미터 수를 효과적으로 줄이기 위해 저차원 프로젝션을 사용함.
Parallel Adapter.
Series Adapter가 순차적으로 모듈을 더했다면, paraellel 기법은 이를 병렬적으로 처리하는 방식. 병렬 adapter의 출력을 기존 출력에 더하는 방식으로 작동함.
1 Introduction
ChatGPT, GPT-4와 같은 대규모 언어 모델은 다양한 NLP 테스크에서 높은 성능을 자랑함. 이런 LLM 모델의 발달은 LLaMA와 같은 오픈소스 언어 모델의 개발을 부추김. 사람들은 테스크 특화 데이터 혹은 Instructional 데이터를 바탕으로 오픈소스 LLM 모델들을 fine-tuning 시킴. 이때, full-model fine-tuning (FFT)을 하게되면 너무 많은 자원이 소요되기 때문에 조금 더 현실적인 방안에 대한 모색이 이루어짐.
LLM에 대한 FFT가 나오기 이전에 parameter-efficient fine-tuning (PEFT) 기법이 pret-trained 모델 (BERT)에 적용되기 시작함. 이 PEFT 기법은 LLM fine-tuning에 좋은 접근을 가능하게 함. PEFT 방식을 활용하면, 모든 parameter를 학습시키지 않고 적은 paratmeter만 학습시키면서 FFT와 비슷한 혹은 더 좋은 결과를 낼 수 있음. PEFT은 이런 장점은 다양한 형식의 PEFT 모듈의 개발을 불러옴 (Table 1).

이렇게 많은 PEFT 모듈이 개발됐음에도, 어떤 PEFT 모듈이 어떤 layer, 어떤 hyperparameter configuration을 통해야 주어진 테스크 혹은 데이터셋에 가장 적합한지에 대한 실험이 이뤄지지 않음. 따라서, 각 테스크와 데이터셋에 맞는 가장 적합한 PEFT 방식을 찾는 것이 중요함. 본 논문에서는 세 개의 오픈소스 LLM (BLOON, GPT-J, LLaMA)을 활용하여 해당 실험을 진행함. 결과는 아래와 같음.
- Series Adapter의 경우, MLP 레이어 뒤에, Parallel Adapter의 경우, MLP 레이어와 병렬적으로, 마지막으로 LoRA의 경우 Multi-head attention 레이어와 MLP 레이어 뒤에 위치했을 때 좋은 성능을 보임.
- PEFT를 활용한 smaller LLM 모데들이 특정 테스크에서 더 좋은 성능을 보임 (예. LoRA를 활용해서 학습시킨 LLaMA-13B가 GPT-3.5 (175B)보다 MultiArith, AddSub, SingleEq 테스크에서 더 좋은 성능을 보임).
- ID (In-Distribution) 데이터로 학습시킨 LLaMA-13B가 ChatGPT 보다 더 좋은 성능을 보임.
3 Experiment Setup
3.1 Benchmarks
2가지 형태의 추론 테스크 성능을 평가하기 위해 14개의 데이터셋을 사용함.
1) Arithmetic Reasoning (산술 추론) - GSM8K, SVAMP, MultiArith, AddSub, AQuA, SingleEq
2) Commonsense Reasoning (상식 추론) - BoolQ, PIQA, SIQA, HellaSwag, WinoGrande, ARC-c, ARC-e, OBQA

3.2 Fine-tuning Data Collection
Adapter 위에 fine-tuning을 진행하기 위해서 각 테스크 (math reasoning & commonsense reasoning)에 맞는 높은 품질의 데이터셋이 필요함. 사전에 구축된 open-source 데이터셋은 방정식과 같은 수학 문제에 치중되어 있기 때문에 조금 더 수학적 추론이 가능한 데이터셋을 구축하기 위해 ChatGPT를 teacher model로 활용함. ChatGPT를 활용하여 10K의 Math10K 데이터셋을 구축함. Commonsense reasoning의 경우, 앞서 소개한 8가지 데이터셋을 결합하여 제작함. 총 170K개의 규모를 가진 Commonsense 170K를 구축함.
3.3 Implementations
PEFT 방식을 보다 효율적으로 활용할 수 있도록 사용자 친화적인 프레임워크 - LLM-Adpater -를 개발함. 이를 통해 LLM 모델에 여러 PEFT 방식을 손쉽게 적용해볼 수 있음. 본 실험에서는 LLaMA (7B, 13B), BLOOMz (7B), GPT-J (6B)를 기반으로 함. PEFT는 Prefix-tuning, Series Adapter, LoRA, Parallel Adapter를 대표적으로 선택함. Batch 사이즈는 16으로 epoch은 3, 학습률은 Prefix-tuning의 경우, 3e-4, 나머지 세 PEFT방식에 대해서는 3e-2로 설정함. 하나의 모델을 math 혹은 commonsense reasoning task에 학습 후 관련된 모든 데이터셋에 대하여 성능을 평가함.
4 Experiment Results
4.1 Placement and Configuration
"What is the optimal placement and configuration?"에 대한 답을 찾기 위해 LLaMA-7B 모델을 기본 모델로 잡고 서로 다른 adapter에 대해서 math reasoning 테스크에 대한 평가를 진행함. 가장 먼저 각 adpater가 어디에 위치했을 때 가장 좋은 성능을 보이는지 평가함. 4가지 adapter 중에서 Prefix-tuning의 경우, 위치가 고정적이기 때문에 제외하고 실험함. 나머지 세 adapter에 대해서는 multi-head attention layer 뒤에, MLP layer 뒤에, 혹은 둘 다 뒤에 이렇게 세 가지 option을 기준으로 평가를 진행함.

Series adapter와 Parallel adapter의 경우, MLP 레이어 뒤에 적용했을 때, LoRA의 경우, Attn과 MLP 모두에 적용했을 때 가장 좋은 성능을 보임 (각 데이터셋에 따른 보다 자세한 결과는 아래 숨은 글 확인).
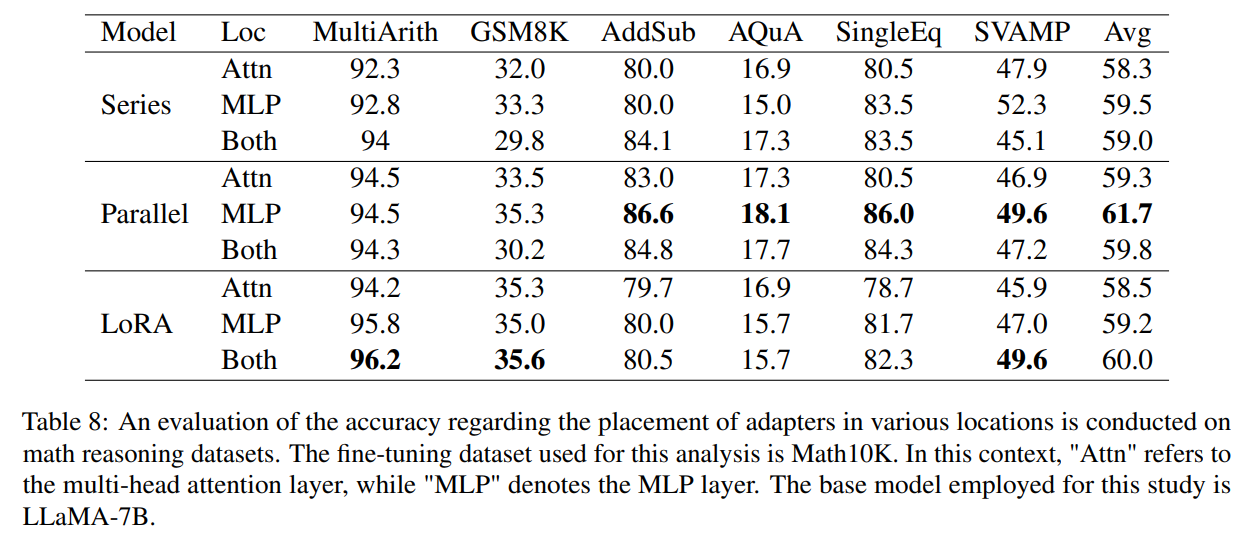
Q. Attention (Multihead attention layer) 혹은 MLP layer 뒤에 adapter가 붙었을 때 성능이 좋은 것을 알겠는데, 그럼 많은 레이어 중에서 어떤 layer를 선택한다는 의미일까?
A. 모델의 구조를 보면 여러 layer를 겹겹이 쌓아서 만든 것인데 분명 이들 중 일부를 택하는 것이지만, 정확히 몇 번째 혹은 몇 개에 적용한지에 대한 설명은 나와있지 않다.
가장 적합한 configuration을 알아보기 위해 math reasoning 데이터셋의 대하여 정확도 평가를 진행함. Prefix-tuning 기법에 대해서는 virual token을 10, 20, 30, 40으로 각각 세팅했을 때의 성능 차이를 확인함. Series와 Parallel adapter에 대해서는 bottleneck 사이즈를 64, 128, 256, 512로 변화시켰을 때의 차이를 알아봄. 마지막으로 LoRA의 경우, rank를 4, 8, 16, 32로 변경했을 때 성능 차이를 알아봄. Prefix-tuning의 경우, virtual token의 수가 10일때, Series와 Parallel adapter의 경우, bottleneck 사이즈가 256일때 가장 좋은 성능을 보임. LoRA의 경우, rank를 증가시킬 수록 성능이 좋아짐 (각 데이터셋에 따른 보다 자세한 결과는 아래 숨은 글 확인).

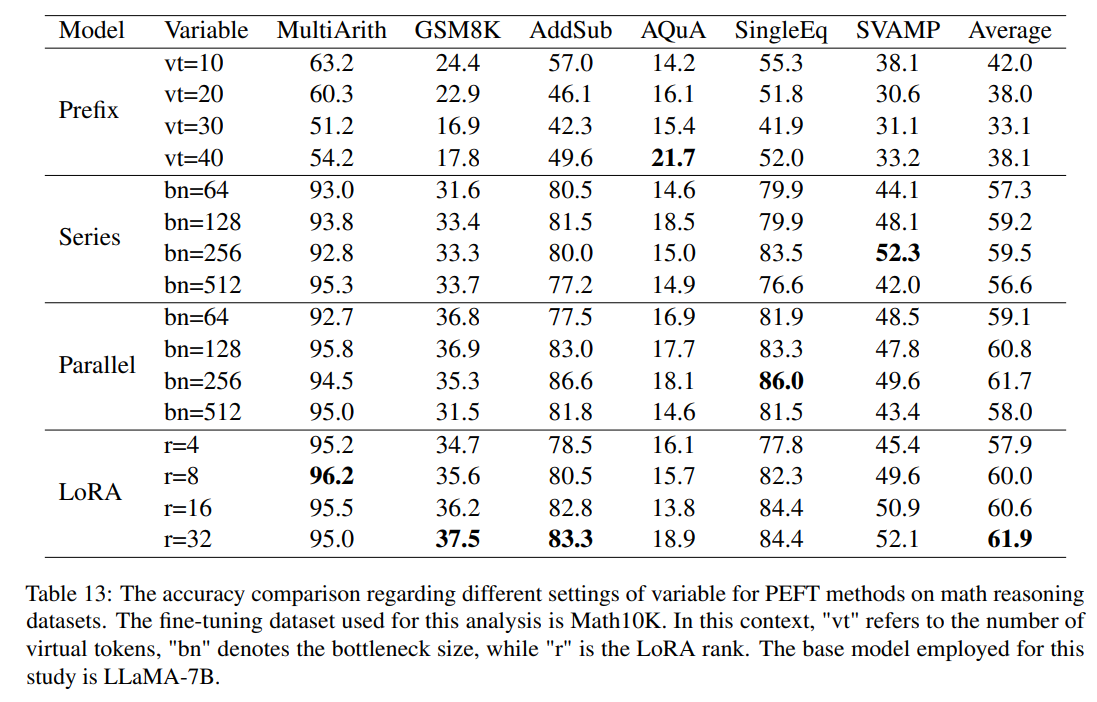
Q. LoRA 기법에서는 rank를 몇 차원으로 분해하는냐에 따라 성능이 달라지기 때문에 r 값을 변경하며 실험을 진행한 것이 이해가 갔다. 그렇다면, 나머지 기법들은 왜 virtual 토큰 수나 bottleneck 사이즈를 비교했을까?
A1. Prefix-tuning에서 virtual 토큰이라 입력 임베딩 앞에 추가되는 학습 가능한 벡터, 즉 prefix 역할을 하는 토큰들을 의미합니다. virtual 토큰을 통해 작업별 중요한 문맥 정보를 추가할 수 있습니다. 하지만, 해당 토큰이 너무 많을 경우, 학습 효율이 떨어질 수 있으므로 이를 주의해야 하며, 본 논문에서는 실험 결과를 통해 10개가 가장 적절한 토큰 수임을 증명한 것입니다.
A2. bottleneck은 down-projection과 up-projection 과정을 의미합니다. 즉, 병목 구조를 통해 학습 파라미터 수를 줄여 효율적인 학습을 가능하게 합니다. 이때, 차원 축소 정도에 따라 trade-off 현상이 일어나게 되는데, bottleneck 사이즈를 줄일 경우, 학습할 파라미터 수가 감소하여 계산 비용은 절감되지만, 정보 손실이 발생할 수 있습니다. 반대로 사이즈를 키울 경우, 더 많은 정보 유지가 가능하지만 동시에 많은 계산 비용과 더불어 과적합 문제가 발생할 수도 있습니다. 본 논문에서는 256이 가장 적절한 사이즈라고 말하고 있으며, 512가 되었을 때, 오히려 성능이 떨어진 것은 과적합이 발생했다고 해석할 수 있을 것 같습니다.
4.2 Arithmetic Reasoning
Arithmetic reasoning 테스크에서 모델의 성능을 평가하기 위해 Math10K 데이터셋을 이용해 모델들을 학습 시킨 후, 6가지의 math reasoning 데이터셋에서 성능을 평가함. 평가를 위해 GPT-3.5 (text-Davinci-003) 모델을 비교 모델로 잡음. 전반적으로 GPT-3.5 모델이 adapter-based PEFT 방식으로 fine-tuning된 모델이 비해 성능이 좋았음. 하지만 비교적 단순한 테스크인 MultiArith, AddSub, SingleEq에서는 LoRA 방식으로 학습시킨 LLaMA-13B 모델의 성능이 더 좋았음. 충분한 학습 데이터만 있다면, 작은 LLM 모델이 일반 LLM 모델의 성능을 뛰어넘을 수 있음을 시사함. 하지만, 비교적 단순한 수학 추론 테스크에서는 작은 LLM 모델이 성능을 보인 반면, 조금 더 고차원적인 수학 추론 문제에서는 큰 성능 차이를 보임. 여러 adapter 모델 중에는 LoRA의 성능이 가장 좋았음.
4.3 Commonsense Reasoning
추가적으로 commonsense reasoning 테스크에 대해서도 성능을 비교해봄. Commonsense reasoning 테스크에서는 비교 모델로 GPT-3 (175B), PaLM (540B), ChatGPT를 사용함. 놀랍게도 Series Adapter, Parallel Adapter, LoRA를 활용해서 학습시킨 LLaMA-13B 모델이 ChatGPT를 포함한 모든 비교 모델보다 좋은 성능을 보임. 또한, fine-tuning 시 base 모델이 성능이 영향을 미친다는 것도 BLOOMz와 GPT-J J를 통해 밝혀냄 (LLaMA-13B 모델이 나머지 두 모델에 비해 더 좋은 성능을 보임).

4.4 ID and OOD Analysis
PEFT 방식에 대해서 math reasoning과 commonsense reasoning 두 가지 추론 테스크에서 실험을 진행한 결과, commonsense reasoning에서 일반적으로 더 좋은 성능을 내는 것을 발견함. 이 이유를 in-distribution (ID)과 out-of-distribution (OOD) 관점으로 접근하여 살펴봄. Commonsense 170K 데이터셋의 경우, commonsense reasoning의 training set을 전반적으로 포괄할 수 있도록 제작됨. ID 데이터셋으로 학습된 LLaMA-13B는 ChatGPT를 능가하는 성능을 보여줌. 반면, Math 10K의 경우, GSM8K와 AQuA 만을 활용해서 제작됨. 하지만, GSM8K와 AQuA 보다 오히려 학습되지 않은 MultiArith, AddSUn, SingleEq에서 더 좋은 성능을 보임. 이는 adapter 기반의 학습 방법이 OOD에서도 잘 작용하는 것을 의미함. 그럼에도 불구하고 GSM8K와 AQuA에서 성능이 나오지 않은 것은 해당 테스크가 더 난이도 높은 수학적 추론 능력을 요구하기 때문임.
5 Qualitative Study
이전 섹션에서 정량적 평가를 진행했다면, 해당 섹션에서는 정성적 평가를 진행함. 아래와 같이 GSM8K에서 random하게 질문 하나를 선택 후 모델별 답변을 비교함. ChatGPT는 정확한 추론 과정과 정답을 보여준 반면, LLaMa Prefix-Tuning 모델은 잘못된 추론을, Parallel 모델과 LoRA 모델을 추론 과정은 거의 비슷한 추론 과정을 보였지만, Parallel의 경우 계산 실수로 오답을, Series 모델은 정확한 추론 과정과 정답을 답함.

6 Conclusion
본 논문에서 사용자 친화적인 프레임워크인 LLM-Adapter 개발을 통해 adapter기반의 PEFT를 손쉽게 적용할 수 있도록 함. PEFT 적용 결과를 평가하기 위해 두 가지 reasoning 테스크에 대한 데이터셋을 구축함. LLM-Adapter와 데이터셋을 기반으로 PEFT의 적절한 위치 및 형태, 구조, 그리고 ID와 OOD의 영향에 대한 결과를 밝혀냄.
7 Limitations
한정된 자원으로 인해 조금 더 큰 모델 LLaMA-33B 혹은 LLaMA 65B에 대한 실험을 이뤄지지 않음. 또한, 여러 adapter를 함께 적용하는 방식에 대한 실험은 진행하지 않음.
모델 학습을 하다보면 parameter setting을 해야하고 그 중 LoRA는 빠지지 않는 기법인데,
본 논문이 LoRA만을 설명하는 논문은 아니지만,
LoRA가 최근 기법이 아님에도 LLM fine-tuning에 얼마나 효과적인지 알 수 있네요.
일단 해당 논문은 정말 다양한 비교 실험을 진행한 것이 큰 장점인 것 같아요!
하지만, 테스크를 추론 문제에 집중하다보니, 다른 테스크에서는 또 다른 결과가 나오지 않을까하는 생각이 듭니다.
