2024. 10. 15. 17:02ㆍPaper Review/Large Language Model (LLM)
Ovadia, O., Brief, M., Mishaeli, M., & Elisha, O. (2023). Fine-tuning or retrieval? comparing knowledge injection in llms. arXiv preprint arXiv:2312.05934.
https://arxiv.org/abs/2312.05934
Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs
Large language models (LLMs) encapsulate a vast amount of factual information within their pre-trained weights, as evidenced by their ability to answer diverse questions across different domains. However, this knowledge is inherently limited, relying heavi
arxiv.org
2023년 12월에 나와 68회나 인용이 됐는데, 학회나 저널에는 등재가 안되었네요.
하지만 저자들이 Microsoft 출신이고, 또 제가 항상 궁금해하던 주제라 읽고 말았습니다.
근데 결과가 조금 충격적이에요..! 오늘 글이 읽기 싫으신 분들을 위해 결말만 말씀 드리면 Fine-tuning 보다는 RAG입니다.
근데 조금 더 충격적인건 Fintuned model + RAG << Base model + RAG 라는 겁니다.
모델의 Fine-tuning만 생각하던 저.. 이제 뭘 해야할까요?
Abstract
Large Language Model (LLM)은 다량의 정보를 내재화해서 여러 도메인에 걸쳐 다양한 질문에 답을 할 수 있음. 하지만, 이런 지식들은 학습 데이터에 많이 의존적임. 따라서, 외부 지식을 모델에 결합하는 방법, 또는 이전 지식을 모델이 활용하게 하는 능력을 기르는 것이 핵심 과제임. 본 논문에서는 2가지 주요 접근 방법에 대해서 다룸. (1) un-supervised fine-tuning (2) retrieval-augmented generation (RAG). 비교 결과, fine-tuning을 했을 때에도 일부 테스크에서는 성능 향상을 보였지만, 일반적으로 RAG가 성능이 더 좋았음.
1 Introduction
LLM 모델들은 대규모 사전 학습 데이터를 기반으로 여러 도메인에 걸쳐 다량의 정보 및 지식을 보유하고 있음. 하지만, 2가지 문제점이 존재함. 첫째, 이런 지식들은 정적이기 때문에 업데이트가 되지 않음. 둘째, 전문적인 지식이라기 보다는 일반적인 지식에 가깝기 때문에 특정 분야에서는 전문적이지 못함. 2가지가 전혀 다른 문제처럼 보이지만 실상 모델의 성능을 높이면 해결되는 문제임으로 같은 맥락이라고 할 수 있음.
본 논문은 "Knowledge Injection"에 초점을 맞추고 있음. 어떤 형태의 텍스트 데이터가 주어졌을 때, 이를 pre-trained 모델에게 가르칠 수 있는 가장 좋은 방법은 무엇일까? 첫 번째 방법은 fine-tuning임. 또 다른 방법은 in-context learning (ICL)으로 모델의 파라미터를 수정하지 않고 모델에게 보내는 input query만 수정하여 성능 향상을 꾀하는 방법임. ICL의 한 가지 방법이 바로 RAG. RAG는 retrieval 방식을 활용해서 모델에게 관련 정보를 주고 이를 바탕으로 텍스트를 생성하게 함. 본 논문에서는 이 2가지 방법을 비교하여 모델의 knowledge injection 능력을 평가함.
2 Background
본 장에서는 모델이 가지고 있는 "지식"이라는 것에 대해서 설명함. 언어 모델에서 모델이 가지고 있는 지식이란 정답이 있는 사실적 정보를 의미함. 즉, 어떤 질문을 했을 때, N개의 응답 가능한 선택지가 있지만, 1개의 정답이 존재하고, 모델이 이를 맞출 수 있다면 이 모델은 해당 정보 (지식)을 가지고 있다고 볼 수 있음. 그렇다면, 모델이 정답을 맞추는 데 실패하는 요인은 무엇일까? 논문에서는 이를 크게 5가지로 나눠 설명함.
(예시는 모두 그냥 이해를 돕기위해 자의적으로 작성된 것입니다)
① Domain knowledge deficit: 특정 도메인에 대한 정보 부족 (예- 흑백요리사를 보지 않은 내가 에드워드 리 쉐프님을 모르는 것)
② Outdated Information: 학습 이후에 일어난 일에 대한 정보 비습득 (예- 냉부 세대인 내가 아는 요리사는 최현석 쉐프님..뿐)
③ Immemorization: 학습 데이터 비중이 적어 모델이 인지하지 못하는 지식
④ Forgetting: Pre-training 이후 여러 단계의 fine-tuning을 거치면서 정보 손실 - catastrophic forgetting
⑤ Reasoning Failure: 비슷한 정보를 가지고 있지만, 복잡한 추론 과정으로 인한 유추 실패
3 Injecting Knowledge to Language Models
Section 2를 통해 pre-training만으로는 모델이 완벽할 수 없다는 걸 알 수 있음. 따라서, pre-trained 모델에 새롭게 지식을 부여하는 과정이 매우 중요함. 이 과정이 바로 "Knowledge Injection"
본 장에서는 2가지 주요 기법인 Fine-tuning (FT)과 RAG에 대해서 비교할 예정.
두 개념에 대해서 pre-trained된 독자라면 바로 Section4로 가십시다.
1. Fine-tuning (FT)
① Supervised FT (SFT) - 지도학습
- 정답 label을 주고 학습을 시키는 과정.
- 대표적인 것이 Instruction tuning
- Instruction tuning은 실제로 LLM 학습에 엄청 많이 사용됩니다. Instruction tuning을 통해 zero-shot, reasoning과 같은 능력을 향상 시킬 수 있기 때문이죠. 하지만, 아직까지도 해당 기법만으로 knowledge injection 문제를 모두 해결하는 것은 어렵다고 하네요 (아무래도 데이터 구축에 시간과 자원도 많이 들어가고 성능 향상에도 한계가 있기 때문이겠죠??)
② Reinforcement Learning (RL) - 강화학습
- RL의 대표적 방법으로는 Human Feedback 기반의 RLHF, DPO, PPO 등이 있습니다. 모두 사람의 선호를 모델에 주입하여 우리가 원하는 형태의 답변을 얻기 위한 방안이에요.
- 따라서, SFT와 마찬가지로 모델 답변의 질을 높이는데는 효과적이지만 모델이 가지고 있는 지식 자체를 확장하는데는 무리가 있는 것 같습니다.
③ Unsupervised FT (UFT) - 비지도 학습 - 본 논문에서는 이 방법을 이용했습니다 ★
- SFT와 달리 정답 label이 없음.
- Pre-training 과정의 연속으로 보는 경우도 많음.
- 하지만, 결국 pre-training이 먼저 이뤄지고 그 이후에 학습이 다시 진행되는 것이기 때문에 forgetting 문제에서 자유로울 수 없습니다. 이 단계에서 기껏 모델이 열심히 학습해 놓았던 이전 지식이나 능력이 사라질 수도 있어요. Pre-training을 연장한다는 개념에서 새로운 지식을 습득한다는 것은 굉장히 합리적? 논리적?인 방법이지만, forgetting과 같은 문제때문에 해당 기법이 새로운 지식을 습득하는데 얼마나 효과적인지는 잘 살펴봐야 할 문제입니다.
2. Retrieval Augmented Generation (RAG)
- RAG는 지식 집약적인 테스크가 주어졌을 때 LLM 모델의 능력을 확장시키는 기법.
- 어떠한 사전 학습 없이 주어진 데이터를 input에 context 형태로 넣어줬을 때, 모델이 충분히 이를 활용해 답을 할 수 있다는 내용입니다.
4 Knowledge Base Creation
모델의 평가는 2개의 데이터셋을 기반으로 진행.
1) Massively Multilingual Language Understanding (MMLU) Benchmark
- 해당 dataset에서 총 4가지 주제를 선택 (Anatomy, Astronomy, College biology, Prehistory)
- 최대한 reasoning이 아닌 사실에 근거한 주제들로 선택
- STEM field에만 국한되지 않도록 Prehistory도 함께 선택
2) Current Events Task
- LLM 모델이 새로운 지식을 얼마나 잘 습득하는지 확인하기 위한 데이터셋
- 최근 event (2023.08~2023.11 USA 관련)에 대한 질문과 질문에 따른 여러 선택지로 구성된 데이터셋
- 데이터는 Wikipedia를 통해 수집한 후, GPT-4를 통해 제작 → 910개의 데이터
2-1) Paraphrases Generation
- Current Event 데이터셋에 추가적으로 데이터 증강을 위해 제작한 데이터셋
- 마찬가지로 GPT-4를 활용해서 의미는 유지하면서 표현만 변화하여 제작한 데이터셋
5 Experiments and Results
1) 모델 선정 - SOTA 모델을 기준으로 선정
- LLama2-7B, Mistral-7B, Orac2-7B
- bge-large-en (embedding model for RAG)
2) 학습
- unsupervised fine-tuning 기법으로 진행.
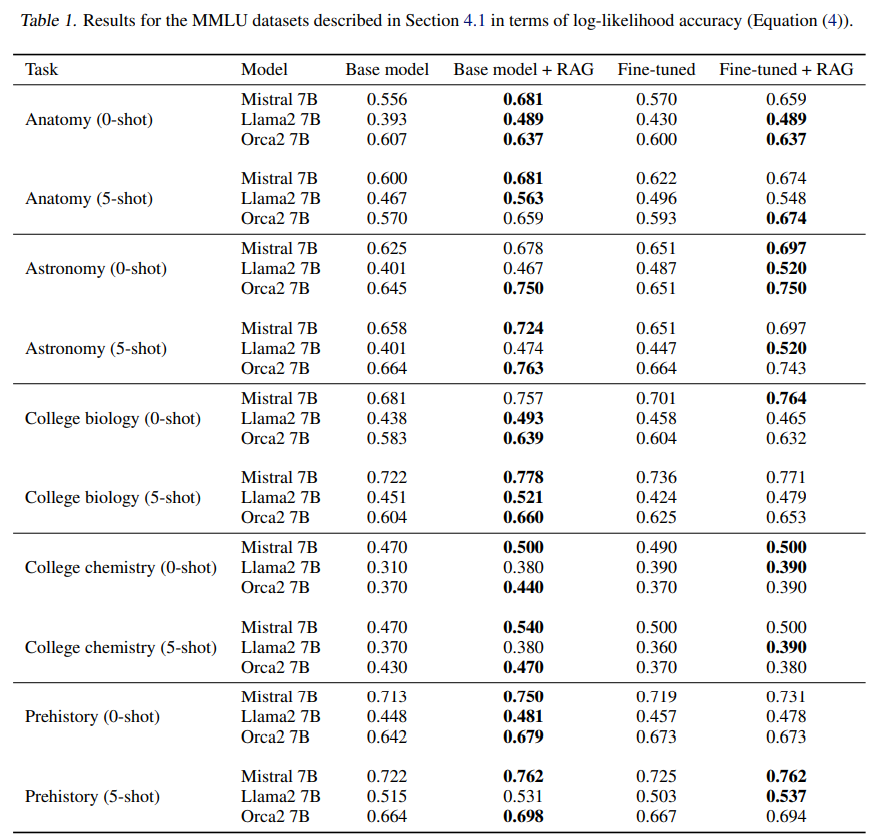
3) 결과
- 놀랍게도 FT 기법의 성능 향상이 RAG를 따라오지 못함.
- RAG가 거의 대부분의 task에서 높은 성능을 보임.
- Current Event에서는 RAG only 모델이 FT+RAG에 비해서 성능이 좋았음.
4) 해석
- 이런 결과가 나오는데는 몇 가지 이유가 있음. 일단 RAG는 FT에서는 주지 못하는 실제 지식을 모델에게 주입하게 됨.
- 또, FT 단계에서 catastrophic forgetting 문제가 발생했을 수 있음.

6 The Importance of Repetition
Current event 같은 경우, 기존의 정보와 달리 모델이 전혀 학습하지 않은 새로운 정보임. 따라서, 기존의 방식으로 동일하게 fine-tuning을 진행할 경우, 오히려 성능이 하락됨. 따라서, GPT-4를 활용해 먼저 데이터를 증강한 후, 학습에 사용함. 여기서 주목할만한 새로운 사실은
In order to teach pre-trained LLMs new knowledge, the knowledge must be repeated in numerous ways.

즉, 같은 데이터를 다양한 방식으로 모델에 주입해야 모델이 잘 학습한다는 얘기예요. 여기서 저는 정말 모델이 사람 같다고 생각했습니다. 사람도 뭔가를 처음 배울 때는 책도 찾아보고, 영상도 찾아보고, 당근과 토마토 블로그 글도 찾아보고(?)하는데 이 과정이 딱 그 과정같이 느껴졌거든요.
Conclustion과 Limitation은 본문과 겹치는 내용이 많아 이번에는 따로 적지 않겠습니다.
결국은 모델의 ICL 능력이 높아야 RAG의 성능이 더 좋은게 아닐까?
그런 의미에서 Fine-tuning, 그 중에서도 Instruction tuning은 정말 필요할 것 같은데,
어째서 Fine-tuning을 거치지 않은 모델이 더 성능이 좋게 나왔을까요?
Section 3을 읽을때까지 위와 같은 궁금증이 머리를 뒤덮었는데 그 이유를 section5에서 알게됐어요.
본 논문에서는 Instruction tuning은 진행하지 않았습니다!!!
그렇다면 Instruction tuning + RAG 와 RAG only 중에서는 어떤 것이 더 좋은 성능을 보일까요?
아직 연구를 하신 분이 없다면, 저 대신 제발 해주세요..!
