2025. 1. 1. 19:16ㆍPaper Review/Large Language Model (LLM)
Xiaohua Wang, Zhenghua Wang, Xuan Gao, Feiran Zhang, Yixin Wu, Zhibo Xu, Tianyuan Shi, Zhengyuan Wang, Shizheng Li, Qi Qian, Ruicheng Yin, Changze Lv, Xiaoqing Zheng, and Xuanjing Huang. 2024. Searching for best practices in retrieval-augmented generation. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 17716-17736, Miami, Florida, USA. Association for Computational Linguistics.
https://aclanthology.org/2024.emnlp-main.981/
Searching for Best Practices in Retrieval-Augmented Generation
Xiaohua Wang, Zhenghua Wang, Xuan Gao, Feiran Zhang, Yixin Wu, Zhibo Xu, Tianyuan Shi, Zhengyuan Wang, Shizheng Li, Qi Qian, Ruicheng Yin, Changze Lv, Xiaoqing Zheng, Xuanjing Huang. Proceedings of the 2024 Conference on Empirical Methods in Natural Langua
aclanthology.org
요즘 LLM에서 QA task를 진행할 때, RAG를 안쓰는건 정말 드물게 된 것 같아요.
그만큼 RAG System이 효율적이고, 기존 LLM의 부족한 점을 잘 보완한다는 뜻이겠죠?
오늘 리뷰할 논문은 EMNLP 2024에 발표된 논문으로, RAG system에서 구현 복잡성이랑 응답 시간 문제 등을 해결하기 위해서 다양한 방법론을 평가하고, 최적의 조합을 제안하는 논문이에요. 다양한 조합 따라서 최적화하는 게 뭔가 EMNLP 학회랑 굉장히 잘 어울리는 느낌이네요. 전반적으로 RAG가 돌아가는 시스템을 이해하고, 구성 요소들을 이해하기에 좋은 논문인 것 같아서 가져와 봤어요. 그럼 리뷰 들어가봅시다!
파란 글씨는 제 견해입니다! 그리고 파란글씨에 밑줄 쳐진 부분은 해당 사이트, 논문으로 이동할 수 있는 링크에요.
ABSTRACT
RAG 기술은 최신 정보를 통합하고, hallucination을 완화하며, 특히 전문 분야에서 응답 품질을 향상시키는데 효과적인 것으로 입증됨. 많은 RAG 접근법들이 query-dependent한 검색을 통해 LLM을 향상시키기 위해 제안되었지만, 이러한 접근법들은 여전히 복잡한 구현과 긴 응답시간이 문제가 됨. 일반적으로 RAG workflow는 여러 단계를 포함하며, 각 단계가 다양한 방식으로 실행될 수 있음. 이 논문에서는 기존 RAG 접근법과 그 잠재적 조합을 조사하여 최적의 RAG 실행방법을 파악함. 광범위한 실험을 통해 성능과 효율성을 모두 고려한 RAG 배포를 위한 전략을 제안함. 또한 multi-modal 검색이 시각적 입력에 대한 question-answering 기능을 크게 향상시키며, "retrieval as generation" 전략을 통해 multi-modal 콘텐츠 생성을 가속화할 수 있음을 입증함.
Codes and resources: https://github.com/FudanDNN-NLP/RAG
INTRODUCTION
LLM들의 전통적인 문제점은 크게 2가지 정도가 있는데요, hallucination이랑 모델이 학습하지 않은 최신 정보를 답변에 반영할 수 없다는 점이에요. (Jailbreak는 흠.. 전통..이라기보단 그나마 최근거죠?) 그래서 이런 문제를 해결하기 위에서 Retrieval Augmented Generation (검색증강생성) 즉, RAG 프레임워크를 발전시켜 왔어요.
검색증강생성의 장점은 생성형 LLM의 추가적인 학습 없이 최신 정보들이나 도메인 지식이 포함된 답변을 할 수 있다는 거에요. 대신 지식 데이터베이스에 답변하는데에 필요한 정보는 가지고 있어야겠죠?
Typical한 RAG의 process를 이 논문에서는 아래와 같이 이야기해요.
1. Query classification: 사용자가 입력한 쿼리가 retrieval이 필요한지 아닌지 분류
2. Retrieval: Query와 관련된 데이터 검색
3. Reranking: 검색된 documents들을 query와의 관련도로 재정렬
4. Repacking: 검색된 documents들을 더 나은 응답 생성을 위해 정형화된 하나의 문서로 결합
5. Summarization: Repacking된 문서에서 응답 생성을 위한 핵심 정보를 추출하고 중복을 제거
우와 단순히 쿼리 - 검색 - 생성으로 구성된 가장 simple한 RAG가 아니라 효율이랑 성능을 잡기 위한 요소들이 보이죠?
Query classification이 없다면 검색이 필요없는 쿼리에 대해서도 RAG를 적용하느라 답변속도가 길~어 질거고,
Reranking, Repacking, Summarization 과정이 없으면 RAG는 동작하더라도, 최적의 답변이 나오지 않게될 수 있겠죠?
이 논문에서는 추가적으로
- Chunking, Embedding, VectorDB, Fine-tuning LLM의 구성을 고려해요.

이걸 경험적으로 여러가지 조합을 실험해서 최적화를 했다는데.. 정말 대단한 사람들이에요.. 노가다...최적화는 3단계로 진행되었는데,
1. 각 RAG 단계 (모듈) 별로 대표적인 방법들을 비교하고, 가장 성능이 좋은 방법을 최대 3가지 선정
2. 개별 단계 별로 한 번에 하나의 방법을 테스트하여 각 방법이 전체 RAG 성능에 주는 영향을 평가 → 응답 생성 중 각 단계의 기여도와 다른 모듈과의 상호작용을 기반으로 가장 효과적인 방법 결정. 모듈에 가장 적합한 방법이 선택되면 후속 실험에 사용. Ablation study 느낌이라고 보시면 될 것 같습니다. 다른 요소들은 그대로 두고 위 그림에서 다른 모듈들은 고정하고, 하나의 모듈 안에서 다른 방법들을 선택해가면서 실험!
3. 성능보다 효율성이 우선시되거나, 반대의 경우가 발생할 수 있는 다양한 어플리케이션 시나리오에 적합한 몇가지 조합을 경험적으로 탐색
이렇게 3가지 단계로 최적화를 진행했다고 합니다.
Contributions:
1. 기존 RAG approach들을 조합해 최적의 RAG 조합을 찾아냄
2. General, specialized (domain-specific)한 RAG 모델들의 복합적인 평가 프레임워크와 데이터셋을 소개함
3. multi-modal retrieval 기술의 통합을 통해 visual 입력에 대한 Question-answering 기능을 높이고, 'retrieval as generation' 전략을 통해 multi-modal 컨텐츠의 생성 속도를 높일 수 있음을 보임. (아직 'retrieval as generation'에 대한 설명이 없어서 기대가 되는군요.)
RELATED WORKS
원래 논문리뷰할 때는 종종 선행연구 부분은 제외를 했었는데요, 이 논문을 리뷰하는 목적이 RAG system 전반에 대한 이해와 방법론들을 알아가는데 있기 때문에 오늘은 선행연구 부분에 리뷰를 해보도록 하겠습니당!
QUERY AND RETRIEVAL TRANSFORMATION
효과적인 검색을 수행하기 위해서는 정확하고 명확하며 상세한 쿼리가 필요하죠. 임베딩으로 변환된 경우에도 쿼리-관련 문서 간의 의미적 차이가 지속될 가능성이 있어요.
그래서 선행 연구들에서는 쿼리 변환을 통해서 쿼리 정보를 강화하고 검색 성능을 향상시키는 방법을 모색했습니다.
Query2Doc, HyDE (Hypothetical Document Embeddings) 는 원본 쿼리에서 pseudo-document를 생성해서 기존의 쿼리-문서 검색에서 문서-문서의 유사도 검색을 통해 검색 성능을 향상시키는 방법이고, TOC (Tree of Clarifications)는 쿼리를 하위 쿼리로 분해해서 검색된 컨텐츠를 합쳐서 최종 결과를 도출하는 방법이에요. 3가지 방법론 모두 ACL, EMNLP 학회에 발표된 방법론이에요. 한 번씩 읽어보시는 것도 좋을 것 같습니다!
또 다른 연구들은 검색 source 문서들을 변환하는데 중점을 두는데요, LlamaIndex는 너무 유명하죠? 이건 검색 문서에 대해서 pseudo-query를 생성하는 인터페이스를 제공해서 실제 쿼리와의 매칭을 개선해요. 대조학습을 사용해서 쿼리랑 문서 임베딩을 semantic 공간 내에서 더 가깝게 만드는 연구도 있어요.
그리고 검색된 문서들을 post-processing하는 연구도 있는데요, hierarchical prompt summarization, abstractive and extractive compressors 과 같은 기술을 이용해서 문맥 길이를 줄이고, 중복을 제거해서 생성되는 출력을 향상시키는 방법이 있어요.
RETRIEVER ENHANCEMENT STRATEGY
검색 성능을 높이기 위해서는 크게 2가지가 중요한데 하나는 chunking, 다른 하나는 embedding 이에요.
- Chunking: 너무 작은 chunks에서는 문장이 분해될 수 있고, 큰 chunks에서는 관련 없는 문맥을 포함할 수 있어요. 그래서 LlamaIndex에서는 sliding window, small2Big 같은 방법을 통해 chunking을 최적화해요.
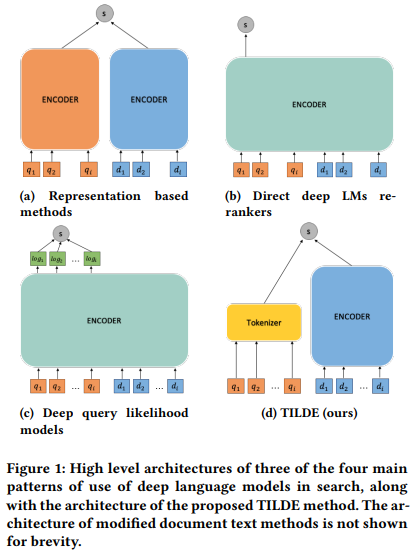
- Reranking: chunks가 검색되었다고 하더라도, 관계없는 chunks를 포함할 수도 있고, chunks의 수가 너무 많을 수도 있어요. 그래서 관련없는 문서를 걸러내기 위해서 reranking이 필요해요. 일반적으로 BERT나 T5를 통해서 진행하는데, 이 과정에서 전체 추론이 느려질 수 있겠죠? TILDE는 쿼리 용어의 유사도를 미리 계산하고 저장해서 합계에 따라 문서의 순위를 매겨서 효율적으로 reranking이 가능해요.
RETRIEVER AND GENERATOR FINE-TUNING
RAG framework에서 fine-tuning은 retriever, generator 모두에게 중요해요. 그 중 retriever context를 더 잘 활용할 수 있도록 generator를 fine-tune해서 일관적이고 강건한 컨텐츠를 생성할 수 있도록 해요. 또, retriever가 검색을 더 잘하도록 학습하는 방법도 있죠.
Holistic approach (전체론적 접근방식. Retriver과 generator를 따로 두고 각각의 성능을 높이는 방식이 아니라 두 모델의 상호작용을 고려해서 학습해서 RAG system 전체의 성능을 높이는 방식을 뜻하는 것 같습니다.) 는 복잡성과 모델의 통합 문제가 존재하지만, retriever과 generator를 함께 fine-tune해서 전반적인 성능을 향상시키는 방법론이에요.
이 논문에서는 여러 survey paper에서 텍스트 생성부터 LLM과의 통합, multi-modal, AI 생성 컨텐츠와 같이 RAG system에 대해 광범위하게 논의하고 있지만, 구현에 적합한 알고리즘을 선택하는 게 아직은 어렵기 때문에 최적화를 진행했다고 합니다.
RAG WORKFLOW
여기부터 논문의 핵심이라 보시면 될 것 같습니다. 지금부터는 RAG Workflow의 구성요소에 대한 설명과 모듈에서 일반적으로 사용되는 접근방식, 그리고 최종 파이프라인을 위한 기본 방법론과 대체 방법론에 대해 선택해요. 데이터셋이나 실험 결과는 Appendix에 있으나 이 리뷰에서는 일부 제외하고 리뷰하도록 하겠습니다. 물론 필요한 부분은 포함할 거에요! 글이 너무 길어져요..힘드러... Evaluation이나 데이터셋에 관심이 있는 분들은 글 맨 위에 링크 통해서 논문을 확인하시는 걸 매우매우 추천드립니다! 쓸만한 게 많아요 정말.
QUERY CLASSIFICATION
Query classification은 사용자 입력 쿼리가 RAG, 더 자세히는 retrieval이 필요한 쿼리인지 아닌지 분류하는 과정이에요. 이 과정이 필요한 이유는 LLM도 내부적으로 어느정도의 질문에 대해서는 대답할 수 있는 능력을 가지고 있기 때문이죠. (챗봇이랑 대화를 시작할 때, '안녕하세요', '너는 어디까지 대답할 수 있어?' 와 같은 질문들은 retrieval 없이 LLM에 프롬프트 설정만 해놨어도 충분히 답할 수 있는 것들이라 굳이 retrieval이랑 그 후속 과정에 cost를 쓰지 않고 빨리빨리 대답할 수 있도록 한다는 거에요.)
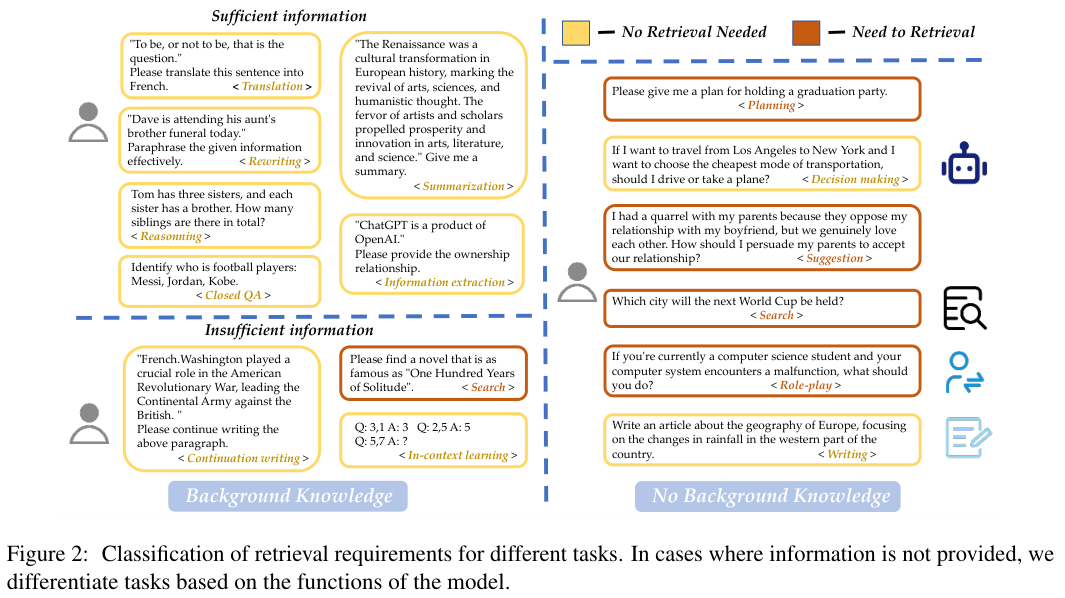
논문에서는 충분한 정보를 제공하는지 여부에 따라서 15가지 작업으로 분류를 했다고 합니다. 위에 < > 안에 있는 Translation, Rewriting, ... 이에요. 그래서 이 15개의 task를 포함하는 111K개의 데이터셋을 만들어서 64K개의 sample은 'Need to Retrieval', 47K개의 sample은 'No Retrieval Needed'로 라벨링해서 classifier를 학습시켰다고 하네요.
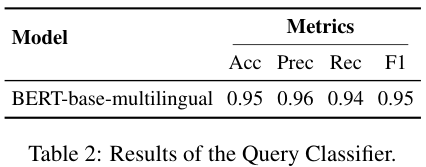
논문에 따르면, BERT-base-multilingual을 base model로 선택했다고 하는데, 흠.. 무거운 모델들은 좀 제외된 것 같죠? 후보군은 따로 표기하지 않았네요.
CHUNKING
다음은 chunking입니다. 문서 텍스트를 작은 단위로 분할하는 것을 뜻하는데, chunking하는 이유는 검색 정확도의 향상과 LLM의 length issue를 피하기 위해서에요. 논문에서는 chunking을 3개로 분류하고 있어요.
1. Token-level chunking: 간단하지만, 문장이 깨질 수 있어서 검색 수준에 영향을 미칠 수 있음.
2. Semantic-level Chunking: LLM을 사용해 breakpoiunts를 결정하고, context를 보존할 수 있지만, 시간이 오래 걸림.
3. Sentence-level Chunking: 텍스트의 의미 보존과 단순성과 효율성 사이의 균형.
이 연구에서는 sentence-level chunking으로 간단함과 의미 보존의 밸런스를 잡았다고 합니다. (저도 실험해봤는데 semantic chunking은 LLM으로 유사도 측정하면서 chunking하는 과정이라 오~래 걸렸던 기억이 있네요. Sentence-level chunking 중에 recursive chunking 기법 사용하면 어느정도 효율적으로 가져갈 수 있었어요. 제 블로그 글 중에 chunking 관련해서 정리한 적이 있었어요. 링크는 여기!)
추가적으로 이 논문에서는 4가지 측면에서 chunking을 추가로 세분화했어요.
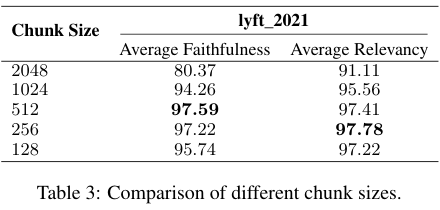
Chunk Size: 큰 chunk size에서는 context를 유지할 수 있지만 불필요한 정보가 포함되거나 작업 처리시간이 길어져요. 하지만 작은 chunk size에서는 검색의 recall이 향상되고 시간은 단축되지만 충분한 context를 포함하지 못할 수 있어요. 평가는 faithfulness / relevancy인데, 최종답변에 hallucination이 없는지와 검색된 텍스트와 잘 맞는지 / 검색된 텍스트가 쿼리와 맞는지 를 평가했어요. 512랑 256 chunk size가 각각 지표에서 제일 좋은 성능을 기록했네요.

Chunking Techniques: related works 부분에서 설명한 Small2Big, Sliding Window 방식을 사용하면, 작은 block을 query matching을 시켜서 검색 성능을 올리고 주변 blocks를 포함시켜서 추가 context를 넣어줄 수 있어요. 위의 chunk size와 같은 지표로 평가했는데, sliding window 방식이 제일 성능이 좋았네요.
Metadata Addition: Chunk block에 추가로 titles, keywords, hypothetical questions와 같은 metadata를 달아주면, 검색 성능이 향상 될 수 있어요. 검색된 텍스트에 대해 추가적인 post-processing이 가능해지고, LLM에게 검색된 정보를 더 잘 이해할 수 있게 해주는 정보를 주는거에요. 이 논문에서는 실험하지 못해서 future work에 포함시킨다고 해요.
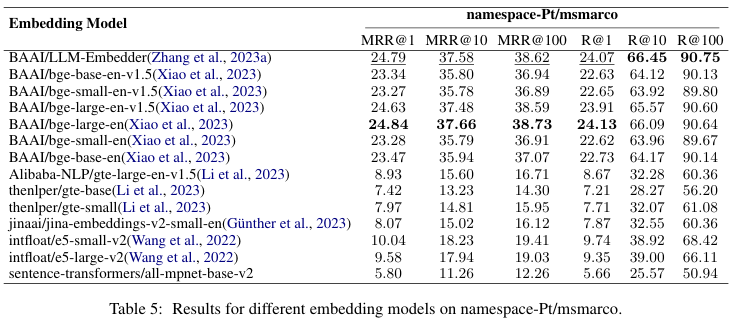
Embedding Model: 사실 엄청 중요한 건 이거라고 생각해요. 제가 좋아하는 연구 분야기도 하구요! 올바른 임베딩 모델을 선정해야 query와 chunk block 사이의 의미론적 검색을 잘! 할 수 있어요. FlagEmbedding의 evaluation module을 사용해서 평가했고, 최종적으로 LLM-Embedder 모델을 선택했다고 합니다. 임베딩 모델 선정 기준은 Recall인 것 같네요. 평가지표에 대한 설명은 여기! 여기서 사용한 데이터셋을 한국어로 번역하고 모델들 평가한 게 있는데 궁금하신 분은 여기로!
VECTOR DATABASE
Vector database, 즉 vectorDB는 임베딩 벡터들을 metadata와 함께 저장해서 쿼리를 이용해서 효율적인 검색을 가능하게 해요. Indexing이랑 approximate nearest neighbor (ANN) 방식을 이용해서 말이죠.
이 논문에서는 vectorDB를 4가지 측면에서 평가했어요.
1. Multiple Index Types: 다양한 데이터 특성과 사용 사례마다 검색을 최적화할 수 있는 유연성.
2. Billion-scale Vector Support: LLM 어플리케이션에서 중요한 대규모 데이터 처리.
3. Hybrid Search: Vector 검색과 Keyword 검색을 결합한 검색 정확도 향상.
4. Cloud-native Capabilities: 클라우드 환경에서의 원활한 통합, 확장성, 관리.
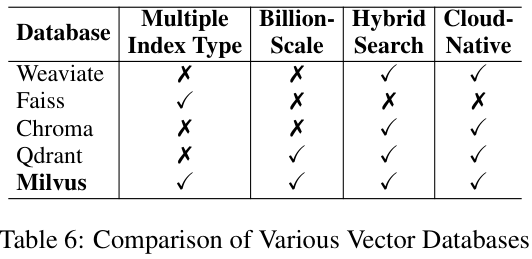
평가는 꽤나 간단하게 진행했어요. 각각의 측면에서 지원하는지 하지 않는지를 통해서 평가했네요. 모든 요소를 충족하는 Milvus가 사용하기에 가장 괜찮겠죠? 근데 전 Faiss도 좋아요.. 나름 괜찮아요..
RETRIEVAL METHODS
Retrieval은 user query가 들어오면, query와 data사이의 유사도를 계산해서 top-
1. Query Rewriting: 관련 문서와 더 잘 일치하도록 쿼리 개선. Rewrite-retrieve-read framework에서 영감을 받아 성능 향상을 위해 LLM이 쿼리를 재작성하도록 유도.
2. Query Decomposition: 원래 쿼리에서 파생된 하위 쿼리를 기반으로 문서를 검색. 이해하고 처리하기 더 복잡함.
3. Pseudo-documents Generation: 사용자 쿼리를 기반으로 pseudo-document를 생성하고 생성된 문서의 임베딩을 사용하여 유사한 문서를 검색 (related works 섹션의 HyDE를 참고해주세요!)
또 최근 연구에서는 벡터 기반의 검색과 키워드 기반의 검색을 결합하면 성능을 높일 수 있다고 합니다. Ensemble Retrieval / Hybrid Retrieval 이라고 많이 하죠. 그래서 이 논문에서는 LLM-Embedder에 query transformation 3가지를 적용하는 방식과 Hybrid Search를 결합한 방식을 모두 evaluation 했네요.
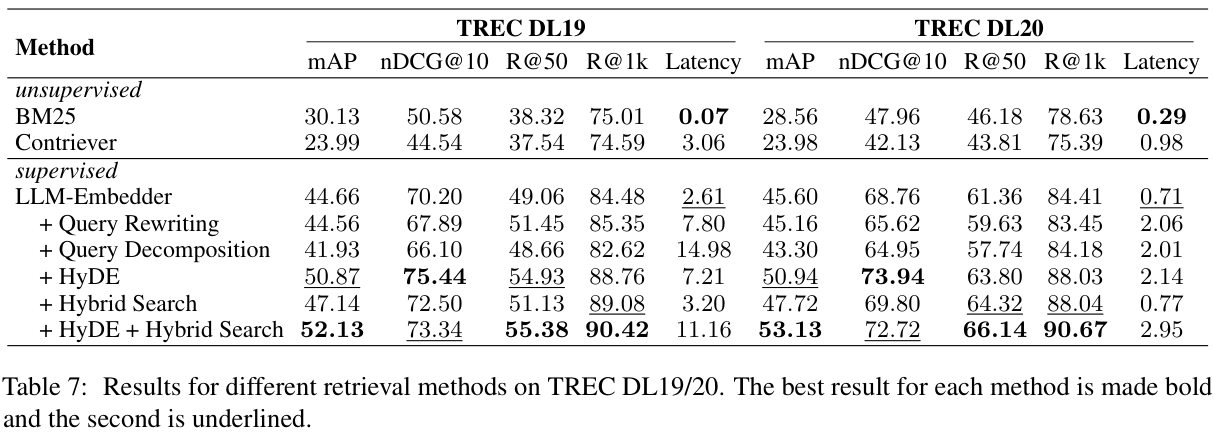
Retrieval 평가에서는 HyDE 방식과 Hybrid Search를 결합한 방식이 가장 높은 성능을 보였습니다. query rewriting이나 decomposition은 오히려 성능이 좀 떨어지는 모습을 보이네요.
RERANKING METHODS
Retrieval을 진행한 후에 검색된 문서의 관련성을 더욱 높이기 위해서 reranking을 진행해요. Reranking을 통해서 가장 관련성이 높은 정보를 상단에 위치하게 하는 것이고, Reranking이 잘 될수록 쿼리와 최상위 문서 간 유사성이 높아지는거죠.
Reranking에서는 크게 2가지 접근 방식을 평가했어요.
DLM: Deep Language Model (DLM)을 활용하는 방식으로 대표적인 reranker에요. 효율성은 조금 떨어질 수 있지만, 일반적으로 가장 좋은 성능을 보인다고 해요. 모델은 쿼리-후보 문서의 관련성을 기반으로 True or False로 예측하도록 fine-tune 돼요. 쿼리-문서 입력에 True/False classification task를 학습하는거죠. 추론할 때는 True 확률 값에 따라 문서의 순위를 매기는 거에요.
TILDE: 기존의 query liklihood model은 이전 토큰의 확률을 기반으로 쿼리 term의 조건부 확률을 계산하지만, 효율성이 떨어져요. 그래서 TILDE는 각 쿼리의 term을 독립적으로 고려하고 전체 어휘에 걸쳐서 토큰의 확률을 예측해요. 인덱싱 할 때 사전 처리된 후보 문서를 사용해 각 문서의 쿼리 토큰에 해당하는 사전에 계산된 로그 확률을 합산해서 빠른 reranking을 수행해요. TILDE v2에서는 문서에 존재하는 토큰만 인덱싱하고, NCE loss와 문서확장을 사용해서 효율성은 올리고, 인덱스 크기는 줄였어요.
논문에서 실험은 MS MARCO Passage ranking dataset을 사용해서 평가되었어요. PyGaggle과 TILDE에서 제공하는 구현을 일부 수정해서 진행했다고 하네요. monoT5, monoBERT, RankLLaMA, TILDE v2 모델을 비교했습니다.
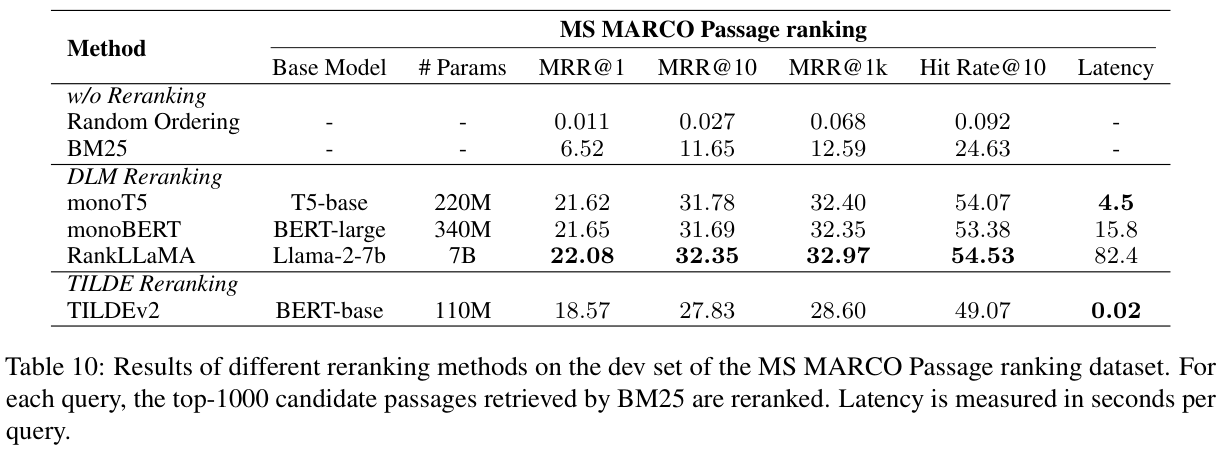
RankLLaMA는 성능면에서 가장 높고, TILDE v2는 속도면에서 가장 좋은 성능을 보였네요. 논문에서는 속도와 성능의 균형 잡힌 모델을 monoT5 정도라고 이야기하고 있어요. monoBERT 성능이랑 비슷한데 시간차이 (Latency) 가 심하긴 하네요.
DOCUMENT REPACKING
다음은 Document Repacking인데요, LLM에 제공되는 문서의 순서가 response에 영향을 줄 수 있어요. 그래서 reranking 이후에 repacking을 진행하고 LLM input으로 넘겨주는 거에요. 논문에서는 3가지 방식을 실험했어요.
Forward: Reranking 단계에서의 관련성 점수를 기반으로 내림차순 정렬
Reverse: 관련성 점수를 기반으로 오름차순 정렬
Sides: 관련 정보가 입력의 앞이나 뒤에 배치 (이건 LLM이 입력 내부에 정보를 처리하는 과정에서 입력의 앞쪽, 뒤쪽에 있는 정보를 입력의 가운데에 있는 정보보다 잘 기억하고 처리하기 때문에 앞 뒤에 순위가 높은 정보를 배치하는 거에요. 관련 논문은 여기!)

Repacking은 후속 모듈에 영향을 미치기 때문에 이 섹션에서 평가는 하지 않고, Section 4에서 진행한 evaluation table을 가져와 봤어요. 논문에서는 기본 repacking 방법으로 "Sides" 방법을 선택했다고 하네요. 근데 reverse 성능이 꽤나 좋아보이죠?
SUMMARIZATION
LLM에 입력하는 프롬프트가 길면, 추론 과정이 느려질 수 있고, 검색된 문서에 중복이나 불필요한 정보가 포함되면, LLM이 정확한 응답을 생성하지 못할 수 있어요. 그래서! 검색된 문서를 요약하는 효율적인 방법이 RAG 프로세스에서는 중요해요. 요약은 일반적으로 extractive summary, abstractive summary로 구분돼요. Extractive summary는 텍스트를 문장으로 분할한 다음에 중요도에 따라서 점수를 매기고 순위를 매기는 거에요. Abstractive summary는 문서의 정보를 합해서 문장을 좀 바꾸고 일관성 있는 요약을 생성할 수 있어요.
요약은 query-based와 non-query-based로 구분할 수 있는데 이 논문은 어차피 RAG를 다루니까 query-based 방식만 고려했다고 해요. (Query-based 방식은 쿼리와 관련성이 있는 정보를 요약하는거고, non-query-based 방식은 어떤 기준 없이 문서를 요약하는거라고 이해하면 될 것 같아요.) 2가지의 summarization 방식을 소개해요. Related works 섹션에도 포함되어 있던 부분이에요.
1. Recomp: Extractive compressor, Abstractive compressor을 사용해서 요약하는 방식이에요. Extractive compressor는 유용한 문장을 선택하는 역할을 하고, abstractive compressor는 여러 문서에서 정보를 합성해서 요약하는 방식이에요.
2. LongLLMLingua: 이 방법은 쿼리와 관련된 핵심 정보에 집중해서 LLMLingua를 개선한 방식이에요. (LLMLingua는 잘 훈련된 소형 언어 모델을 사용해 프롬프트를 압축하여 의미를 유지하면서도 길이를 줄이는 모델이에요. Perplexity 계산으로 중요한 정보를 파악하고, 예시에는 높은 압축률, 질문/설명에는 낮은 압축률을 적용해요. LongLLMLingua는 긴 문맥에서 중요한 정보 손실을 방지하고 질문 중심으로 문서를 재구성해요. Contrastive Perplexity를 사용해 질문과 관련된 정보를 더 효과적으로 압축하며, 압축 과정에서 손실된 내용을 복구해 정확도를 높이는 방식이에요. 각 논문 링크는 모델명 클릭해주세요!)
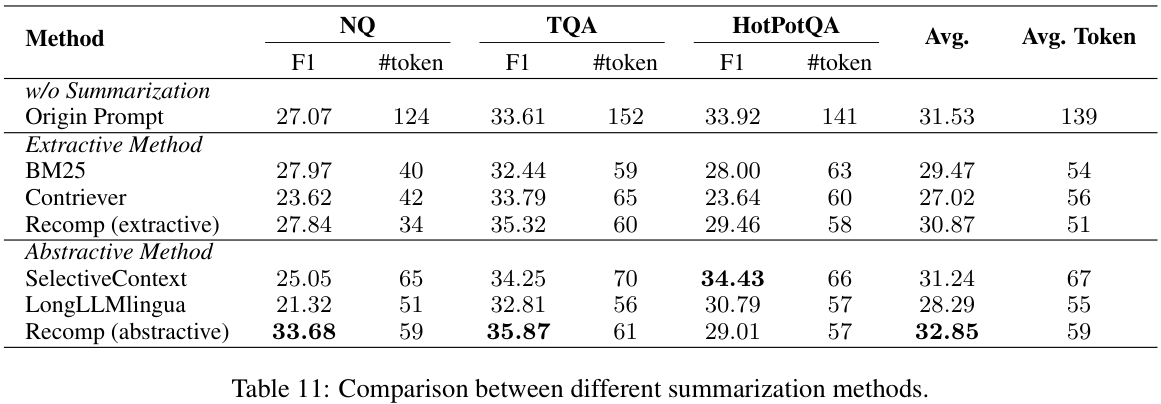
Evaluation은 NQ, TriviaQA, HotpotQA 3가지 벤치마크에서 평가했어요. 논문에서는 recomp 방식을 추천하네요. 하지만, Recompt는 학습해야하는 모델이라, LongLLMLingua는 학습 없이 좀 더 일반화가 좋은 모델이 될 수 있다고 합니다. 상황에 따라서 학습이 가능하면 recomp, 학습이 힘든 상황이라면 LongLLMLingua를 사용해보면 될 것 같네요!
GENERATOR FINE-TUNING
와! 드디어 workflow 마지막 파트!!! Generator의 미세조정이에요. 이 논문에서는 retriever의 미세조정은 future exploration으로 남겨놨다고 하네요. 논문에서는 관련성이 있거나 관련성이 없는 context가 generator의 성능에 미치는 영향을 확인하는 것으로 미세조정의 영향력을 조사한다고 했다고 해요.
미세조정하지 않은 기본 LM generator를
QA task 답변이 상대적으로 짧기 때문에 Ground-truth coverage가 평가지표로 사용되었다고 하네요. QA 평가지표 중에 주로 포함되는 Exact Match (EM) 보다 좀 더 관대한 접근 방식을 택했다고 합니다. (EM이 gold 정답 그대로를 출력해야 정답으로 인정하는 지표인데, 답이 만약에 '당근' 이라면, '당근입니다.' 라는 답변에 대해서도 정답처리하는 느낌인 것 같네요.)
기본 모델로는 Llama-2-7B을 선택했고, 훈련과 마찬가지로 validation set을
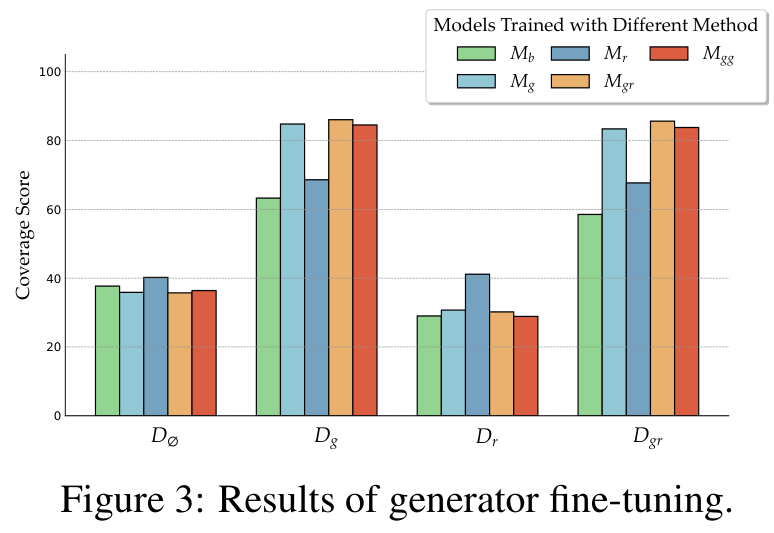
관련된 문서랑 문장위 문서를 혼합해서 학습한 모델(
SEARCHING FOR BEST RAG PRACTICES
열심히 모듈 별로 알아보고 평가도 했으니, 이제 전체 프레임워크 최적화에 대한 평가가 필요하겠죠? 논문에서는 Llama2-7B-Chat model을 Section 3.8에서 제시한 미세조정 방식을 통해 학습시킨 모델을 generator로 사용하고, Milvus를 이용해서 1천만개의 영어 Wikipedia 텍스트와 400만개의 의료 데이터 텍스트를 포함하는 VectorDB를 구축했어요.
그리고 query classification, reranking, summarization 모듈을 제거했을 때의 영향을 확인해서 각 모듈의 RAG system 내에서의 기여도를 평가했다고 합니다.
COMPREHENSIVE EVALUATION
RAG system 평가를 위해서 여러 NLP 작업과 데이터셋에 걸쳐서 광범위한 실험을 진행했는데요. (각 데이터셋의 paperswithcode 링크를 달아두었으니, 데이터셋이 궁금하신 분들은 클릭해주세요!)
1. Commonsense Reasoning: MMLU, ARC-Challenge, OpenbookQA datasets
2. Fact Checking: FEVER, PubHealth datasets
3. Open-Domain QA: NQ, TriviaQA, WebQuestions datasets
4. MultiHop QA: HotPotQA, 2WikiMultiHopQA, MuSiQue datasets
5. Medical QA: PubMedQA datasets
이렇게 5가지 task로 나누어 평가를 진행했네요. 평가는 RAGAS에서 제안하는 Faithfulness, Context Relevancy, Answer Relevancy, Answer Correctness를 사용해서 RAG 기능을 평가했다고 합니다. (아무래도 RAG system은 평가가 힘든 부분이 있었는데 이제 RAGAS가 대표적인 평가 metric으로 자리잡아 가는 것 같네요.)
그리고 retrieved documents와 gold documents 사이의 cosine 유사도 계산을 통해 Retrieval Similarity를 평가했다고 합니다. 평가지표는 task마다 다르게 가져갔는데 아래와 같아요.
1. Accuracy: Commonsense Reasoning, Fact Checking, Medical QA
2. Token-level F1 / Exact Match (EM) : Open-Domain QA, Multihop QA
5가지 RAG performance의 평균을 계산하여 최종 RAG 점수를 산출했다고 하고, Section 3에서 구축한 동일한 corpus를 모든 작업에 사용했다고 합니다. 그리고 각 데이터셋에서 최대 500개의 예시를 sub-sampling했다고 하네요.
RESULTS AND ANALYSIS
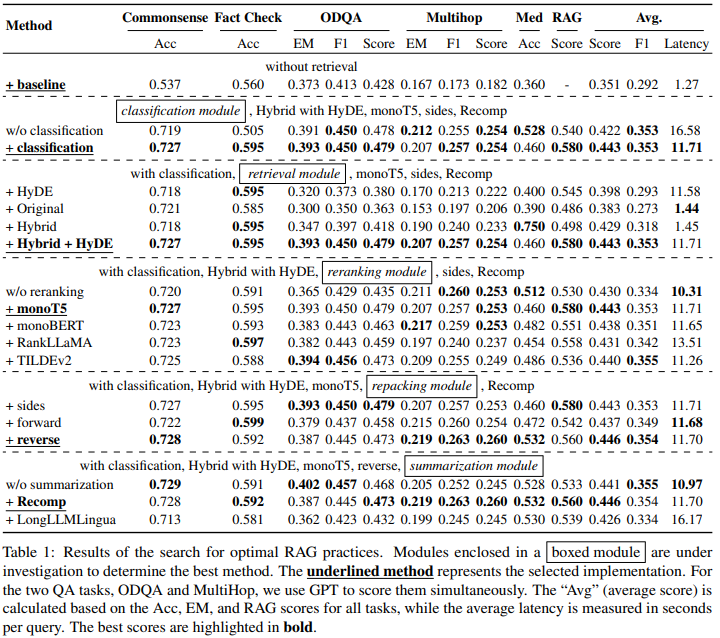
이제 위의 표와 함께 results와 해석을 확인해볼까요? Inference까지 걸리는 시간을 efficiency, 응답성능을 effectiveness라고 표현해서 저도 그렇게 써보도록 할게요.
1. Query Classification: Effectiveness ↑, Efficiency ↑
평균 overall score가 0.428 에서 0.443으로 증가하고, latency가 16.41에서 11.58로 감소했네요. Query classification이 선택적 retrieval을 통해 불필요한 작업을 방지해서 성능과 응답시간을 모두 향상시켰어요.
2. Retrieval Module: Dense Retrieval + BM25 (Hybrid) / Original - effectiveness ↑
Dense retrieval은 의미관계를 식별하는 데에는 탁월하지만, OOV나 희귀한 용어에 대해서는 어려움이 있어요. 하지만, BM25는 특정 단어 매칭에 능숙하기 때문에 이런 약점을 보완한다고 해요. (예시로, 비타민C에 대해서 검색하고 싶은데 의미관계에서는 비타민 A, B, C,.. 처럼 다양한 비타민들이 다 검색될 수 있지만, BM25는 비타민C를 매칭해서 검색하기 때문에 두 방식은 상호보완적으로 사용될 수 있어요.)
또 HyDE를 함께 사용하는 hybrid retrieval 방식이 0.58의 가장 높은 RAG 점수를 달성했지만 query 당 11.71초의 계산 시간이 들기 때문에 지연시간을 줄이면서 비슷한 성능을 유지할 수 있는 'hybrid' 또는 'original' 방식을 권장한다고 합니다. (Computaion의 증가로 HyDE를 사용하면 답변까지의 시간이 너무 오래걸려서, hybrid retrieval이나 일반 dense retrieval만 권장하는 것 같아요.)
3. Reranking Module: MonoT5 Reranker - effectiveness ↑
Reranking module을 사용하지 않을 때 성능저하가 크게 일어나기 때문에 고품질 답변 생성을 위해서 중요해요. DLM-based reranker 중에서 monoT5가 monoBERT와 RankLLaMA보다 뛰어난 성능을 보였어요. 이런 이유를 monoT5의 monoBERT 대비 더 큰 파라미터와 광범위한 학습 데이터, 그리고 decoder-only 구조 (RankLLaMA) 보다 encoder-decoder 구조를 가지고 있기 때문에 자연어 이해도가 더 높기 때문이라고 해석했네요. 따라서 monoT5를 사용한 Reranker가 응답 품질 개선에 높은 기여를 한다 라고 정리할 수 있겠습니다.
4. Repacking Module: Reverse - effectiveness ↑
Reverse 구성이 우수한 성능으로 0.560의 RAG 점수를 기록했네요. 관련성이 높은 context를 query에 더 가깝게 배치하는 것이 최적의 결과를 얻기에 중요하다는 것을 확인!
5. Summarization Module: Recomp - effectiveness ↑, efficiency ↓
Recomp extractive 요약 방식이 abstractive 요약 방식인 LongLLMLingua 보다 우수한 성능을 보였네요. LongLLMLingua는 rewrite 방식으로 인해서 종종 의미가 왜곡되거나, 일관성 없는 컨텐츠를 작성했다고 해요. 이에 반해 Recomp는 원본 컨텐츠의 무결성을 유지하기 때문에 RAG에는 더 적합하다고 합니다. 하지만, 요약에 사용되는 지연시간이 있기 때문에 요약모듈을 제거하면 시간을 줄이면서 비슷한 결과를 얻을 수는 있다고 합니다. 따라서, generator의 max length issue를 해결하는 것이 중요한 시나리오에서는 Recomp, 시간이 민감한 시나리오라면 summarization을 사용하지 않는 것을 제안합니다.
전체적인 실험 결과 각 모듈이 RAG system 전체 성능에 기여하고 있다는 것을 보였어요.
정리하자면, Query classification은 정확도를 높이고, 지연시간을 줄여주고, Retrieval, Reranking module은 다양한 query를 처리하는 system의 능력을 향상시켜요. Repacking과 Summarization은 RAG system의 출력을 세분화해서 다양한 작업에서 높은 품질의 응답을 생성할 수 있게 해준다고 할 수 있겠네요!
DISCUSSION
BEST PRACTICES FOR IMPLEMENTING RAG
실험 결과에 따라서, 성능 극대화에 초점을 맞추는 방식과 효율과 성능 사이의 균형을 맞추는 2가지 방법을 제안해요.
1. Best Performance Practice: Query Classification + HyDE + Hybrid Retrieval + monoT5 Reranker + Recomp Summerizer
이런 구성은 계산이 많아지지만 가장 높은 평균 점수인 0.483을 기록했어요.
2. Balanced Efficiency Practice: Query Classification + Hybride Retrieval + TILDE v2 Reranker + Recomp Summerizer
검색 모듈이 system 처리 시간의 대부분이라 다른 모듈은 그대로 유지하면서, Hybrid retrieval로 전환하는 구성을 통해 비슷한 성능을 유지하면서 지연시간을 크게 줄일 수 있어서 위의 구성을 추천했네요.
GENERALIZATION OF BEST PRACTICES
위에서 제시한 best practices가 높은 성능을 보이지만 모든 task와 context에서 보편적으로 최적이라고 할 수는 없죠. 그래서 general, domain-specific, task-specific한 측면으로 나눠서 system 성능을 평가하는 종합적인 평가 프레임워크와 가장 효과적인 조합을 파악하기 위한 3단계 전략을 제시했어요.
1. Empiricial Comparision of Candidate Implementations: 각 모듈에 대해 여러 후보 방법들을 비교해서 가장 성능이 좋은 옵션 선택.
2. Module Integration: 각 모듈에 대해 최적의 방법을 선택 후, 전체 workflow에 통합했을 때 상호작용하는 방식 평가.
3. Evaluation of Module Combinations: 다양한 모듈 조합의 성능을 평가하여 system 성능과 효율성을 개선할 수 있는 측면 파악.
MULTIMODAL EXTENSION
요즘 VLM을 포함해 다양한 RAG 어플리케이션이 등장해서 이 논문에서도 추가로 multimodal에 관한 실험을 간략하게 진행했나봐요. 검색 source로서 이미지와 텍스트가 pair로 구성된 Text2Image와 Image2Text 검색 기능을 통합했다고 합니다.
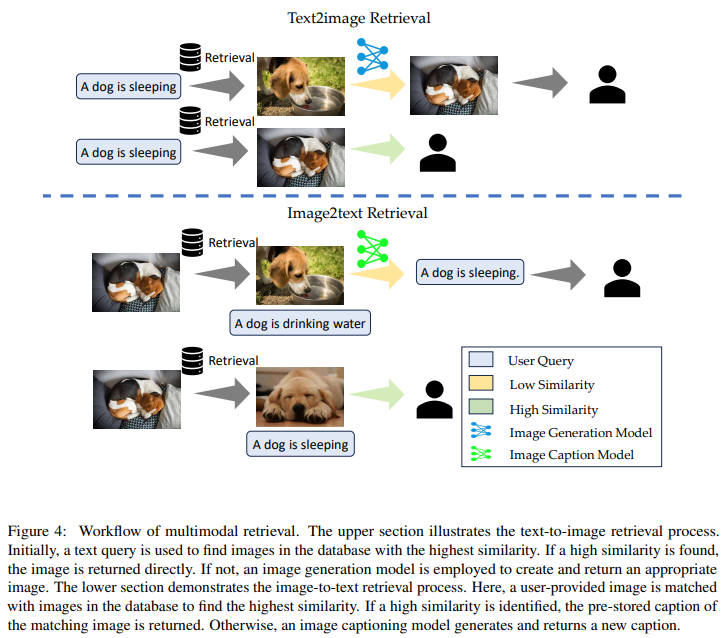
Text2Image 기능은 사용자 쿼리가 저장된 이미지의 텍스트 설명과 잘 일치할 때 이미지 생성 프로세스 ('retrieval as generation')의 속도를 높였고, Image2Text는 사용자가 image를 제공하고 입력 image에 대한 대화를 할 때 작동한다고 합니다. 즉, 'Retrieval as generation'은 쿼리와 가장 유사한 image를 먼저 검색하고 높은 유사도의 image가 있다면 해당 image를 반환하고, 없다면 쿼리에 맞는 이미지를 생성하는 프로세스였네요. 확실히 조건 없이 이미지를 생성하는 것보다는 시간적인 cost가 많이 적어질 것 같은데 역시 데이터셋이 중요하군요.
위의 방법을 통해 얻을 수 있는 이점은 다음과 같아요.
1. Groundedness: 검색을 통하기 때문에 검증된 multimodal 데이터에서 정보를 제공하기 때문에 신뢰성과 구체성을 보장할 수 있어요. 하지만, 생성만 사용하는 모델은 모델에 의존해서 새로운 컨텐츠를 생성하기 때문에 사실에 대한 오류나 부정확한 이미지를 반환할 수도 있죠.
2. Efficiency: 검색 방식은 저장된 자료에 이미 원하는 답변 (image or text) 가 있다면 효율적이에요. 하지만, 생성만 사용하면 image나 긴 텍스트의 경우 새로운 컨텐츠를 생성하는데 더 많은 컴퓨팅 resource가 필요하겠죠?
3. Maintainability: 생성 모델은 새로운 어플리케이션에 맞게 조정하려면 fine-tuning이 필요한 경우가 많죠. 하지만, 검색 기반 방식은 검색 source의 크기를 확장하고 품질을 향상해서 새로운 요구 사항을 개선할 수 있는 장점이 있네요.
논문에서는 CC3M 데이터셋에서 이미지 검색 프롬프트를 위해 PartiPrompts 데이터셋을 사용했어요. 그리고 openai/clip-vit-largepath142 를 사용해서 프롬프트와 2가지 유형의 이미지 (PRO2GEN, PRO2RET) 간의 CLIP 유사성을 계산하고 각 방식에서 소요시간을 계산해서 실험했어요.
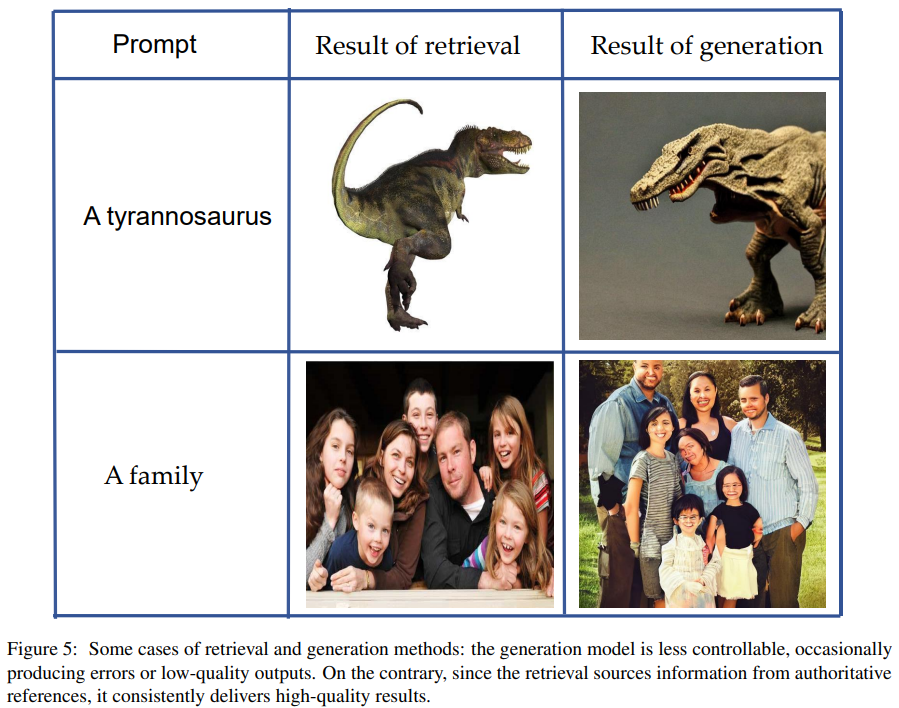
위 결과를 보니 생성 모델을 사용한 이미지는 좀 부자연스럽죠? 이래서 retrieval을 먼저 거치는 retrieval as generation 방식이 더 좋다고 이야기하고 있어요.

이 결과를 보면 'Retrieval as generation' 전략을 통해 이미지의 품질은 유지하면서도 latency를 크게 줄였네요.
저자들은 이 전략의 적용범위를 동영상, 음성 등 다른 모달리티로 확대하고, 효율적이고 효과적인 cross-modal 검색 기법을 연구할 계획이라고 하네요. 뭔가 훌륭한 연구가 나올 것 같은 느낌..!
CONCLUSION
이 부분은 생략하도록 할게요. 하하 지금까지 내용을 쭉 정리해 둔 내용이라서요.. 손가락 이슈로.. 양해해주시면 감사드리겠습니다..
LIMITATIONS
이 논문에서는 LLM generator의 fine-tune을 위한 다양한 방법을 평가했지만, retriever와 generator를 함께 훈련하는 것은 진행하지 않았어요. 그리고, VectorDB 구축 및 실험 수행에 cost가 너무 많이 들어서 chunking module 중에서는 대표적인 chunking 기법만 연구에 활용했어요. 그래서 더 다양한 chunking 기법에 대해 실험을 하지는 못했다고 해요. (이 정도면 충분하다고 생각이 들기는 합니다 하하...) 그리고 chunking 기법 자체가 RAG system 전체에 어떤 영향을 미치는지는 조사를 못했죠. 사실 이 정도 실험이랑 정리해 준 것만 해도 감사합니다 저자분들..!
자 오늘은 EMNLP 2024에 등재된 Searching for Best Practices in Retrieval-Augmented Generation 논문에 대해서 살펴봤어요. 제가 RAG에 워낙 관심이 많아서 열심히 리뷰해봤는데요.
여기부터는 제 의견이에요.
저는 RAG에서는 retrieval이 답변 퀄리티를 높이는데 있어서 가장 중요하다는 주의라 임베딩 모델이랑 다양한 retrieval 기법에 관심이 많거든요. 그래서 최신 임베딩 모델들을 계속 살펴보는 편이에요. 요즘 flash attention을 사용해서 임베딩 속도를 엄청 올려둔 모델들이 많이 나오고, BAAI의 bge-m3 모델이나 JINAAI에서 낸 jina-embeddings-v3 같은 모델을 보면 임베딩 성능이 진짜 많이 좋아진 게 느껴지거든요. 그래서 최신 임베딩 모델이랑 키워드 기반 검색 hybrid를 했을 때 성능 차이가 좀 미미해 지는 느낌이 들기는 해요. 오히려 안좋아지는 경우도 종종 있구요. 물론 키워드 매치가 중요한 분야에서는 성능 향상이 있긴 하겠지만요.
하지만 여기서 정리해 둔 모듈들이 RAG 전반에 대한 내용들을 쭉 정리해줘서 엄청 고맙네요.. 데이터셋들도 그렇구요. 감사합니다..! RAG가 익숙하신 분들은 어느정도 아는 내용이겠지만, 새롭게 접하는 분들에게는 이 정도로 친절한 논문이 없을 것 같아서 여기저기 추천해 줄 수 있을 것 같아요 ㅎㅎ
이렇게 저의 2025년 첫 포스트를 마무리 해 보도록 할게요. 사실 작년 해봤자 어제 부터 리뷰하고 있던 논문인데 정리해두고 싶어서 자세히 하다보니 기간이 많이 늘었네요.
올해는 더 똑똑해져야겠어요.
새해 복 많이 받으세요!
