2024. 9. 23. 17:11ㆍPaper Review/Large Language Model (LLM)
LIMA: Less Is More for Alignment, In Proceedings of the 37th International Conference on Neural Information Processing Systems (NIPS '23). Chunting Zhou, Pengfei Liu, Puxin Xu, Srini Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, Susan Zhang, Gargi Ghosh, Mike Lewis, Luke Zettlemoyer, and Omer Levy.
https://arxiv.org/abs/2305.11206
LIMA: Less Is More for Alignment
Large language models are trained in two stages: (1) unsupervised pretraining from raw text, to learn general-purpose representations, and (2) large scale instruction tuning and reinforcement learning, to better align to end tasks and user preferences. We
arxiv.org
Abstract
LLM (Large Language Model) 들은 training 단계에서 크게 2가지 stage를 거침.
(1) Unsupervised pretraining from raw text.
(2) Large scale instruction tuning and reinforcement learning.
본 논문에서 소개하는 LIMA 모델을 통해 이 2가지 stage의 상대적 영향력을 파악해볼 수 있음.
LIMA모델은 LLaMa 65-B 모델에 잘 정돈된 1,000개의 데이터셋으로 fine-tuning 시킨 모델임.
결과적으로, 적은 fine-tuning 데이터 사이즈에도 불구하고, LIMA 모델은 다른 LLM state-of-the-art (SOTA) 모델과 비교하였을 때도 상대적으로 우수한 성능을 보였음.
1. Introduction
LM (Language Model)들은 대규모 데이터를 바탕으로 next token predicition을 진행하면서 pretraining을 진행함. → stage (1)
이후, 모델 aligning을 진행하기 위해 다양한 방법들이 고안됨. (i.e. Instruction tuning, Reinforcement Learning from Human Feedback (RLHF) 등)우리가 사용하는 ChatGPT와 같은 수준의 alignment를 획득하기 위해서는 굉장히 많은 시간과 자원이 필요함.
그러나, 본 논문에서는 strong pretrained LM이 있다면, 잘 정돈된 적은 데이터만으로도 fine-tuning하여 원하는 alignment 성능에 도달할 수 있음을 증명함.
Alignment Hypothesis (가설): Alignment can be a simple process where the model learns the style or format for interacting with users, to expose the knolwedge and capabilities that were already acquired during pretraining.
즉, 모델의 지식과 역량은 전부 pretraining 단계에서 학습되며, alignment는 인간과 상호작용하기 위해 배우는 일종의 style 학습에 불과하다는 것.위 가설을 증명하기 위해 1,000개의 high-quality prompts-responses 데이터를 수집 및 생성함.1,000개의 데이터를 LLaMa 65B에 학습한 결과, 다른 SOTA 모델에 비해 비슷하거나 우수한 성능을 보이는 것을 증명함. (데이터셋 및 실험 과정은 아래에서 설명함)
2. Alignment Data
결국, 본 논문에서는 alignment의 경우, 일종의 style 혹은 format을 학습하는 것이기 때문에 적은 규모의 데이터셋으로도 가능하다고 봄.
이를 위해 총 1,000개의 prompts-responses 형태의 데이터를 수집 및 생성함.
750개는 online community에서 수집, 250개는 직접 생성함.
이때, alignment 학습을 위해 input은 다양하게, output은 일정하게 함 (output의 경우, "helpful AI assistant" style에 맞춤).

2.1 Community Questions & Answers
StackExchange: 사이트 내부에 여러 sub community가 존재하지만, 그 중 가장 유명한 것은 programming 관련 커뮤니티 (Stack Overflow).
Content가 우수한 편. 다양한 도메인의 데이터 수집을 위해 STEM 필드와 Non-STEM 필드로 구분 후, 각 200개의 질문-답변 데이터 수집. Helpful assistant style을 유지하기위해 지나치게 짧은 답변 (1,200 characters 이하), 지나치게 긴 답변 (4,096 characters 이상), 1인칭 시점으로 답변을 시작하는 경우 ('I'. 'My' 등), 혹은 답변에 다른 참조를 언급하는 경우 ('as mentioned', 'stack exchange' 등)는 제거함. 이 외에도 link, image, HTML 등은 제거함.
wikiHow: 사이트 wiki-style의 publication을 포함. 총 200개의 데이터를 수집함. Title을 prompt로 간주, 각 article의 본문을 답변으로 간주함. 따라서, "This article"을 "following answer"로 변경함.
The Pushshift Reddit Dataset: Reddit은 가장 큰 online community 중 하나이지만, 특성상 진지한 답변 보다는 해학적, 풍자적 답변이 인기있는 경우가 많음. 따라서, 2개의 sub reddit ( r/AskReddit & r/WritingPrompts)으로 제한하여 데이터를 수집함. AskReddit에서는 title만 수집하고 답변은 수집하지 않았으므로 test 데이터로 활용함. r/WritingPrompts에서는 총 150개의 데이터를 training 데이터를 수집함.
2.2 Manually Authored Examples
저자가 직접 생성한 데이터셋. Group A, B로 나눈 후, 각각 250개의 prompt를 생성. 최종 데이터셋의 distribution은 위 Table1을 참조.
생성한 prompt에 대해 답변은 스스로 작성함. 이때, alignment를 위해 답변의 tone이 비슷하도록 유지. 또한, 13개의 prompt는 의도적으로 toxic한 prompt를 생성. 답변으로는 답하기를 거절하며, 왜 답변하면 안되는지를 작성함. 추가적으로 보다 다양한 task 포함할 수 있도록 50개의 prompt는 Super-Naturallnstruction 데이터셋에서 가져옴.
3. Training LIMA
LLaMa 65B에 1,000개의 alignment 데이터셋으로 학습을 진행함.
1) Token
- user ↔ assistant 구분을 위해 end-of-turn (EOT) 토큰을 각 utterance 끝에 추가하여 학습함.
- 기존 end-of-sentence (EOS)와 비슷한 역할을 수행하지만, 실제 EOS 토큰과의 구분을 위함.
2) Training parameters
- epoch: 15
- optimizer: AdamW
- weight decay: 0.1
- learning rate: 1e-5
- batch size: 32
- max token length: 2,048
3) Residual dropout: residual dropout을 사용
* 모델의 평가지표 중 하나인 perplexity값이 generation quality와 항상 일관된 상관성을 보이지는 않기 때문에 5 ~ 10 epoch에서 50개씩 샘플 답변을 추출한 후, 이를 평가에 활용함.
4. Human Evaluation
4.1 Experiment Setup
Baselines: 총 5가지 모델과 비교.
Generation: 각 모델에 대해 prompt당 하나의 답변을 생성.
Methodology: 사람 평가자에게 한 개의 prompt 당 서로 다른 2개의 답변을 보여줌 (하나는 LIMA, 다른 하나는 5가지 모델 중 하나). 서로 다른 2개의 답변 중 더 좋은 것을 선택 혹은 비슷하면 Tie를 선택. 같은 방식으로 GPT-4에게 답변의 평가를 지시함.
Inter-Annotator Agreement: 사람 평가자들이 동일한 답을 선택했을 경우, 1p, Tie를 선택했을 경우, 0.5p, 서로 다른 답을 선택했을 경우, 0p를 부여. 결과, 사람 평가자들과 80% 답변 일치도를 보임. GPT-4의 경우, 사람 평가자들과는 78~79%의 일치도를 보임.
4.2 Results
결과 Figure 1&2 참조.
더 많은 데이터로 fine-tuning 혹은 RLHF training을 시킨 Alpaca 65B 모델과 DaVinci003에 비해 더 높은 답변 성능을 보임. 또한 특정 물음에 대해서는 GPT-4와 비슷한 수준 혹은 능가하는 답변 수준을 보임.
4.3 Analysis
추가적으로 50개의 prompt에 대해 LIMA 답변에 대한 절대 평가를 진행함. 결과, 50개 중 50%는 excellent 수준의 답변 성능을 보임. 또한, training 데이터셋에 포함되어 있지 않은 일부 task에 대해서도 답변을 하는 것을 확인 함. Safety 측면에서도 1,000개 중 13개의 prompt만 넣고 학습을 진행하였음에도, 일부 safety task에서는 올바른 답변을 함 (i.e. 연예인의 주소를 묻는 질문에 답변을 거절함). 하지만, prompt상 악의적인 의도가 불분명할 경우, 올바르지 않은 답변을 포함하여 생성함.
5. Why is Less More? Ablations on Data Diversity, Quality, and Quantity
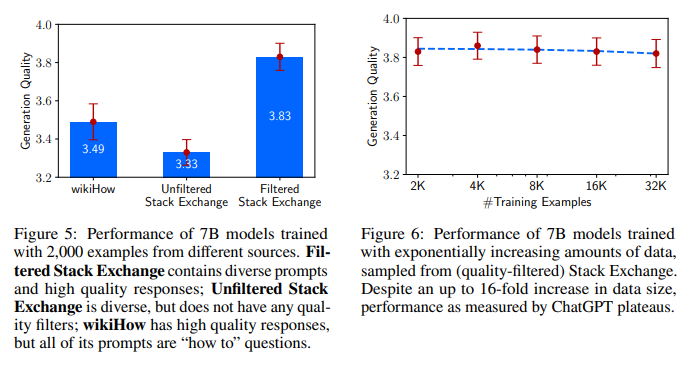
Training 데이터의 어떤 특성이 모델의 alignment 향상에 영향을 미치는지 확인하기 위해 추가적으로 ablation study를 진행함.
총 3가지 측면, 데이터의 다양성, 질 그리고 양에 대해서 실험을 진행. 결과, 데이터의 다양성과 질은 모델 성능에 영향을 미쳤지만, 데이터의 크기는 유의미한 영향을 주지 못하는 것으로 나타남. Figure 5&6 참조.
6. Multi-Turn Dialogue
LIMA 모델은 Few shot sample로 multi-turn dialogue로 주어줬을 때도 높은 성능을 보임.
7. Discussion
Strong pretrained 모델 위에 잘 정돈된 적은 규모의 데이터셋 만으로도 모델의 alignment에 큰 성능 향상을 가져올 수 있는 것을 보였지만, 해당 연구에는 몇 가지 한계점이 존재함. 잘 정돈된 prompt-reponse 데이터셋은 upscale에 어려움이 있음. 또한, 여전히 일부 task에서는 적절하지 못한 답변을 하기 때문에 이를 다룰 수 있는 연구가 필요함.