2024. 10. 16. 17:58ㆍPaper Review/Large Language Model (LLM)
Gupta, A., Shirgaonkar, A., Balaguer, A. D. L., Silva, B., Holstein, D., Li, D., ... & Benara, V. (2024). RAG vs Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture. arXiv preprint arXiv:2401.08406.
https://arxiv.org/abs/2401.08406
RAG vs Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture
There are two common ways in which developers are incorporating proprietary and domain-specific data when building applications of Large Language Models (LLMs): Retrieval-Augmented Generation (RAG) and Fine-Tuning. RAG augments the prompt with the external
arxiv.org
찾았습니다. 제가 믿는걸 증명해 줄 사람.. Microsoft 더럽
이전 글에서 fine-tuning? 응 그거 아니야 이제는 RAG야!
해서 당혹스러움을 감출 수 없었는데.. 그래서 준비했습니다!
30페이지 가량의 논문이라 되도록 우리가 (아니 제가) 궁금했던 그래서? RAG? Fine-tuning? 둘다? 여기에 초점을 맞춰 리뷰를 진행하려고 했는데, 생각보다 논문의 내용이 모델별 비교 보다는 비교를 하기 위해 데이터셋을 구축하는 과정, 그 pipeline에 많이 치중되어있더라고요.
하지만, 그 pipeline도 꽤나 쓸모가 있는 것 같아 결국 길게 길게 리뷰를 하게 되었다는 그런 불편한 진실...
이번 리뷰에서도 개인적인 의견은 파란색으로 작성해보았습니다 (이건 열린 마음과 흐린 눈으로 봐주시면 좋을 것 같습니다^^)
Abstract
Large Language Model (LLM)을 개발할 때, 도메인 지식을 넣기 위한 두 가지 방법은 Retrieval-Augmented Generation (RAG)과 Fine-Tuning (FT)임. RAG가 prompt를 활용해서 외부지식을 넣는다면, FT는 모델 자체에 외부지식을 학습시키는 방식임. 하지만, 각각의 방식에 대한 장단점은 쉽게 이해가지 않음. 따라서, 본 논문은 Llama2-13B, GPT-3.5, GPT-4 등의 LLM을 활용하여 FT와 RAG 방식 각각의 pipeline을 제공하고 어떤 tradeoff가 발생하는지 살펴봄. 우리의 pipeline은 PDF에서 지식 추출 → 질의응답 생성 → FT에 이를 활용 → GPT-4를 활용한 평가 등 여러 단계로 작동함. Dataset으로는 농업 데이터를 활용함 (이는 농업 분야가 AI에 많이 활용되는 분야가 아니다보니 기존의 지식과 구별되기 때문). 추가로 이를 통해 본 논문에서 제작한 pipeline이 농부들에게 지역 특화 insight를 제공해 줄 수 있는지 실험했고, 결과 RAG와 FT 방법 모두 의미 있는 결과를 보여줌. FT를 진행했을 때, 약 6.6% 성능 향상이 있었고 이는 RAG를 함께 활용했을 때 성능 향상이 누적됨 (+ 5.5%). 또한, fine-tuning 기법을 통해 지역과 관련한 모델의 답변 일관성이 향상된 것을 보임 (47% → 72%).
1 Introduction
LLM 발달은 AI를 활용한 다양한 어플리케이션 개발로 이어짐. 대표적인 예로 AI Copilot은 다양한 산업 분야에서 활용됨. (MS 논문에서 copilot 이건 간접광고 느낌이 나는걸요, 하지만 일반적으로 AI Copilot은 사용자가 작업을 보다 효율적으로 수행하도록 지원하는 AI 기반 서비스라고 합니다.) 하지만, 농업과 같은 일부 분야에서는 학습 데이터셋의 부족으로 AI 활용이 더딤. GPT-4나 Bing과 같은 모델이 정보를 찾는데에 특화되어있는 모델이지만, 농부들이 궁금할 수 있는 작물이나 가축에 대한 정보는 잘 대답하지 못함. 실제로 GPT-4에 관련 질문을 했을 때, 전문가에 비해 전문성이 부족한 (평이한) 답변을 줌. 본 논문에서는 농업과 같이 전문적인 산업 분야에서 활용할 수 있는 AI copilot에 대해 소개함. 이를 위해 먼저 농업 데이터를 구축함. 이 농업 데이터는 이후 세 가지 용도로 사용됨. (1) 질의응답 생성 (2) RAG에 넣는 정보 (3) FT 프로세스 내 학습. 본 논문의 기여도는 아래 세 가지로 요약할 수 있음.
1) Comprehensive evaluation of LLMs
- 농업 관련 질문을 했을 때, LLM 모델에 대한 평가 (LlaMa2-13B, GPT-4, Vicuna)
- 평가는 fine-tuning과 RAG를 거친 후의 결과로 진행함.
- GPT-4가 가장 좋은 성능을 보임. (하지만, 학습 및 inference 비용 등도 고려하면 달라질 수 있음)
2) Impact of retrieval techniques and fine-tuning
- LLM의 성능 향상에 RAG와 fine-tuning 기법 모두 기여함.
- RAG의 경우, 관련 데이터를 잘 주입했을 경우 매우 좋은 성능을 보임.
- Fine-tuning의 경우, 모델에게 새로운 정보를 가르치는 차원에서 유용함. (하지만, 역시 학습 비용을 고려해야 함)
3) Implications for potential uses of LLMs in different industries
- 현재는농업 분야에 적용했지만, 다른 산업 분야로 확장 가능함.
2 Methodology
본 장에서는 도메인 관련 데이터를 구축하고 이를 어떻게 모델 개발 (RAG 및 FT)에 활용할 수 있는지 설명함.

2.1 Data Acquisition
- 농업과 관련된 전문지식 (정보) 수집.
- Scrapy, BeautifulSoup을 통한 웹 기반의 정보 수집.
2.2 PDF Information Extraction
- PDF 파일에서 구조적으로 정보를 추출하는 것은 쉽지 않음.
- 문서마다 양식이 통일되어 있지 않기 때문에 더 어려움. (table, images, sidebars, and page footers 등)
- Text extraction 툴과 머신 러닝 알고리즘을 활용하여 PDF에서 정보 추출을 진행함.
- 온라인에 PDF에서 정보를 추출하는 툴 (PDF2Text, PyPDF)이 있지만, 구조적으로 정보를 추출하지는 못함.
- pdf2text를 사용하면 문서에 작성된 텍스트 정보는 비교적 잘 가져오지만, 섹션과 서브섹션의 구분, 테이블이나 이미지의 캡션 등의 정보는 가져오지 못함.
- 따라서, 우리는 GROBID라는 머신 러닝 라이브러리를 사용함. (해당 라이브러리는 PDF형식으로 만들어진 과학적 문서에 특화된 모델)
- GROBID → TEI 파일 생성 (metadata, sections, tables, figure references 등의 정보를 담고 있음) → JSON 파일 형태로 변경 → content 뿐만 아니라 문서의 구조까지 저장할 수 있음.
2.3 Question Generation
- 추출된 문장에서 얼마나 의미있는 질문을 추출할 수 있을지에 집중.
- 이를 위해 Guidance framework 방법을 따름 (https://github.com/guidance-ai/guidance/tree/main).
- 문서 구조 및 내용을 보강하기 위해 텍스트에 관련 태그 추가.
- 본문과 주어진 태그를 바탕으로 질문을 생성함.
2.4 Answer Generation
① Embedding generation and index construction
- Sentence transformer를 활용해서 텍스트 chunk를 임베딩.
- 임베딩된 텍스트를 FAISS를 사용해 인덱스 데이터베이스에 저장.
② Retrieval
- 질문을 입력받으면, 해당 질문을 임베딩한 후 FAISS를 통해 관련 텍스트 chunk 검색 및 추출.
③ Answer generation
- 질문과 관련 chunk를 LLM 모델에 넣고 답변을 생성.
2.5 Fine-tuning
- LLaMa2-13b-chat 모델에 RAG 방식을 결합하여 질의응답 데이터셋 생성.
- 해당 데이터를 바탕으로 Open-Llama-3b, Llama2-7b, Llama2-13b 모델을 훈련.
- 모델들은 주어진 prompt와 질문을 바탕으로 답변을 생성하도록 함. (★이때, prompt 일부를 masking 함)
→ 여기서 말하는 fine-tuning은 앞서 소개드렸던 논문과 다르게 Instruction-tuning에 가까운 것 같아요. 근데 조금 특이했던 점은 prompt 일부를 마스킹 처리하는 거였어요. 이건 모델이 답변할 때, prompt를 복제하는 것을 방지하기 위함인 것 같아요.
*자세한 학습 기법은 논문 참고 바람 (분산학습, LoRA 등등 활용)
3 Dataset Overview
Fine-tuned 모델과 RAG의 성능을 평가하기 위해 구축된 데이터셋입니다.
하지만, 다른 내용과 크게 연관이 많은 부분은 아니라 필요하신 분만 읽어보셔도 될 것 같아요.
3.1 USA
- 23k PDF (50M tokens) 수집.
- Q&A pipeline을 통해 데이터 정제.
3.2 Brazil
- "500 Questions 500 Answers - Embrapa/SCT" 데이터셋 수집.
- 다양한 주제를 포괄하고 있는 데이터셋.

3.3 India
- 2015~2022년까지 100,000개의 농부들의 질문 수집 (Farmer advisory - KVK Q&A portal) + Vikaspedia.
- Azure의 번역기를 통해 영어 데이터셋 구축.
4 Metrics
Q&A pipeline이 실제 FT와 RAG에 어떤 영향을 주는지 평가하고자 함. 데이터의 질이 결국 모델의 성능을 결정하는 중요한 요소이기 때문.
4.1 Question Evaluation
좋은 질문이 뭔가?에 대한건 사람마다 다르기 때문에 이걸 객관적으로 평가하는 것은 매우 어려움.
따라서, 질문을 객관적으로 평가할 수 있는 지표를 개발.
① Relevance
- 실제 농부가 했을 것 같은 질문인지에 대해 GPT-4를 기반으로 1~5점의 점수를 주도록 함. (높을 수록 관련성이 높은 것)
② Global Relevance
- ①과의 차이는 주어진 context가 있는지, 없는지의 차이. Global Relevance의 경우, context가 없음.
③ Coverage
- 답변이 얼마나 주어진 context를 기반으로 나왔는지, 또 잘못된 정보는 없는지를 평가하는 항목.
(답변에 대한 얘기가 나와서 잘못된건가? 했는데, 여기서 context가 곧 질문인 것 같아요. 따라서 얼마나 유효한 질문을 했는지? 정도로 이해를 했습니다. 하지만 아무리 생각해도 뭔가 답변 평가에 있어야할 느낌적인 느낌.)
④ Overlap
- 생성된 질문과 source과 얼마나 겹치는지를 평가하는 항목.
- 평가 지표로는 Kullback-Leibler (KL) divergence를 사용함.
- KL Divergence가 낮으면 겹치는 내용이 많은건데, 이것이 이상적인 데이터셋.
⑤ Diversity
- Word Mover's Distance (WMD)를 활용하여 유사도 측정.
- WMD 값이 작으면 작을수록 겹치는 내용이 많은 것.
- 질문들간 WMD를 계산, 값이 클수록 겹치는 내용이 없다는 것이므로, 이상적인 데이터셋.
(+ 4번, 5번 항목의 경우, Semantic Textual Similarity (STS) 기법만 생각했었는데, KL Divergence의 개념을 가지고 오는 건 좋은 접근인 것 같아요. 나중에 시도해봐도 좋을 것 같아요. 하지만 WMD의 경우, embedding을 Word2Vec이나 GloVe로 하는데 이건 조금 outdated된 방법론인 것 같습니다. 오히려 LLM embedding을 사용하는 편이 훨씬 정확도가 높게 나오지 않을까하는 생각이 들었습니다.)
⑥ Details
- 토큰의 개수를 활용.
(이건 좋은 방법은 아닌것 같아요. 길다고 무조건 내용이 풍부한 건 아니니까요.)
⑦ Fluency
- GPT-4에 prompt를 기반으로 평가하게 함.
4.2 Answer Evaluation
LLM은 기본적으로 길고, 정보전달 위주, 대화체의 답변을 하는 경향이 있기 때문에 LLM이 생성한 답변을 평가하는 것은 쉽지 않음. 답변 평가에는 AzureML Model Evalutation을 활용함 (또...? 간접광고)
① Coherence
- 실제 진실과 예측된 답변이 얼마나 일치하는 지를 평가.
② Relevance
- 질문에 대해서 얼마나 잘 답변하고 있는지를 평가. (context를 기반으로)
③ Groundedness
- 주어진 context에 근거를 두고 논리적으로 답하고 있는지를 평가.
(3번과 4번 항목은 정말 코에 걸면 코걸이, 귀에 걸면 귀걸이인 느낌입니다. 몇 번을 읽어도 저에겐 뚜렷한 차이가 와닿지는 않았어요. 하지만, 의미상으로 relevance의 경우 질문과 관련된 답변인지, groundedness는 관련된 답을 하더라도 이게 정말 주어진 사실에 기반하는지, 환각 문제가 발생하지 않는지에 초점을 맞춘 평가 방법인 것 같아요.)
④ Completion
- 토큰의 개수
(Answer Evaluation의 Details와 일맥상통하는 내용인 것 같아요.)
4.3 Model Evaluation
Fine-tuning된 LLM을 평가하는 것은 쉽지 않음. 사람 평가는 비용이 많이 들기도 하고, 또 답변의 정확도는 전문가가 아니면 평가하기 어렵기 때문. 여러 fine-tuned 모델을 평가하기 위해 GPT-4를 사용함. 농업과 관련된 문건에서 270개의 질의응답 데이터셋을 생성한 후, 해당 질문에 대해서 fine-tuned 모델에게 답변을 생성하라고 시킴. 이 답변에 대해서 GPT-4가 평가하게 함. GPT-4 모델의 평가 일관성을 유지하기 위해 5번을 평가한 후 분산을 계산함.
① Evaluation with Guildline
- QA pair에 대해 GPT-4에게 올바른 답이면 반드시 포함해야 될 내용을 기반으로 가이드라인 작성을 시킴. 그 다음, 답변을 평가할 때 해당 가이드라인을 기반으로 해당 내용을 충족했을 때, 1 아니면 0으로 평가하게 함.

(이 정도면.. GPT-4 업무가 너무 많은거 아닌가요? GPT-4가 신이고 무적이라고 토마토가 늘상 얘기하긴 하지만, 뭔가 pipeline 구성이 전반적으로 너무 GPT-4 의존적이지 않은가 싶습니다.)
② Succinctness
- 간결한 답변과 장황한 답변에 대한 평가 sheet를 작성 후, 평가표, 정답 (ground truth 답변), 모델의 답변을 제공한 후, GPT-4에게 평가를 시킴 (1~5점).
(하지만 이 ground truth 답변이라는 것 역시 전문가의 답변이 아니라 GPT-4의 답변인데 LLM끼리의 답변 비교 아닌가요?)
③ Correctness
- 정확한 답변, 부분적으로 맞는 답변, 틀린 답변에 대한 정의를 평가 sheet로 작성 후, 마찬가지로 평가표, 정답, 모델의 답변을 제공한 후, GPT-4에게 평가를 시킴.
5 Experiments
실상 우리에게 필요한 내용은 앞선 섹션들에서 모두 언급이 되었기 때문에 필요한 부분들만 간결하게 언급하겠습니다.
보다 자세한 실험 결과가 궁금하시다면 본 논문을 참조하시면 좋을 것 같아요. 예시들을 정말 자세하게 작성해준 것이 이 논문은 장점이거덩요.
5.1 Q&A Quality Experiment
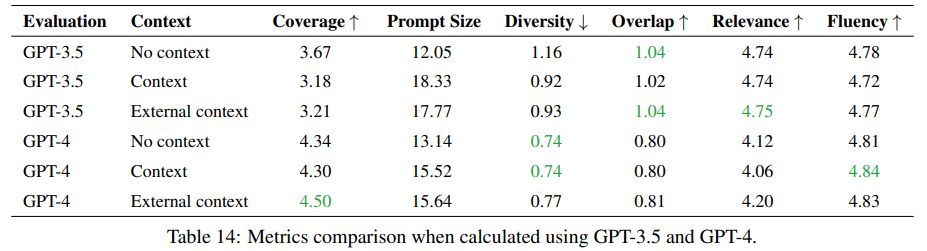
- GPT-3, 3.5, 4를 사용해 Q&A 데이터셋 품질을 검증.
- 검증 시, Section4에서 언급했던 여러 평가 metric을 사용.
- Context의 유무에 따른 Q&A 생성 능력을 평가함 (No context, Context, External context).
- No context 상황이 GPT-4를 활용해 Q&A 데이터셋을 생성할 때 가장 좋음. (여러 평가 지표를 고루 생각했을 때)
- 하지만, 어떤 답변을 생성할 것이냐에 따라서 달라질 수 있는 문제이고, 만약 prompt 길이에 제약을 받지 않는다라고 하면 external context가 더 좋은 대안이 될 수 있음.
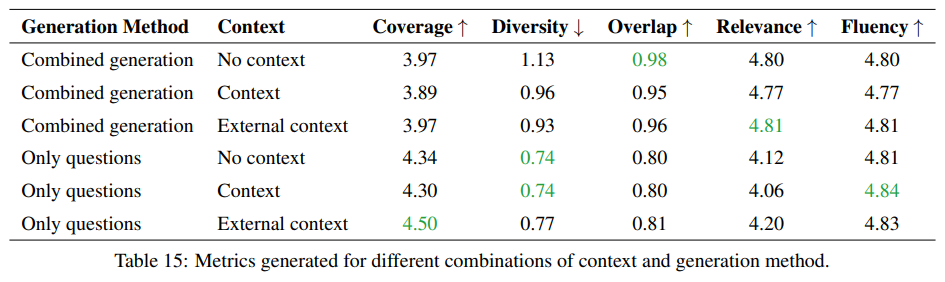
- Q&A 데이터셋을 생성할 때, 질문과 답변을 따로 생성하는게 좋은지, 함께 생성하는게 좋은지를 비교함.
- 결과, 평가 지표에 따라 조금씩 다른 결과를 보였기 때문에 원하는 task에 따라 방식을 달리하는 게 좋음.
5.2 Retrieval Ablation Study
- QA task에서 LLM이 기존에 가지고 있지 않은 지식을 RAG를 기반으로 주입하는 것은 모델 향상을 꾀할 수 있는 매우 좋은 방법임.
- 특히, 농업과 같은 분야는 연관성 있는 정보를 찾아 모델에 주는 것은 hallucination의 발생을 막고 농부들이 정말로 궁금해 할만한 정보를 전달 할 수 있기 때문에 활용도가 높음.
- 하지만, 모델의 성능 향상이 잘 이뤄지기 위해서는 유사한 문서를 잘 찾아서 전달하는 것이 중요함.
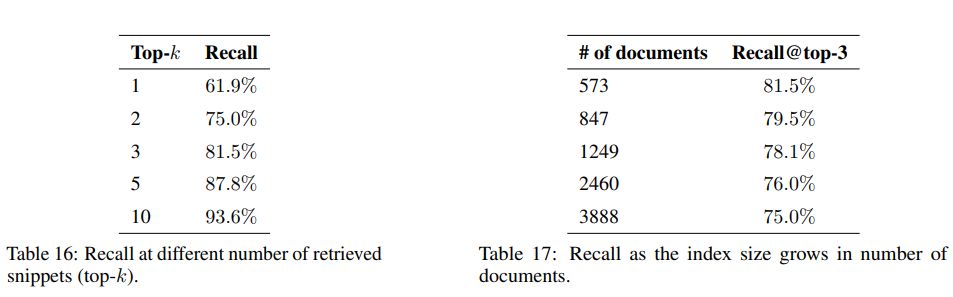
- RAG 모델이 얼마나 잘 문서를 찾아 전달하는지 능력을 검증하기 위한 평가 방식으로 recall 값을 사용함.
- top 3개의 문서를 살펴보는 것이 적절함. (80% 이상 정답 문건을 포함)
Q. Recall을 사용하는 이유?
A. Recall은 주로 classification 모델에서 사용하는 평가 지표 중 하나인데, Classification에서 Recall이란 실제 True인 것 중 모델이 True라고 예측한 것의 비율을 나타내죠. 이걸 retrieval 모델에 대입해서 생각해보면 실제 질문이 생성된 snippet (문단 단락) / True 을 retrieval 모델이 찾아낼 (True) 확률. 따라서, recall 값이 높을수록 retrieval 능력이 좋은 것! 이라고 생각하시면 됩니다.
Q. 그럼 k개의 수를 늘리면 되는거 아닌가요?
A. K - 즉, 살펴보는 문건의 개수가 늘어나면 늘어날 수록 당연히 원본 snippet을 포함할 확률도 올라가겠죠. 하지만 RAG는 결국 내가 찾은 문건을 답변 생성 시, input prompt로 넣어주게 됩니다. 그렇다면 늘어난 prompt에 대해서 비용이라던지 input text의 길이라던지 여러 제한이 생기게 돼요. 그래서 이 모든 것을 고루 고려해봤을 때, 3개가 가장 적절하다라고 논문에서 얘기하고 있어요. 실제로 살펴볼 문건이 엄청 늘어난다고 하더라도 3개를 살펴보면 평균적으로 75% 의 정확도를 보였습니다.
5.3 Fine-tuning
* 논문 리뷰가 산^넘어^산이 아닌 그냥 ^^^^^^ 산으로 가고 있어요. 분명 이 논문에서 말하는 fine-tuning은 Instruction-tuning 기법이다라고 지금까지 굳게 믿고 있었거든요. 왜냐면 그러기 위해서 QA셋을 생성하는 pipeline까지 소개했잖아요. 하지만, 5.3에서 갑자기 pre-training의 연장선 느낌의 fine-tuning 방법에 대해서 말하고 있어요. 그리고 정말 비교를 그렇게 도메인 학습이 된 fine-tuning 모델과 instruction-tuning이 된 base 모델 이렇게 합니다..????
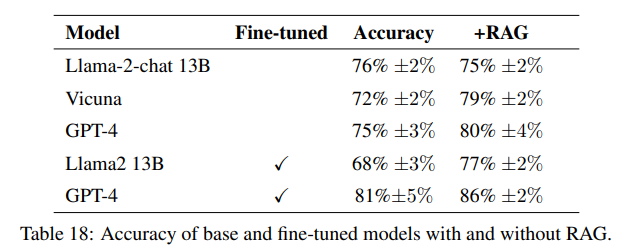
- Fine-tuned 모델 vs base instruction-tuned 모델과의 비교를 진행.
- Fine-tuning을 위해 Washington state dataset에서 질문만 추출 후, 2 million 토큰을 기반으로 fine-tuning을 진행.
5.4 Knowledge Discovery
- Fine-tuning을 진행했을 때, 모델이 새로운 지식을 학습하는 능력이 얼마나 향상되는지를 평가함.
- GPT-4만 사용했을 때는 47%, Fine-tuning을 진행했을 경우, 72%, RAG까지 사용했을 경우 74%까지 향상됨.
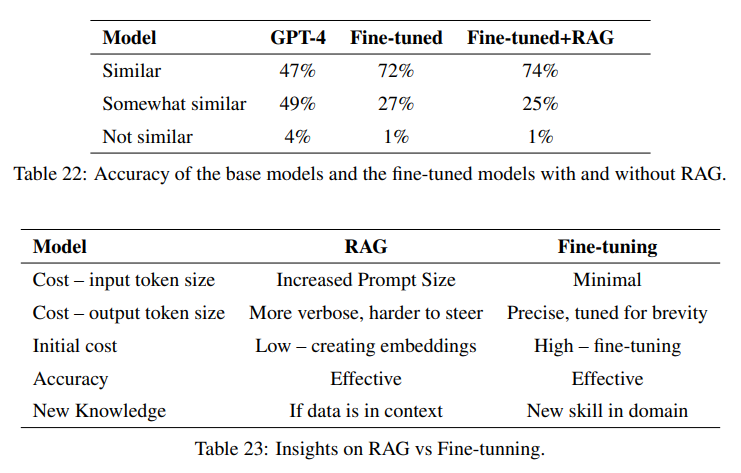
시작은 창대하였는데, 끝이 미미하다는게 이런 느낌일까요?
논문 내내 데이터셋은 주구장창 만들었는데 각 데이터셋을 어디서 어떻게 썼는지에 대한 설명이 너무 부족한 것 같습니다.
의욕 넘치게 일을 시작했다가 제 풀에 나가떨어지는 저를 보는 느낌이랄까요?
전체 데이터셋에 대한 Table이나 어떻게 쓰였는지에 대한 Table 등이 정리되어 있었다면, 훨씬 읽기 수월했을 것 같습니다.
이 논문에서 말하고자 하는 그니깐 "어떤 fine-tuning이 좋다!" 에 대해서는 도메인 지식을 학습한 모델인것까진 알겠는데,
그 방식이 Instruction-tuning인지 pre-training의 연장인지는 아직도 잘 모르겠어요. 정말 앞, 뒤가 달라진 느낌이거든요.
하지만, 그래도 어쨋든 fine-tuning도 의미가 있다!
앞선 논문과는 다른 결말입니다...
저는 해냈어요.
그런거예요.
