2025. 3. 19. 10:57ㆍPaper Review/Large Language Model (LLM)
Nie, S., Zhu, F., You, Z., Zhang, X., Ou, J., Hu, J., Zhou, J., Lin, Y., Wen, J., & Li, C. (2025). Large Language Diffusion Models.
https://arxiv.org/abs/2502.09992
Large Language Diffusion Models
Autoregressive models (ARMs) are widely regarded as the cornerstone of large language models (LLMs). We challenge this notion by introducing LLaDA, a diffusion model trained from scratch under the pre-training and supervised fine-tuning (SFT) paradigm. LLa
arxiv.org
장난으로 잠만 자고 일어나면, 그 다음날은 새로운 세상이다!
이렇게 말하곤 했는데, 장난이 아닐지도..?!
요즘은 정말 CV (Computer Vision), NLP (Natural Language Processing) 영역을 따로 가리지 않는 것 같습니다.
NLP에서 혁신적인 기술이었던 Transformer를 CV 분야에 적용하기도 하고,
또 Contrastive learning 같은 학습 기법을 생각해보면 본래 CV에서 쓰던 걸 NLP에 활용하기도 하고.
이번에 소개할 논문 역시 평소 CV에서 쓰이던 기술은 LLM (Large Language Model)에 적용해 본 사례입니다.
Abstract
자기회귀모델 (Autoregressive models, ARMs)은 LLM의 핵심으로 여겨져 왔습니다. 본 논문에서 소개하는 LLaDA는 이런 틀을 깨고 사전학습, 미세조정 단계 등에서 확산 모델을 사용합니다. LLaDA는 순방향 학습 시, 데이터를 마스킹하는 과정과 이렇게 마스킹된 데이터를 추론하는 역방향 과정을 통해 학습됩니다. 이렇게 학습된 LLaDA는 여러 벤치마크 데이터셋에서 우수한 성능을 보이며, 확산 모델이 자기회귀 모델(ARM)의 대안이 될 수 있음을 보입니다.
1 Introduction
(사실, 이 논문은 인트로를 이해하는게 너무 어려웠어요. 용어 대잔치..! 아마 이전에 자연스럽게 행해지는 대전제를 반박해야해서 더 그런게 아닐까? 싶습니다.)
LLM의 목표는 알려지지 않은 실제 언어 분포 를 모델이 표현하는 pθ(⋅)로 근사하는 것입니다. 이를 위해 최대우도추정 (Maximum Likelihood Estimation, MLE)를 통해 최적화하거나, 쿨백-라이블러 발산 (KL divergence)를 최소화하는 방식을 활용합니다. 현재 LLM은 다음 토큰을 예측하는 방식인 자기회귀 모델링을 통해 이를 달성하고 있고, 이게 가장 널리 쓰이는 방식이기도 합니다. 그럼 "자기회귀모델링 방식이 정말 LLM이 가장 좋은 성능을 보일 수 있는 유일한 방법일까?" (논문이 쓰여진 배경을 생각해보면 아니라고 생각하는 걸 느낄 수 있죠!) LLM은 결국 생성형 모델이기 때문에 알려지지 않은 실제 언어 분포 를 모델이 표현하는 pθ(⋅)로 근사를 잘 하면 되는데, 이걸 반드시 자기회귀 모델링으로써 달성할 필요가 있냐는 얘기입니다.
논문에서는 LLM의 가장 큰 기능 중 하나로 확장성 (scalability)를 이야기합니다. 여기서 확장성이란, 모델의 크기와 데이터가 커지면 커질수록 모델의 성능 역시 비례하여 증가하는 것을 의미합니다. LLM으로 모델이 계속해서 커지게 된 배경이라고 할 수 있죠. 하지만, 본 논문에서는 이러한 확장성이 자기회귀 모델링에 대한 결과가 아닌 트렌스포머 구조와 모델 및 데이터의 크기, 생성 모델링 원칙이 가져오는 피셔 일관성(Fisher consistency)간의 상호작용으로 비롯됐다고 합니다. 복잡하게 얘기하지만, 결국 자기회귀모델링이 아니더라도 확장성을 보일 수 있다는 의미로 해석돼요.
또한, 오히려 자기회귀 모델링으로 인해 발생하는 한계점을 말하는데요.
1. Next token predicition과 같이 데이터를 순차적으로 처리하기 때문에 역방향 추론 작업에서 성능이 떨어짐
2. 긴 길이의 텍스트나 복잡한 작업을 수행할 때, 연속적인 토큰 생성을 위해 막대한 계산 비용을 초래
본 논문에서는 이러한 점에 기반하여 사상 최초로 80억, 즉 8B 규모의 언어 확산 모델 LLaDA를 구축합니다. LLaDA는 2.3T의 토큰을 사용해 총 13만 시간의 H800 GPU 연산으로 처음부터 사전 학습 (pre-training) 되었고, 이후 450만 개의 지시문-응답 쌍(instruction-response pairs)을 활용하여 미세조정(SFT) 되었습니다. 그 결과, 다양한 벤치마크 데이터셋에서 우수한 성능을 보이는 것을 확인하였습니다.
2 Approach
(이 부분을 읽으면서 저는 개인적으로 기존 Masked Language Modeling (MLM) 학습 방식과 diffusion 방식에서의 MLM에서 많은 혼란이 왔습니다. 그래서 chatGPT4.5와 깊은 토론을 가졌고 일부 내용은 인터넷 검색 + chatGPT4.5 토론 끝에 내린 저만의 정의 방식이기 때문에 사실과 다를 수 있습니다. 더 좋은 견해가 있다면 제발 🙏🏻 알려주세요.)

2.1. Probabilistic Formulation
LLaDA는 순방향 (forward) 및 역방향 (reverse) 과정을 통해 모델 분포를 정의합니다. 순방향 과정에서는 데이터를 점진적으로 마스킹 처리하고, 반대로 역방향 과정에서는 마스킹 처리된 데이터를 복원하여 원본 데이터로 돌아갑니다. (마스킹 처리하는걸 노이즈를 더하는 관점으로 해석하면 본래 이미지에 노이즈를 추가하여 완전한 노이즈 이미지로 만들었다가 디노이징 과정을 통해 원본으로 회복하는 확산 모델의 원리를 이용하고 있는걸 알 수 있습니다.) 본 논문에서 밝히는 LLaDA의 핵심은 mask predictor 입니다. Mask predictor는 입력으로 부분적으로 마스킹된 텍스트 x(t)를 받아 한 번에 마스킹된 모든 토큰을 동시에 예측하는 모델입니다. 이 모델은 BERT 계열 모델에서 사용하는 MLM과는 차이를 보이는데, MLM 방식에서는 마스킹된 토큰을 비율을 고정했다면, 여기서는 0~1사이에서 무작위로 변한다는 것입니다. 이 부분이 모델의 확장성 측면에 큰 차이를 가져온다고 밝히고 있습니다. (단순히 머리속으로 그려보면, 학습 시, 고정된 숫자가 아닌 서로 다른 숫자의 토큰을 지속적으로 예측해야 하니, 보다 다양한 수준에서 학습을 하게되지 않을까 합니다. 모델을 시험을 보는 학생으로 가정해보면, 시험을 볼 때마다 출제 범위가 계속 달라지는 셈이니, 더 열심히 공부를 해야 정답을 맞출 수 있는게 아닐까요??)
2.2. Pre-training
해당 파트에서는 LLaDA가 사전 학습 단계에서 적용한 여러 방법론들이 언급됩니다. 저는 LLaDA를 직접 구현해 볼 예정은 없기 때문에 어떤 기법들이 적용 됐는지 간략하게 언급하고 넘어가보도록 할게요. 먼저, LLaDA의 마스킹 토큰 예측기에는 transformer 구조가 사용됩니다. 하지만 이전 LLM 모델과의 차이점은causal mask를 사용하지 않는 다는 점입니다. 토큰 예측에 이전 토큰뿐 아니라 전체 토큰을 보겠다는 의미입니다. Attention 방법으로는 vanilla multi-head attetion, 모델 크기 유지를 위해 feed-forward network (FFN), 학습 데이터에 맞게 조정된 tokenizer를 사용합니다. 이 외에도 데이터, 스케쥴러 등이 설명 되어 있는데 보다 자세한 사항은 논문에서 확인하시면 좋을 것 같아요.
2.3. Supervised Fine-Tuning (SFT)
마스킹 방식을 제외하고는 대부분의 방법론이 일반적인 LLM 학습 방법론과 매우 유사합니다. SFT도 마차가지인데, SFT는 페어링된 데이터 쌍 (p0, r0)을 이용하여 학습합니다. 여기서 p0는 프롬프트, r0는 응답을 의미합니다. SFT를 통해 LLaDA는 다른 언어 모델들처럼 명령어 (instruction)를 더 잘 따를 수 있도록 학습됩니다. 프롬프트와 응답이 모델의 입력으로 들어가 마스킹된 토큰을 예측하는 방식으로 학습이 되는데, 이때 사전 학습과의 차이는 마스킹 토큰은 응답에서만 랜덤한 비율로 발생하며 프롬프트에는 발생하지 않습니다.
2.4. Inference
이 부분이 파트 2에서 개인적으로 가장 중요하게 느껴졌습니다. LLaDA는 생성 모델로서 새로운 텍스트를 샘플링(sampling)할 수도 있고, 주어진 텍스트 후보가 얼마나 적합한지를 가능도(likelihood)로 평가할 수도 있습니다. (처음에는 '텍스트를 샘플링한다'는 표현이 낯설게 느껴졌지만, 생각해 보면 모델이 확률에 기반하여 단어를 하나씩 생성하고, 그 과정에서 여러 후보 중 하나를 선택하는 방식이기 때문에, 오히려 단순히 '생성한다'보다는 '샘플링한다'는 표현이 더 적합한 것 같다는 생각이 들었습니다.) 샘플링 과정은 모든 토큰이 마스킹된 상태(즉, 응답의 모든 토큰이 가려진 상태)에서 시작하여, 점진적으로 마스크를 해제하면서 최종 응답을 생성합니다. 샘플링 과정에서의 총 단계 수(sampling step)는 하이퍼파라미터입니다. 단계 수가 늘어나면 답변 생성 속도가 느려지지만, 대신 정확도는 향상되는 trade-off가 존재하기 때문입니다. 답변의 생성 길이 역시 하이퍼파라미터이지만, 논문에서는 이미 SFT 단계에서 다양한 길이의 답변을 학습했기 때문에 이 부분의 영향은 크지 않다고 설명하고 있습니다. 샘플링 과정의 중간에는 'remasking'이라는 새로운 개념이 등장합니다. (논문에서는 이를 "역방향 과정과 순방향 과정을 일치시켜 더 정확한 샘플링을 수행하도록 하는 것"이라고 표현하는데.. 이게 뭔소리냐구요. remasking이란 모델이 처음에는 모든 토큰이 마스킹된 상태에서 병렬적으로 동시에 여러 토큰을 예측한 후, 그 중 일부만 다시 마스킹하여 모델이 다시 예측할 기회를 주는 방법론입니다. 결과적으로, remasking을 하면 auto-regressive 방식처럼 모델이 다른 토큰들을 참조할 수 있는 기회가 점점 늘어나게 됩니다. 즉, remasking은 auto-regressive 방식과 마찬가지로 모델이 이전보다 더 정확히 다음 토큰을 예측할 수 있도록 도와주는 방법론이라고 이해할 수 있습니다. ) 논문에서는 실제로 remasking을 수행할 때 크게 두 가지 방법론을 제안합니다.
1. Low-confidence Remasking
- 모델이 예측한 토큰 중 확률이 가장 낮은, 즉 가장 자신 없는 토큰들을 다시 마스킹하여 재예측하도록 함
- 이를 통해 모델이 불확실한 예측을 다시 점검하고 최종 생성 품질을 높일 수 있음
2. Semi-autoregressive Remasking
- 전체 응답 문장을 여러 개의 블록으로 나누어 각 블록 내에서 왼쪽에서 오른쪽 방향으로 순차적으로 토큰을 생성함
Experiments
3.1. Scalability of LLaDA on Language Tasks
LLaDA 모델과 ARM 모델의 성능 비교를 위해 1B(10억) 파라미터 규모에서는 두 모델이 동일한 모델 구조, 데이터, 그리고 다른 모든 구성 요소를 공유하도록 했습니다. LLaDA와 ARM 모델의 전반적인 확장성(scalability)을 비교한 결과, LLaDA는 ARM과 비슷한 확장성을 보여줬습니다. 특히 MMLU나 GSM8K와 같은 일부 태스크에서는 LLaDA가 더욱 뛰어난 확장성을 나타냈습니다. 반면 PIQA와 같은 태스크에서는 성능이 뒤처졌으나, 규모가 커짐에 따라 그 격차가 점차 줄어드는 양상을 보였습니다.
3.2. Benckmark Results
약 2.3조(2.3T)의 토큰으로 사전 훈련(pretraining)을 마친 후, LLaDA 8B는 거의 모든 태스크에서 LLaMA2 7B를 능가했고, 전반적으로 LLaMA 계열 모델들과 비교해도 인상적인 성능을 보여줬습니다. 특히 MMLU나 GSM8K와 같은 일부 태스크에서는 더욱 뛰어난 성능을 보였습니다. 다만 PIQA 같은 일부 태스크에서는 상대적으로 성능이 뒤처졌지만, 여전히 성능 격차를 점점 줄이는 모습을 확인할 수 있었습니다. (LLaMA랑 비교했을땐 성능이 좋지만, Qwen2 모델에서는 낮은 성능을 보이는데 이것에 대한 설명은 없었어요... 그리고 조금 더 표를 자세히 들여다보면 사실상 mathematics & science 분야에서만 강한 성능을 보여줬지, 다른 task에서는 여전히 낮은 성능을 보이고 있습니다.)
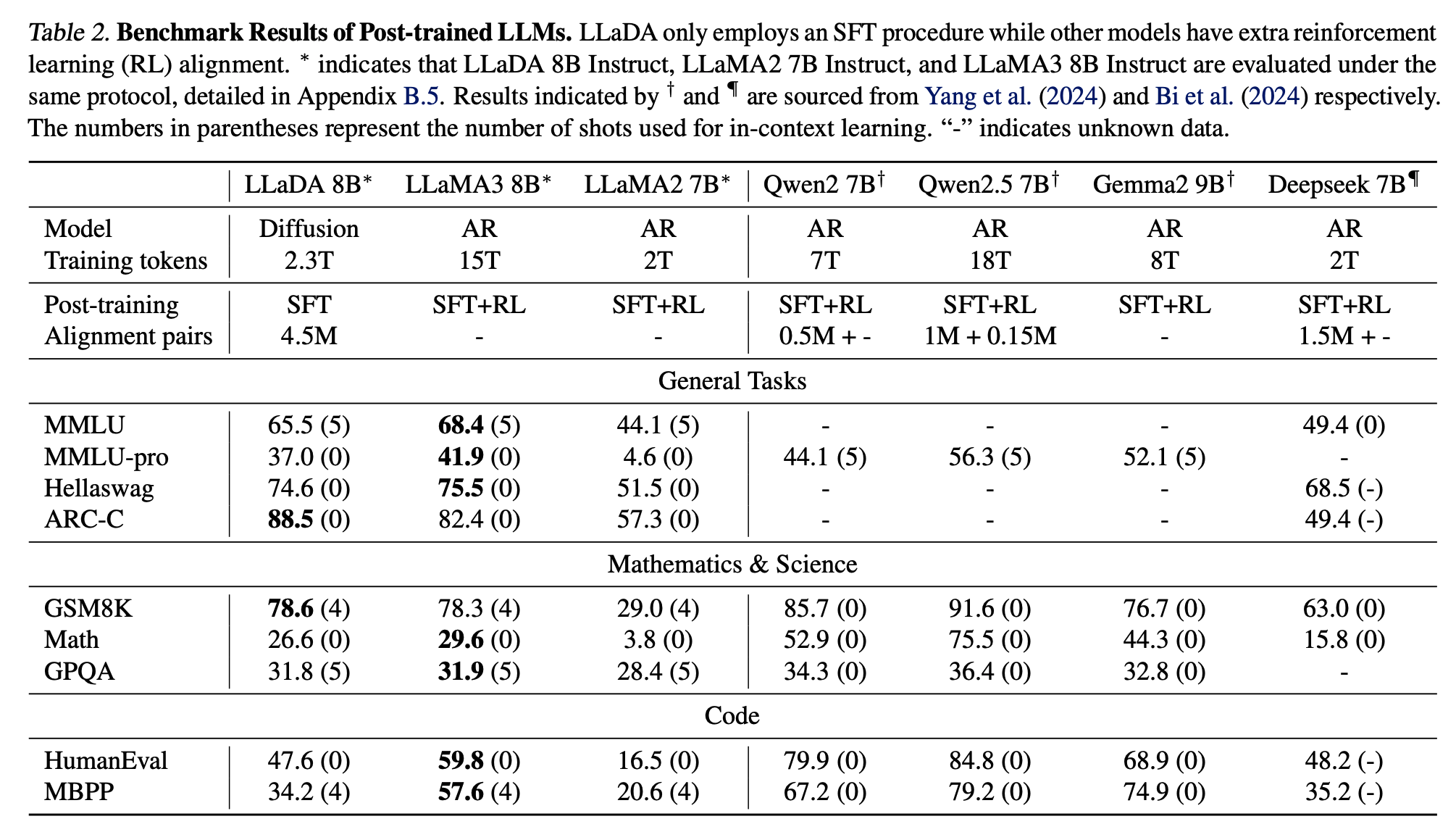
SFT 학습에서도 이전 결과와 크게 다른 모습은 아닙니다. 다만, MDM 모델의 경우 , Reinforcement Learning을 따로 진행하지 않았으니 이 부분이 추가된다면 더 성능이 좋아질수도 있다고 논문에서 언급하고 있어요.
3.3. Reverse Reasoning and Analyses
모델이 얼마나 역방향 추론을 잘 수행할 수 있는지 평가하기 위해 Allen-Zhu & Li(2023)의 방식을 따라 중국의 유명한 시 구절들을 이용한 데이터셋을 구축했습니다. 구체적으로 496개의 중국어 시 문장 쌍(sentence pairs)을 준비하고, 모델에게 다음 두 가지 작업을 수행하도록 요구했습니다.
- 순방향(forward): 주어진 시의 한 문장에 이어지는 다음 문장을 생성
- 역방향(reversal): 주어진 문장 이전에 위치한 문장을 역순으로 생성
이 실험에서는 별도의 추가 미세조정 없이 0-shot 방식으로 수행되었습니다. 실험 결과, LLaDA는 reversal curse를 효과적으로 해결하며, 순방향과 역방향 작업 모두에서 일관된 성능을 보였습니다. 반면, 자기회귀 방식(ARM)을 사용하는 대표 모델인 Qwen 2.5 및 GPT-4o의 경우, 순방향 작업에서 뛰어난 성능을 보였지만, 역방향 작업에서 성능이 현저히 떨어지는 모습을 보였습니다. (처음에는 모델이 생성 테스크를 수행하는데, 대체 역방향 추론이 왜 필요하지? 하는 생각을 했어요. 실제 상황에서 그럴일이 있나? 근데 생성 목적에서 보다도 모델이 어떤 글의 맥락을 더 잘 이해하는 관점에서는 중요할 수도 있다는 생각이 듭니다. 결국은 Natural Language Understanding (NLU)의 확장편이 아닌가하는 생각이 들었어요.)
이후 4, 5 파트에서 Related Works와 Conclusion이 나오는데 이 부분의 설명은 생략했습니다.
일단, Related Works에서 설명하는 다른 방식의 확산 모델(?)은 한 번 더 자세히 들여다보고 넘어가야 할 것 같긴한데, 설명이 너무 짧아 여기서 다루기에는 혼란만 가중 시킬 것 같더라고요. 쨋든 결론은 우리가 LLM 모델을 만드는데 자기회귀 모델링에만 국한될 필요가 있냐는 겁니다.
항상 남들이 하던 것만 따라하는 저에게는 큰 시련이네요.

Diffusion?
'Paper Review > Large Language Model (LLM)' 카테고리의 다른 글
| [논문리뷰] Simple and Effective Masked Diffusion Language Models (1) | 2025.03.21 |
|---|---|
| [논문리뷰] Likelihood-Based Diffusion Language Models (2) | 2025.03.21 |
| [논문리뷰] DeepSeek-V3 Technical Report (4) | 2025.02.04 |
| [논문리뷰] LoRA Learns Less and Forgets Less (1) | 2025.02.03 |
| [논문리뷰] Searching for Best Practices in Retrieval-Augmented Generation (1) | 2025.01.01 |