2024. 9. 27. 16:05ㆍPaper Review/Large Language Model (LLM)
Shumailov, I., Shumaylov, Z., Zhao, Y. et al. AI models collapse when trained on recursively generated data. Nature 631, 755–759 (2024). https://doi.org/10.1038/s41586-024-07566-y

2024년 7월 Nature 저널에 등록된 article이다. 요즘 LLM에서 대부분의 논문들이 model의 성능을 높이거나 효율성을 향상시키는 방향이라는 점과 대비되는 논문인데, 이 논문은 생성형 AI가 만든 데이터를 LLM에 다시 학습을 시켰을 때 일어날 수 있는 model collapse 현상에 대해서 다루는 논문이라 신선했다.
Abstract
Stable diffusion은 image to text generation에서 혁신을 가져오고, GPT-2,3,4 모델은 NLP task에서 높은 성능을 보인다. ChatGPT는 이러한 LLM을 대중에게 소개하는 역할을 했으며, 이제 LLM과 같은 생성형 AI가 온라인 텍스트와 이미지 생태계를 크게 변화시킬 것이라는 것은 분명하다. 하지만 LLM이 온라인에서 발견되는 텍스트의 대부분을 차지하게 된다면?
LLM을 학습할 때 언어모델이 생성한 컨텐츠가 학습 데이터의 대부분을 차지하게 되면, 학습된 모델의 결함이 발생하여 원본 컨텐츠 분포의 꼬리 부분이 사라지는 것을 발견하였다. 이를 'model collapse'라고 부르며, 이 현상은 LLM 뿐만 아니라 VAEs(Variational autoencoders), GMMs(Gaussian mixture models)에서도 발생할 수 있음을 발견하였다. 이 논문에서는 이러한 현상에 대한 이론을 구축하고, 모든 학습된 생성 모델에서 이 현상이 존재할 수 있다는 것을 이야기한다.
대부분의 학습 데이터가 웹에서 스크랩하는 데이터라는 감안하면, 이는 중대한 문제가 될 수 있다. 인터넷에서 크롤링된 데이터에 LLM으로 생성된 컨텐츠가 포함되어 있는 경우, 시스템과 인간의 실제 상호작용으로 만들어진 데이터의 가치는 점점 더 높아질 것이다.
Intro
저자들은 LLM의 개발에는 매우 많은 양의 학습 데이터가 필요하다는 말로 이 논문을 시작한다.
기존의 LLM (GPT, LlaMa 등)은 사람이 생성한 텍스트로 학습이 되었지만, 웹에서 수집한 데이터를 학습에 사용한다면 앞으로는 데이터가 모델이 생성한 데이터로 학습하는 것은 당연하게 될 것이다.
다른 모델에서 생성된 데이터를 모델이 무차별적으로 학습하게 된다면?
모델이 실제 기본 데이터 분포를 잊어버리게 되는 modell collapse가 발생하게 된다고 한다.
What is model collapse?

model collapse는 학습된 generative model의 생성에 영향을 미치는 퇴행적 과정이라고 설명한다.
generative AI 모델을 통해 생성된 데이터는 다음 generation의 학습 데이터 집합을 오염시킨다.
이 논문에서는 모델 붕괴를 early model collapse와 late model collapse의 2가지로 구분한다.
초기 모델 붕괴(early model collapse)에서는 모델이 학습 데이터 분포의 꼬리에 대한 정보를 잃기 시작하고,
후기 모델 붕괴(late model collapse)에서는 모델이 원래 학습 데이터 분포와 거의 유사하지 않은 분포로 수렴하면서 종모양 분산이 크게 감소한다.
그렇다면 model collapse의 원인은?
이 논문에서는 3가지의 error가 model collapse를 발생시킨다고 주장한다.
1. Statistical approximation error: 모델이 학습하는 데이터셋이 유한하기 때문에 재표본 추출을 할 때마다 정보를 잃게 되며, 특히 낮은 확률의 사건에서 크게 나타난다. 모델이 데이터를 반복적으로 재표본화하기 때문에 이 오류가 축적되어 데이터분포의 꼬리 부분인 낮은 확률의 사건이 사라지게 되는 것.
2. Functional expressivity error: Nerural network, 즉 신경망이 강력하지만 완벽한 표현을 제공하지 못하기 때문에, 복잡한 분포를 표현하는 능력이 제한된다. 이로 인해 데이터를 잘못 표현할 수 있으며, 복잡한 multi-modal dataset을 단순화하여 함수로 근사해야할 때 발생하는 문제.
3. Functional approximation error: 학습 알고리즘 자체에서 비롯되는 문제로, optimization 방법과 같은 모델 학습에 사용되는 기법들이 학습과정에서 bias를 도입되게 한다. 이러한 bias는 다음 세대의 모델로 넘어갈 수록 누적되어 데이터 근사에서 더 큰 부정확성이 발생하게 된다.
Theoretical intuition
이 논문에서는 model collapse process가 이전 세대에서 생성된 데이터를 재귀적으로 학습하는 generative model에서 보편적으로 발생한다고 주장하며, 모델 붕괴 현상을 묘사하는 2가지 수학적 모델을 제시한다.
generation $i$의 데이터셋 $D_i$는 $p_i$ 분포를 갖는 독립적이고 동일하게 분포된 무작위 변수 $X^i_j$로 구성되며 $j\in \{1,...,M_i\} $는 데이터셋의 크기를 나타낸다.
generation $i$에서 generation $i+1$로 넘어가면서, approximation $p_{\theta_{i+1}}$을 사용하여, $D_i$에서 샘플의 분포를 추정한다.
이 단계를 functional approximation $p_{\theta_{i+1}} = F_\theta(p_i)$라고 한다.
이후, 데이터셋 $D_{i+1}$은 $p_{i+1}=\alpha_ip_{\theta_{i+1}}+\beta_ip_i+\gamma_ip_0$에서 샘플링하여 생성되며, 음수가 아닌 파라미터 $\alpha_i, \beta_i, \gamma_i$는 1로 합산되어 다른 세대에서 사용된 데이터의 비율을 나타낸다.
위의 수식은 원래 분포에서 나온 데이터 $\gamma_i$, 이전 세대에서 사용한 데이터 $\beta_i$, 새로운 모델에서 생성된 $\alpha_i$가 혼합된 것을 이야기하며 이를 sampling 단계라고 한다.
뒤에 나올 수학적 모델에서는 $\alpha_i=\gamma_i=0$, 즉 한 단계의 데이터만 사용하고, numerical experiments에서는 현실적인 파라미터 선택에 대해 수행한다.
Discrete distributions with exact approximation
여기서는 이상적인 환경인 함수 근사 및 표현식 오류가 없는 이산확률 분포, $F(p)=p$를 고려한다.
이러한 경우에서 model collapse는 샘플링 단계에서의 통계적 오류로 인해 발생한다.
우선 sampling 확률이 낮기 때문에 꼬리 분포가 사라지기 시작하고, 시간이 지남에 따라 분포의 지지도가 줄어든다.
표본 크기 $M$에 대해 확률 $q\leq\frac{1}{M}$인 상태 $i$를 고려한다면, 이 상태에서 sample $i$가 나올 확률은 1보다 작아진다. 이는 해당 사건에 대한 정보를 잃는다는 것을 의미한다. state $i$의 발생확률 $q$가 매우 낮다면, 실제로 이 state의 샘플을 얻지 못할 가능성이 높아지므로, 이 정보를 잃는다는 의미가 된다.
이러한 상황에서 여러 세대에 걸쳐 샘플링을 반복하게 되면, 점점 더 많은 정보가 손실된다. 이로 인해 최종적으로 확률 분포는 특정 상태에 집중되는 델타 함수(한 점에만 모든 확률 질량이 집중된 함수)로 수렴하게 된다. 이렇게 된다면, 모델이 실제 데이터의 다양성을 잃고 한 가지 상태만을 반복적으로 출력되는 현상이 나타난다는 것이다.
확률 $q$가 있는 state $i$에서 조건부 확률을 통해 정보를 잃을 확률(생성 단계에서 데이터를 샘플링하지 않을 확률)이 $1-q$와 같고, 이 상황이 반복되면 최종적으로 데이터셋은 실제 분포를 반영하지 못하고 편향된 결과만을 보여준다.
이는 $X^i\rightarrow F\rightarrow p_{i+1}\rightarrow X^{i+1}$ 과정을 Markov chain으로 간주하면 직접적으로 알 수 있다. Markov chain으로 표현하면 $X^{i+1}$은 $X^i$에만 의존하기 때문에 모델이 오직 직전 세대의 모델로부터 얻은 데이터에만 기반하여 학습된다는 것을 수학적으로 표현할 수 있다.
또한 모든 $X^i_j$가 동일한 값을 갖는다면 다음 세대에서 근사화된 분포는 정확히 델타함수가 되며, 따라서 모든 $X^{i+1}_j$도 동일한 값을 갖게 된다. 이는 Markov chain의 흡수상태가 되는데, 흡수상태는 한번 도달하면 다른 상태로 전이할 수 없는 상태를 말하며 모델에서는 단일 출력값만을 반복적으로 생성하는 상태를 의미한다.
- 여기서 Markov chain은 적어도 하나의 흡수상태를 포함하며, 확률 1로 흡수 상태 중 하나의 수렴한다는 것을 의미한다. 이건 저명한 사실이라고 하고 증명은 supplementary information에 있다는데.. 여기까지는.. ㅎㅎ....
어쨋든! 이 Markov chain에서 유일한 흡수상태는 델타함수에 해당하는 상태이며, model collapse 진행과정을 따라가다보면, chain이 흡수될 때 원래 분포의 모든 정보를 잃고 일정한 상태에 도달한다는 것이다.
이러한 논의를 바탕으로, 완벽한 함수 근사치를 가지는 이산분포의 경우 확률이 낮은 사건만 차단되는 early model collapse와 mulit-modal이 아닌 single mode에서 모델이 collapse하는 late model collapse까지 어떻게 발생하는지 알 수 있다.
Model collapse in language models
이 논문에서는 언어 모델이 언어모델이 생성한 데이터로 다시 fine-tuning 될 때 'model collapse' 현상에 대해 실험한다.
우선 LLM들은 PLMs(pre-trained language models)을 기반으로 하여 특정 task에 맞도록 fine-tuning하여 사용된다. 이런 언어모델들이 다른 모델이 생성된 데이터로 반복적으로 미세조정되면, 이 모델들은 점점 원래의 데이터셋의 분포에서 벗어난 데이터를 학습하게 된다. 이로 인해 데이터의 분포를 잘못 학습하거나, 초기에 학습한 데이터의 특성을 잊어버리는 model collapse 현상이 일어난다.
저자들은 LLM을 학습시키는데에 많은 resource가 들어가고, 환경적으로 좋지 않다고 판단하여 일반적으로 LLM으로 알려진 GPT나 Llama 같은 큰 모델로 실험을 수행하지는 않았다. 개념 증명을 위한 실험만 진행하기 위해 Meta에서 제공하는 OPT-125m (다른 생성형 언어모델 파라미터 수는 기본 단위가 billion인데 125million 밖에 안되는 작은 모델을 사용) 모델을 fine-tuning하여 실험을 진행했으며, 이 모델에서 생성된 데이터로 반복 학습하게 된다.
실험은 아래와 같이 진행되었다.
데이터셋은 wikitext2 데이터셋을 사용하였다고 한다. wikitext2 데이터셋은 위키백과에서 추출된 텍스트를 기반으로 하는 데이터셋이다.
데이터 생성을 위해 5-way beam search 방식을 사용하였고, train sequence를 64 token 길이로 자른 이후에 다음 64 token을 예측하도록 하였다. 모든 원본 훈련 데이터셋에 대해 동일한 크기의 데이터셋을 생성했으며, 원본 데이터를 모두 학습시켰고 모델의 오류가 0이라면 반복해서 학습을 하더라도 원본 wikitext2의 128 token까지를 생성할 수 있게 될 것이다.
각 generation의 학습은 원본 학습 데이터에서 모델을 생성하는 것부터 시작한다. 각 세대마다 실험은 각각 5번씩 실행되었으며, 결과는 서로 다른 random seed를 사용해서 5개의 개별 실행으로 표시하였다고 한다. 실제 wikitext2로 fine-tuned된 실험에서 사용할 fine-tuned OPT-125m 모델의 perplexity는 zero-shot baseline은 115지만, 학습 이후 34로 성공적으로 학습이 되었다. 그리고 다음 세대에서 학습을 진행하는 모델은 원본 wikitext2 validation set에서 가장 성능이 좋은 모델을 선정하여 model collapse 현상이 뚜렷하게 나타날 수 있도록 했다. 이런식으로 generation 0 ~ 9까지 실험을 반복한다.
실험은 크게 2가지로 진행된다.
1. 5 epochs를 학습시키고 다음 세대를 학습시킬 때 (다음 에폭 학습 시) 원본 데이터셋을 아예 사용하지 않고 모델이 생성한 데이터로 재학습
2. 10 epochs를 학습시키고 다음 세대를 학습시킬 때 원본 데이터의 10%를 무작위로 샘플링하여 학습
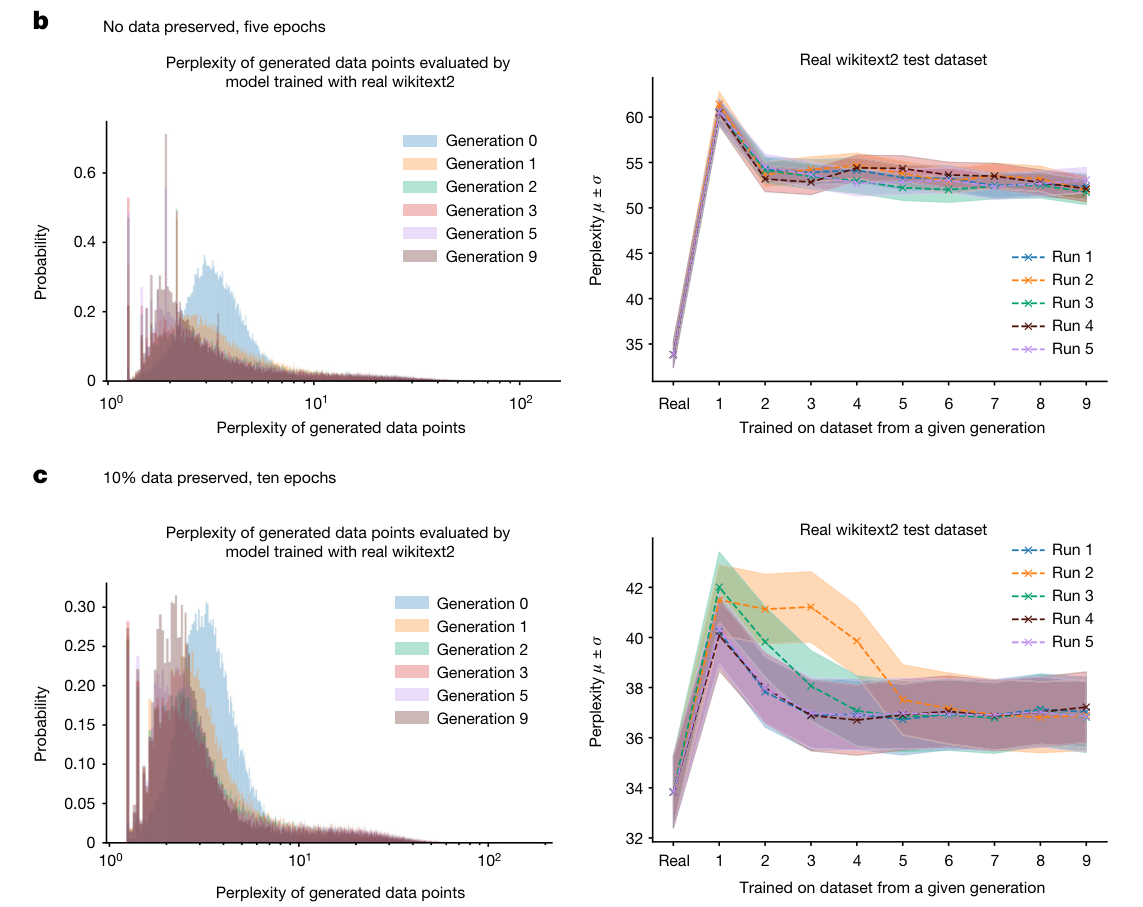
우선 figure b,c의 오른쪽 그림을 보자.
첫번째 실험에서 나온 결과로는 perplexity에서 20 ~28 points 정도 성능 저하가 일어났음을 볼 수 있다. 두번째 실험에서는 원본 데이터를 보존했을 때 perplexity 기준으로 첫번째 실험에 비해 성능저하가 더 적은 것을 볼 수 있다.
논문에서는 두 학습 체제 모두 모델의 성능저하는 있었지만, 일부 task에 대해서 성공적으로 수행할 수 있었다고 이야기한다.
이번엔 왼쪽 그림을 보면, perplexity가 낮은 샘플의 밀도가 여러 세대에 걸쳐서 누적되면서 모델의 붕괴가 발생함을 알 수 있다. 즉, 학습 세대를 거듭할 수록 샘플링된 데이터는 델타함수와 같이 붕괴될 가능성이 높다는 것이다. 즉 세대를 거듭할 수록 높은 확률로 생성할 수 있는 시퀀스를 더 많이 생성하는 경향이 보여진다.
그리고 데이터의 꼬리 분포를 보면, 꼬리가 generation 9에 가까울수록 점점 길어지는 모습을 볼 수 있는데, 이건 원래 모델에서는 생성되지 않는 데이터가 학습이 거듭되면서 오류의 누적으로 생성되는 경우를 뜻한다.
여기서 관찰된 결과가 위의 theoretical intuition에서 확립해둔 것과 일치한다! 여기서 실험은 유한한 generation에 대해서 진행하지만, theoretical intuition 파트에서는 무한대에 수렴하는 경우에 대해서 가정하기에 이 실험이 무한히 지속되면 모델 붕괴가 일어난다는 것.
OPT-125m 모델의 text 출력 sample
- Input: some started before 1360 — was typically accomplished by a master mason and a small team of itinerant masons, supplemented by local parish labourers, according to Poyntz Wright. But other authors reject this model, suggesting instead that leading architects designed the parish church towers based on early examples of Perpendicular.
- 입력은 건축과 역사에 대한 설명으로, 1360년 이전부터 시작된 건축 프로젝트에 대한 내용이다.
- Outputs
- Gen 0: Revival architecture such as St. John’s Cathedral in London. The earliest surviving example of Perpendicular Revival architecture is found in the 18th @-@ century Church of Our Lady of Guernsey, which dates from the late 19th century. There are two types of per- pendicular churches : those.
- Generation 0에서는 구체적이고 역사정인 정보를 포함하며, 비교적 정확하고 자세하게 출력이 나온다. @-@ 이런것도 섞여있긴하다.
- Gen 1: architecture such as St. Peter’s Basilica in Rome or St. Peter’s Basilica in Buenos Aires. There is no evidence that any of these build-ings were built during the reign of Pope Innocent III, but it is possible that they may have been built during the reign of his successor, Pope Innocent.
- Generation 1에서도 구체적인 건축 예시를 들며 어느정도의 일관성은 유지하고 있지만, 일부 정보의 정확성이 떨어진다.
- Gen 5: ism, which had been translated into more than 100 languages including English, French, German, Italian, Spanish, Portuguese, Dutch, Swedish, Norwegian, Polish, Hungarian, Slovak, Lithuanian, Estonian, Finnish, Romanian, Bulgarian, Turkish, Croatian, Serbian, Ukrainian, Russian, Kazakh, Kyrgyz.
- Generation 5에서는 주제가 이상하게 달라졌고, 건축이나 역사의 내용과는 관련이 없는 다양한 언어로 번역되었다는 내용으로 넘어간다.
- Gen 9: architecture. In addition to being home to some of the world’s largest populations of black @-@ tailed jackrabbits, white @-@ tailed jackrabbits, blue @-@ tailed jackrabbits, red @-@ tailed jackrabbits, yellow @-.
- Generation 9에서는 model collapse가 일어난 것을 볼 수 있다. 헤롱헤롱 @-@
Ablation study
실험에서 생성된 예시를 보면, 반복되는 구문이 많이 포함되어 있다. 이건 기존 GPT 같은 모델에서도 자주 발견되는 문제인데, ablation study에서는 이런 반복되는 sequence를 생성하지 않도록 유도하기 위해 반복에 대한 penalty를 주고 실험해봤다고 한다.
이러한 접근 방식으로 생성된 text는 penalty를 피하기 위해 낮은 점수의 sequence를 생성하게 했고, 결과적으로 모델의 성능이 더 안좋아졌다고 하며, LLM 실험에서 이 penalty를 적용했을 때 perplexity는 기존에 비해 2배 증가했다고 한다.
이 실험에서도 세대를 거듭할수록 모델이 원본 데이터에서 더 확률이 높은 시퀀스를 생성하는 경향을 보였고, 자체적으로 가능성이 없는 시퀀스, 즉 아까 말한 새로 생긴 꼬리분포 같은 데이터를 생성하여 오류가 발생한다는 것을 발견했다.
Discussion
저자들은 이러한 error나 저품질 컨텐츠가 포함되는 것을 poisoning이라고 표현하였는데, 이런 식의 data poisoning은 이전부터 존재해 왔었다. click farm, content farm, troll farm과 같이 알고리즘에 부정적으로 영향을 미치는 방법에 대해 Google은 교육 사이트 같은 source에서 나온 컨텐츠에 더 중점을 두어 조작된 기사를 다운그레이드하였고, DuckDuckGo에서는 이를 완전히 제거했다.
하지만, LLM의 등장으로 이러한 poisoning의 규모는 매우 커진다. LLM이 낮은 확률의 사건을 모델링하는 능력은 모델의 공정성 측면에서 필수적인데, 이런 데이터는 종종 소외된 그룹과 관련이 있기 때문이다.
또한, 학습 데이터의 질이 모델의 성능에 결정적인 영향을 미치기 때문에, 다른 생성 모델로 생성된 데이터를 장기적으로 학습한다면, 모델이 task 자체를 잘못 인식하게 될 가능성 또한 존재한다.
또 시간이 지나면서 원본 데이터 source에 계속해서 접근할 수 있도록 보장하는 것이 중요하며, LLM에서 생성된 데이터를 다른 데이터와 구별해야할 필요성에 대해서도 논의한다. LLM에서 생성된 컨텐츠를 대규모로 추적할 수 있는 방법이 현재까지는 없는 상황이기 때문에.
저자들은 LLM 커뮤니티 전체의 협력을 통해 LLM과 이를 통한 컨텐츠의 생성과 배포에 있어서 출처 문제를 해결하는데 필요한 정보를 공유해야한다고 주장하는데... 이게 진짜 쉽지 않을 것 같다.
마무리하면서...
이렇게 오늘은 무려 Nature에 실린 AI models collapse when trained on recursively generated data 논문을 살펴봤는데.. 맨날 자기 모델이 더 좋다고 자랑하는 논문들만 보다가 이렇게 문제점 지적하는 논문은 신선했다.
블로그 쓰면서 처음 수식도 넣어보고 했는데.. 생각보다 어려웠다...
모델이 붕괴하는 거랑 비슷하게 overfit 났을 때 동일한 출력만 반복한 적이 있었는데 그 때 GPT 생성 데이터로 학습했는데 혹시... 하는 생각도 들고. 내가 먼저 쓸 수 있었는데 아숩네잉
아 그리고 VAE랑 GMM 에 대한 실험결과는 nature 사이트에서 supplementary information에 다 들어있긴 했는데 본문에는 포함시키지 않았다. 맨 위에 링크에서 확인할 수 있다.
세상엔 똑똑한 사람들이 참 많은 것 같다.
