2024. 10. 15. 00:55ㆍPaper Review/Large Language Model (LLM)

Link: https://aclanthology.org/2024.findings-acl.958/
ACL2024 findings에 accept된 paper이다. Teacher-student model.. 모델의 distillation에서 자주 보던 용어다. 여기서도 같은 의미로 사용되는데 모델의 경량화와 함께 따라오는 학습 속도의 개선, 그러면서도 성능 유지를 위해서 이러한 방식을 채택한다. 이 논문에서는 data의 효율성을 위해 새로운 데이터의 수집 없이도 student 모델의 성능향상이 가능하다고 주장한다.
내용이 엄청 쉽지는 않았어서 나름 이해하기 쉽게 작성해봤습니다.
Distillation은 잘 모르는 분야기도 하고, 열심히 이해해봤는데 틀린 부분이 있을 수 있어요..ㅠㅠ
Abstract
Problem: LLM이 특정 task의 수행을 잘 하려면, high-quality의 학습 데이터가 필요하다. 하지만, 기존의 학습 및 데이터 개선 방법론들은 학습시키려는 모델, 즉 student 모델과 학습 데이터 간의 호환성을 충분히 고려하지 못하기 때문에 최적의 성능을 내지 못하는 경우가 많다.
Method: Teacher-student model 구조를 사용한다. Teacher model은 데이터를 개선하고, student 모델은 자신에게 맞는 데이터를 선택한다.
여기서 Reflection(반성)과 Introspection(성찰)을 통해 데이터의 개선을 자동화한다. (이 얼마나 학생에게 알맞은 자세인가! 하지만 이건 Teacher model 한다... Student model은 그저 학습에 도움이 되는 데이터만 선택해서 학습한다. 뭔가 잘못돌아가고 있는 요즘 세대를 반영한듯)
Result: Student model이 효율적으로 학습할 수 있다. 적은 데이터로도 좋은 성능을 낼 수 있고, 완전히 새로운 데이터의 수집 없이도 성능 향상이 가능하다.
즉, Teacher-student model의 collaboration을 통해 기존 데이터를 재활용 함으로써 더 적은 데이터로 더 높은 성능을 낼 수 있는 데이터 튜닝 방식을 제안한다!
Introduction
Instruction tuning이 뭔데?
이 부분은 아는 사람이 너무 많을 것 같아 필요한 분들만 보시면 될 것 같습니다..ㅎ
Instruction tuning은 LLM에서 요즘 가장 중요한 tuning 기법이다.
이게 뭐냐하면... 한 단계씩 설명해 보자!
LLM은 우선 pre-training을 진행하는 게 기본이다.
이건 대규모 text data로 학습을 해서 다양한 언어 패턴에 대해서도 학습하고, 이 과정에서 knowledge를 얻는 과정이다.
주로 BERT 계열 모델로 부르는 masked language model (MLM)은 보통 입력 sequence의 15%(BERT, RoBERTa 논문에서 가장 좋다고 하는 비율)를 [MASK] token으로 마스킹하고, 이 [MASK] token을 예측하는 학습 방법을 통해 pre-training을 진행한다.
- I love you. 라는 시퀀스에서 I [MASK] you. 로 love 라는 단어(여기서는 그냥 토큰을 단어라고 치자.)를 마스킹했다고 하면 모델은 이 love라는 단어(토큰)를 맞추게끔 학습하는 식으로 pre-training을 진행한다.
- 여기서도 마찬가지로 I love you. 라는 시퀀스에서 I love 까지 생성을 했다면, CLM에서는 I love 다음 토큰으로는 you. 가 올 것이라고 맞추게끔 pre-training을 진행한다.
그럼 이 Instruction-tuning은?
일반적으로 CLM 모델에 학습된다. Pre-training이 끝난 모델이 예측을 진행하면 그냥 계속 뒤에 나오는 토큰 맞추기만 할 뿐이다. 결국 pre-trained LLM (PLM, 여기서는 pre-trained CLM)은 지금까지 예측한 토큰 뒤에 나올 가장 높은 확률 값을 가지는 토큰을 출력해 줄 뿐.
- 간단한 예시로, 요약을 들어보자. 만약 Instruction tuning 전/후 모델에 '주어진 문장을 요약해줘. 오늘은 날씨가 너무 좋아서 율동공원에 산책을 갔다.' 라고 Input을 넣는다고 가정하면..
- Pre-training만 진행한 모델(Instruction tuning 이전): '그리고, 나는 여자친구랑 만나서 커피를 마셨다.'
- Instruction-tuning을 진행한 모델: '날씨가 좋아 산책을 갔다.'
나름 예시를 들어봤는데 이해가 될지 모르겠다. instruction-tuning 이전 모델은 instruction을 이해하지 못하고, 그냥 이전 토큰에 맞춰서 다음 문장을 완성할 뿐이고, instruction tuning 이후의 모델은 '주어진 문장을 요약해줘.' 라는 instruction을 이해하고, 문장을 요약하는 식.
즉, 사용자의 지시를 이해하고, 수행할 수 있도록 학습이 되어 사용자가 요구하는 task를 정확하게 처리할 수 있도록 해주는 학습방법이다.
그렇다면 기존 instruction tuning의 문제점은?
'데이터 품질'을 향상시키는 데에 초점을 맞추고 있다. 물론 중요하다. 그런데 데이터 자체의 품질에만 초점을 맞추고 있다.
이건 Student 모델의 학습 능력이 없으면 아무 쓸모가 없다. 조금 나쁘게 말하자면, 머리가 안좋은 학생한테 '숨마쿰라우데' 교재 가지고 가르쳐 봤자 아무 쓰잘데기가 없다는 말이다.
Teacher model이 데이터를 개선하더라도, 데이터가 Student 모델에 적합하지 않을 수 있고, 이는 성능 저하로 이어진다.
기존의 방법론들은 데이터의 무작위성이나 생성 모델의 출력에서 발생하는 quality의 저하를 간과할 수 있다. Student model이 학습해야하는 데이터가 '개선된' 데이터라고 할지라도, 성능을 높이는 데에는 항상 효과적이지는 않다는 말이다.
그럼 Selective Reflection-Tuning은?
Teacher model은 주어진 데이터에 대해서 Reflection(반성/반영)을 통해 데이터를 개선하고, student model은 이 데이터를 받아들일지에 대한 여부를 선택한다.
이러한 방식으로 Student model이 더 적합한 학습 데이터를 학습하기 때문에, 효율적인 데이터 튜닝과 성능 향상이 이루어진다.
어떤 데이터가 Student model에 필요하고, 중요한지를 student model이 결정한다. 즉, Teacher model이 개선한 데이터를 무조건적으로 사용하는 것이 아니라, Student model이 선택적으로 수용할 수 있는 방법이 필요하다!
이를 수행하기 위해서 논문에서는, Instruction-Following Difficulty (IFD) 라는 점수를 도입해서 데이터가 얼마나 도움이 되는지를 측정하고, Student model이 이러한 정보를 바탕으로 instruction이 어려운 데이터를 선택할 수 있도록 한다.
- 말하자면, 학생한테 문제를 줬을 때 얘가 얼마나 어버버버ㅓ 하면서 문제를 푸냐는 것인데... 'pneumonoultramicroscopicsilicovolcanoconiosis 번역해줘~'라고 하면 학생 모델은 '..?' 하면서 어버버하겠죠? 그럼 IFD 점수가 높아집니다. 'apple 번역해줘~' 하면 학생 모델이 '사과 ㅋ' 하면서 답하겠죠? 그럼 IFD 점수가 낮아지는 거에요. (쉬운 이해를 위한 다소 의역입니다.)
그리고 Reversed IFD (r-IFD) 라는 점수를 통해 Student model이 응답으로부터 지시를 얼마나 잘 유추할 수 있는지를 평가한다. 이 점수는 데이터의 Feasibility (실행가능성)을 나타낸다.
- 이건 반대로, 주어진 응답을 먼저 보고나서, instruction가 뭐였지? 하고 유추할 수 있는 정도에요. 다시 말해서 답을 먼저 봤을 때, 질문이 뭐였는지 쉽게 이해할 수 있으면, 낮은 r-IFD 점수가 나오죠. '날씨가 좋길래 산책을 갔어' 라는 응답에 대해서는 우리 학생이 '오늘 뭐했어?' 라는 instruction이 나왔다고 쉽게 생각하겠죠?
- 근데 'ㄴr는 ㄱr끔.. 눈물을 흘린ㄷㅏ...☆' 라는 응답이 나오면 instruction이 뭐였는지 도대체가 예측이 안될거에요. 그럼 r-IFD 점수가 높게 나오는 거죠. (얘도 쉬운 이해를 위한 다소 의역입니다.)
이렇게 IFD와 r-IFD는 데이터가 얼마나 어렵고, 실행가능한지를 평가하는 두가지 관점이다.
그래서 제안하는 방법은?
Selective Instruction Reflection: Teacher model이 기존 데이터의 지시문을 반영해서 더 나은 지시문을 생각하고, student model이 이 데이터를 수용할지에 대해서 결정한다.
Selective Response Reflection: Teacher model이 응답을 개선하고, Student model이 r-IFD 점수를 통해 적합성을 평가해서 데이터를 수용할지 결정한다. 선생님들만 힘드네..;
이러한 방식을 통해 데이터를 새로 수집하지 않고도 데이터의 품질을 높이고, Student model에 적합한 데이터만 선택적으로 학습하게 함으로써, 적은 양의 데이터로도 높은 성능을 달성할 수 있다!
Preliminaries
Student와 Teacher의 관계 설정
이건 학교에서 보는 상황과 비슷하다.
Teacher: 학생에게 문제를 던지고, 문제를 어떻게 풀어야 할지 힌트도 줄 수 있다.
Student: 선생님이 던져준 문제를 풀어보고, 풀린 문제에 맞는 답을 선택할지 결정한다.
Teacher model이 기존 데이터를 가지고, 새로운 문제 (instruction)을 만들어 내고, 문제의 답(response)를 학생에게 준다. 그럼 학생이 이 응답이 도움이 되는지 아닌지를 스스로 판단하고 선택적으로 학습한다. 여기서 학생이 스스로 선택하는 능력이 생기는 셈.
이제 수학 기호가 살짝 나온다. 긴장해봅시다.
$f_\theta(x)$ 는 학생이 $x$라는 문제를 받아서 어떻게 답($y$)를 내는지 설명하는 수식이다.
여기서 포인트는, 학생이 문제($x$)를 보고 어떻게 답($y$)를 만들어내는지를 설명하는데, 이걸 확률적으로 처리한다. 아까 설명한 CLM이다. 이전에 나온 토큰들을 기반으로 다음에 나올 토큰을 예측하는 식.
$f_\theta(x)=\prod_{i=1}^n f(x[i]|x[1,\dots,i-1])$
수식은 어렵게 써놨지만, $n-1$까지의 토큰을 이용해 $n$ token까지를 예측.
이제 학생이 얼마나 문제를 잘 풀었는지 봐야한다.
$L_{\theta}(y|x) = -\frac{1}{n} \sum_{i=1}^{n} \log f_{\theta}{(y|x)}$
$L_{\theta}(y|x)$: 이 수식은 Student model이 주어진 문제 ($x$)에 대해 얼마나 답($y$)을 잘 맞췄는지를 평가한다.
$\log f_{\theta}{(y|x)}$: 이 부분은 Student model이 얼마나 정확하게 답($y$)을 예측했는지 나타내는 수치이다. 모델이 답을 잘 맞출수록 이 값은 커지고, 틀리면 작아진다.
쉽게 말하면, 학생이 문제를 풀었는데 잘 풀면 이 점수가 낮고, 틀렸으면 이 점수는 높다.
목표는 이 점수를 최대한 낮추는 것! 모델이 배운 내용을 잘 풀도록 즉, 더 똑똑하게 만드는 게 손실함수(loss function)의 역할이니까...☆
여기서 슥 튀어나오는 IFD (나야.. IFD...)

$\text{IFD}_{\theta}(y|x)=\frac{\text{ppl}(y|x)}{\text{ppl}(y)}=\exp (L_\theta(y|x)-L_\theta(y))$
$\text{ppl}(y|x)$는 주어진 문제 ($x$)에 대해 답($y$)를 예측하는 난이도.
$\text{ppl}(y)$는 아무런 맥락 없이 답을 예측하는 난이도.
즉, IFD가 클수록 학생이 문제를 풀기 어려운 상황, instruction이 어려운 상황을 나타낸다.
흠.. 근데 이것만으론

ㅎㅎ... 사실 흑백요리사 다 못봤다.. 짤로만 봐도 재밌더라구요...
에드워드리 따라하다가 혼남 ㅠ

$\text{r-IFD}_{\theta}(x|y) = \frac{\text{ppl}(x|y')}{\text{ppl}(x)} = \exp(L_\theta(x|y')-L_\theta(x))$
이건 원래 preliminaries 보다 뒤에 나오는데 먼저 가져와 봤어유.
r-IFD는 주어진 답($y$)를 보고, 원래 문제($x$)를 얼마나 잘 유추할 수 있는가.
r-IFD가 낮으면 학생이 답을 보고, "아, 빠쓰 이 문제는 이런 거였구나!" 하고 쉽게 이해하는 상황을 뜻한다.
Methodology
그럼 selective reflection tuning은?
간단히 말하자면, 이 방법은 Teacher과 Student가 서로 협력하면서 데이터를 더 효율적으로 학습하게 만드는 방법이다.
Teacher는 데이터를 보고 reflection, introspection하면서 데이터를 개선하고, Student는 Teacher가 만든 데이터 중에서 자신에게 맞는 데이터만 선택해서 학습한다.
여기서 중요한 점은
- Teacher model은 데이터를 개선한다.
- Student는 그 데이터를 보고, 자신한테 맞는 것만 골라서 학습한다.
Reflection과 Introspection
지금까지 그래서 reflection이랑 introspection이 뭔데? 하시는 분들을 위해.. 드디어 나왔습니다.
소제목에선 따로 적어놨지만 reflection이나 introspection이나 비슷한 의미로 쓰입니다.
1. Selective Instruction Reflection
여기서는 Teacher model이 주어진 데이터를 보고, "이 데이터를 더 좋게 만들 방법이 없을까?" 하고 고민한다. 여기서 reflection은 Teacher가 data를 반영해서 더 나은 instruction을 생성한다. "이 문제는 이런식으로 바꾸면 더 나은 답을 얻겠지?" 하고 데이터를 개선하는 과정이다.
예를 들어보면, 오늘 날씨는 새벽엔 춥고 아침부터 저녁까진 선선했고, 밤엔 비가 왔는데 "오늘 날씨는 어때?" 라는 instruction을 주는 것보다, "흠.. 더 구체적으로 물어보면 답을 잘하겠지?" 하고 "오늘 아침부터 저녁까지 날씨는 어땠어?"라고 구체적으로 바꿔보면? 더 좋은 답이 나올 가능성이 높아진다.
2. Selective Response Reflection
여기서는 Teacher model이 instruction에 대한 response도 반영한다.
앞에서 질문을 "오늘 날씨가 어때?"라고 물어보면 "오늘은 선선했어~"라고 말한다고 해보자. 그럼 선생님은 "이 답이 충분히 좋을까?" 라는 질문을 던지고 다시 한 번 reflection 한다. (예를 들면, "새벽엔 춥고, 아침부터 저녁까진 선선했고, 밤엔 비가왔어" 라는 답이 가장 적절할테니.)
Teacher가 답을 개선하면 Student model은 개선된 답을 보고, 자신한테 맞는지 판단하고(ⓐ. 이 정도는 답할 수 있지! 혹은 ⓑ. 새벽.. 아침... 저녁.. 밤...@_@ 어려웡...), 적합한 데이터만 골라서 학습한다.
그럼 Student가 데이터를 선택하는 방법은? IFD & r-IFD
아까 최강록 셰프님, 백종원 셰프님과 같이 봤던 IFD, r-IFD가 다시 등장한다. 이 두가지는 Student model이 학습에 필요한 데이터를 선택하는데 중요한 역할을 한다.
- IFD(Instruction-Following Difficulty): "이 문제를 푸는게 얼마나 어려운가?"를 나타내는 score. 점수가 높으면 어려운 문제고, 낮으면 쉬운 문제
- r-IFD(Reversed IFD): "답을 보고 문제를 유추하는게 얼마나 쉬운가?"를 나타내는 score. r-IFD가 높으면, 아 이건 답을 봐도 못풀겠는데?, 낮으면 이 문제는 이거였구나! 하고 쉽게 이해할 수 있는 문제라는 뜻.
Student model은 IFD와 r-IFD 점수를 참고해서 가장 학습에 도움이 되는 데이터를 선택해서 학습한다. 너무 쉬운 데이터나 너무 어려운 데이터는 피하고, 적당~히 어려운 데이터를 골라서 효율적으로 학습할 수 있다!
*여기서 IFD가 높은 즉, 너무 어려운 데이터는 배제한다. 그리고 너무 쉬운 데이터는 배제할 수도 있다. 이건 모델에게 난이도를 조정해 주기 위해서. 너무 쉽거나 어려운 데이터는 학습 자체가 큰 의미가 없다고 판단.
그런데, r-IFD에서는 너무 어려운 데이터를 배제한다. 이는 instruction과 response 사이의 연관성을 쉽게 찾을 수 없기 때문에 모델이 학습하기해도 큰 의미가 없다(사견으로는 이상치의 느낌). 하지만, r-IFD 점수가 낮은 데이터는 그대로 학습한다. IFD에서 이미 어느정도 난이도 조절을 해줘서 문제를 푸는 데에는 조금 난이도가 있더라도, 문제를 유추하는건 쉬운 데이터는 그대로 학습시킨다.
모델의 학습 과정
다시 한 번 정리하자면...
- Teacher model이 데이터를 반영하고 reflection을 통해 더 나은 문제와 답안을 만들어 낸다.
- Student model은 위에서 만들어진 데이터를 보고 "이 문제와 답안이 내 학습에 도움이 될까?"를 판단한다.
- IFD와 r-IFD를 참고해 최적의 데이터를 선택해 학습에 사용한다.

위 그림은 지금까지 설명한 부분을 논문에서 설명한 그림이다.
결론적으로 Teacher과 Student model이 협력해서 더 적은 양의 데이터로 높은 성능을 내는 학습 방법을 만든 것! 학생이 수준에 맞는 교재를 골라서 공부하는 것처럼 필요한 데이터만 효율적으로 학습한다! (사실은 조금 똑똑한 학생이었나보다.)
Experimental Setup
교재를 선택보자! (Dataset)
- Alpaca Dataset: 52,002개의 instruction sample을 포함하는 데이터셋. text-davinci-003(by OpenAI)를 활용해 작성되었다. 이는 Teacher-student model의 효율성을 시험하는 기본 데이터셋으로 사용된다. 데이터 수집 없이 성능 향상이 가능한지를 확인한다.
- WizardLM datset: 약 250,000개의 instruction sample을 가지고 있는 데이터셋. GPT-3.5-turbo를 이용해 만들어졌다. 실험에서는 WizardLM-7B 하위 데이터셋을 선택해서 약 70,000개의 sample이 포함됐다. 이 데이터는 복잡한 지시문에서 모델이 어떻게 반응하는지를 확인한다.
Test를 보는 이유!
- Pair-wise Comparison: 모델이 생성한 출력들을 기존 모델의 출력들과 직접 비교하는 방식. 두 모델이 똑같은 문제를 풀었을 때 어느 쪽이 더 좋은 답을 냈는지 확인한다.
- AlpacaEval: 이건 Davinci003과 생성된 응답을 비교해주는 자동 평가 시스템이다. Teacher-Student 모델이 얼마나 지시사항을 잘 따랐는지 확인한다. (아래에 2번째로 나타나 있는 표 보면, Davinci003 model 이랑은 winrate가 0.5다. 나름 보면서 재밌었던 포인트)
- Open LLM Leaderboard: ARC, HellaSwag, MMLU, TruthfulQA 같은 다양한 태스크에서 모델이 성능을 얼마나 잘 발휘하는지 확인하는 벤치마크이다.
- MT-Bench: 단일 및 다중 대화(single/multi-turn dialogue)에서 모델이 얼마나 자연스럽고 적절하게 응답하는지 테스트한다.
시험보는 학생들은 WizardLM 13B, Alpaca7B model (sRecycled models.)
Experimental Results
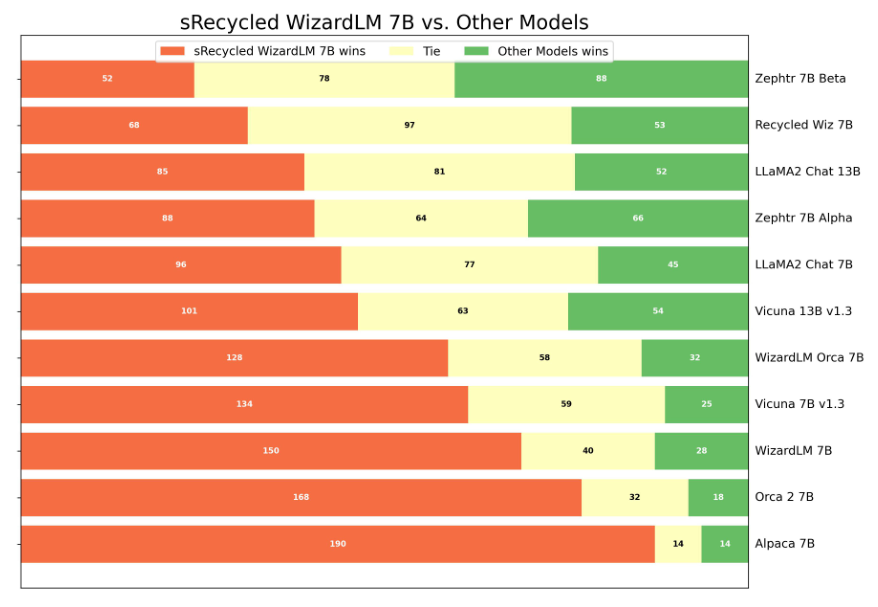




WOW 실험을 정말 많이 했다.
하지만 Distillation model답게 SOTA는 찍지 못한 모습. 하지만, 기존 distillation을 사용하지 않은 몇몇 모델들보다 동등하거나 그 이상의 성능을 보이고 있다.
잘 보면 Mistral 7B 기반으로 만들어진 Zephyr-7B 모델의 바이럴마케팅인가 싶다.
어쩌면 ACL regural paper가 아닌 findings에 들어간 이유가 이게 아닐까?
distillation 성능이 뛰어나다고 해도 같은 파라미터를 가진 7B 모델을 못이겨서... 아쉽다.
하지만 잘 깎은 pre-trained CLM이 있는 상태에서 꽤 높은 성능을 가진 distillation model을 뽑는 건 엄청 유의미한 성과인 것 같다. 갈수록 human-generated dataset도 부족해지고 cost-efficient tuning이 중요해지는 시점에서 시사하는 바가 큰 것 같다.
나 빼고 다 똒똒해
