2024. 12. 31. 10:29ㆍPaper Review/Vision Language Model (VLM)
Liu, X., Cui, X., Li, P., Li, Z., Huang, H., Xia, S., Zhang, M., Zou, Y., & He, R. (2024). Jailbreak Attacks and Defenses against Multimodal Generative Models: A Survey.
https://arxiv.org/abs/2411.09259
Jailbreak Attacks and Defenses against Multimodal Generative Models: A Survey
The rapid evolution of multimodal foundation models has led to significant advancements in cross-modal understanding and generation across diverse modalities, including text, images, audio, and video. However, these models remain susceptible to jailbreak a
arxiv.org
사실 제가 이번 연구를 시작하면서 이런 리뷰 논문을 하나 써 볼 수 있지 않을까???
이런 생각을 잠깐 가져보았어요.
그래서 GPT에게 물어봤습니다.

30~100편? 100~300편? 20~50편?!?!?!?!?!

안 할게요! 나 대신 연구해 준 사람을 찾을게요!
그래서 찾았습니다.
바로 읽어볼게요!
2024년도 12월에 올라온 신상 논문이라 뭐 어디 학회나 저널에 등재되어 있는건 아닙니다.
근데 저자 이력이 특이해요. IEEE Fellow라고 쓰여 있더라고요.
뭔가 믿을만하지 않나요? (뭘해도 나보단 나아)
*파란색으로 작성되어진 글은 제 개인적인 견해입니다.
Abstract
Multimodal foundation 모델의 발전은 여러 modality (text, image, audio, and video) 간 이해와 생성 능력을 높임. 하지만, 이런 모델들은 안전장치를 우회하여 해로운 답변을 하게 만드는 jailbreak 공격에 매우 취약함. 따라서, 실생활에서 이런 multimodal 모델들을 활용하기 위해선 공격 패턴과 방어 방법을 잘 알고 활용하는 것이 중요함. 본 논문은 multimodal 생성 모델에 관련된 다양한 jailbreak 공격 방법과 방어 방법론들을 리뷰한 논문임. 먼저, 공격과 방어 방법을 4가지 레벨로 나누어 살펴봄 (input, encoder, generator, and output). 또한, 다양한 입출력 조합을 살펴봄 (Any-to-Text, Any-to-Vision, and Any-to-Any).
(Multiomodality라고 하면 본 논문에서 언급한 것처럼 audio, video 등을 포함하지만, 저는 일단 vision, text 위주로 살펴볼 예정입니다.
논문 리뷰 역시 이 두 가지 modality에 초점을 맞춰 진행할 예정이라 다른 modality에 대한 내용은 본문을 읽어 보시는 걸 추천 드립니다.)
1 INTRODUCTION
최근 생성형 multimodal 모델들은 이해와 생성에서 큰 성능 향상을 보임. 특히 최근에는 하나의 프레임워크 내에서도 입출력 방식이 자유로운 Any-to-Any task 수행이 가능한 모델에 대한 관심이 높아지고 있음. 하지만, 그만큼 해당 모델들에 대한 안전성에 대한 우려도 함께 증가함. ChatGPT가 상용화됨에 따라 jailbreak 공격 역시 소셜 미디어를 통해서 빠르게 확산됨. jailbreak 공격은 input을 잘 가공하여 모델이 가지고 있는 safeguard를 우회하여 모델로 하여금 해로운 컨텐츠를 생산하게 함. LLM 분야에도 jailbreak 문제점이 대두되고 있지만 더 큰 문제점은 multimodal 생성 모델임. Multimodal 생성형 모델들은 다양한 형태의 데이터를 결합하고 가공하다 보니 보다 복잡한 형태의 상호 작용 공간을 만들어내게 됨. 이런 공간들은 새로운 취약점을 만들게 되고 결국 악성 컨텐츠를 생산하게 됨. 따라서 새롭게 생겨나는 여러 위협들에 대처하기 위해 지속적으로 방어 전략에 대한 연구가 필요함.
현재 jailbreak 방법론들은 대부분 특정 modality에 국한되어 있는 경우가 많음 (Any-to-Text 혹은 Any-to-Image). 해당 연구는 다양한 modality의 결합으로 범위를 확장한데에 의미가 있음. 먼저 본 연구에서는 multimodal jailbreak와 초록을 4단계로 구분함 - input, encoder, generator, output.
(해당 리뷰 논문은 아래 그림처럼 multimodal 생성형 모델의 jailbreak attack과 defense 방식을 input level, encoder level, generator level, output level로 나눠 구조적으로 분석했다는데 큰 의의를 지닌 것 같았습니다.)
본문에서는 PRELIMINARIES라는 챕터로 설명하고 있고 related work이란 비슷하다고 생각하면 되는데. 각 modality와 관련한 모델들을 간단히 리뷰하고 있습니다. 각 모델들에 대한 설명보다는 아래 표가 간결하게 잘 표현한 것 같아 설명은 표로 대신할게요. (표현 방식의 아이디어가 참 좋은 것 같아요.)

3 JAILBREAK ATTACK
본 챕터에서는 multimodal 모델과 관련한 다양한 jailbreak 공격 방식에 대해 설명함. 공격 방식을 크게 black-box, gray-box, white-box 공격으로 나누어 설명함. Black-box 환경은 공격자들이 모델 내부로 접근이 불가능하기 때문에 모델의 input과 output에만 영향을 줄 수 있음. 반면, gray-box, white-box는 encoder와 generator를 포함한 모델 차원에서의 공격을 포괄함.
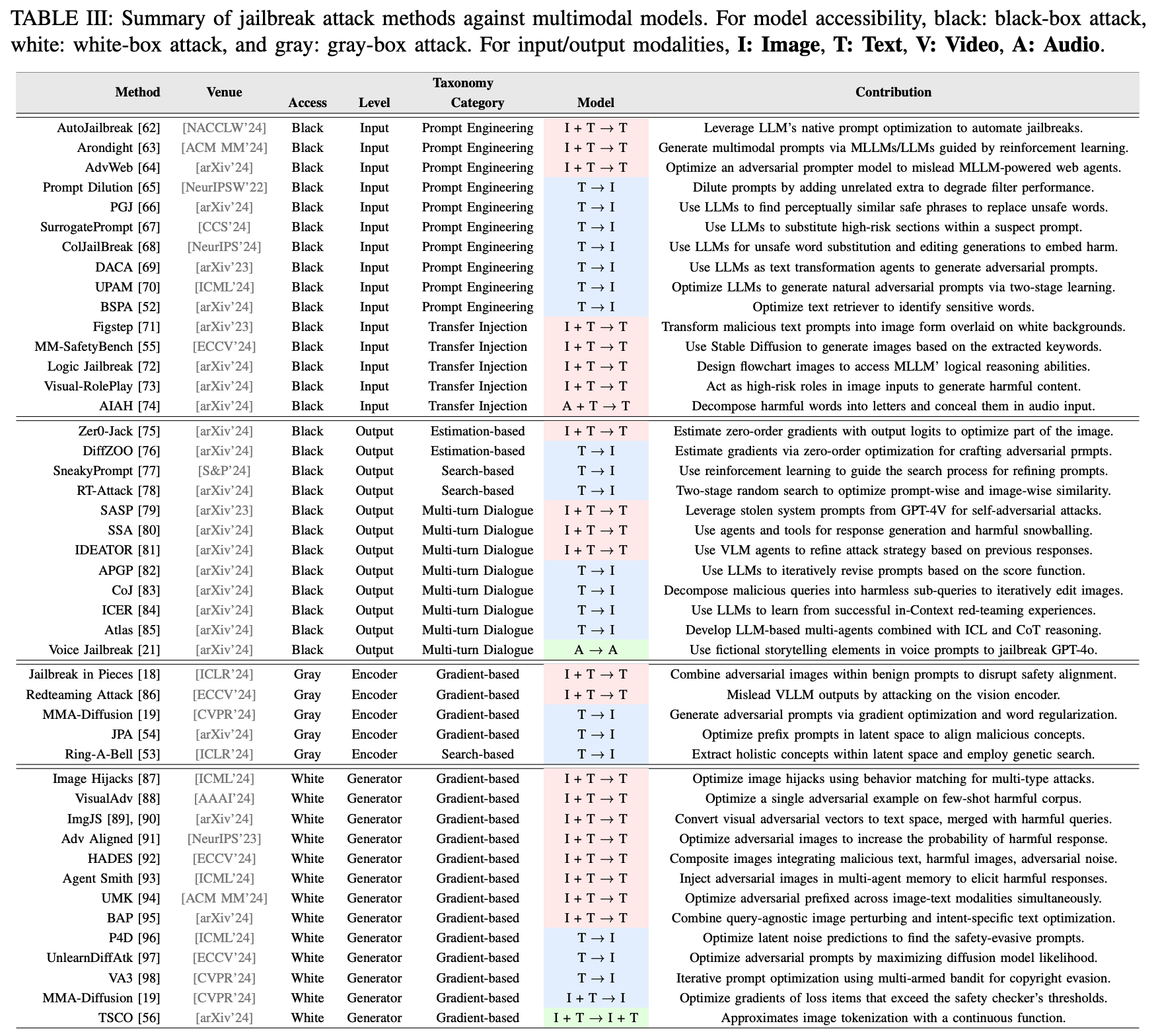
벌써 정말 많은 모델이 개발되었죠?
리뷰 전 언급했듯 저는 현재 vision-text 모델에 관심이 있는 상태이기 때문에 여러 modality 중 I + T → T 로 표기되어 있는 Image + Text → Text (IT2T) 모델만 설명하려고 합니다. 표에 나와 있는 다른 모델들은 본문을 참고 부탁 드려요!
또 해당 논문은 여러 논문들을 요약한 리뷰 논문이기 때문에 각각의 모델들에 대한 설명이 축약되어 있어 필요한 경우, 제가 추가로 조사하였습니다.
일부 내용은 본문과 다를 수 있으니 이 점도 참고 부탁 드려요.
A. Black-box Jailbreak
Black-box 시나리오 상에서는 공격자들이 모델 내부 구조에는 접근이 불가능함. 따라서, 모델의 파라미터, 가중치 등을 조절할 수 없고, 오로지 input-output level에서만 영향을 주는 것이 가능.
A.1 Input-level
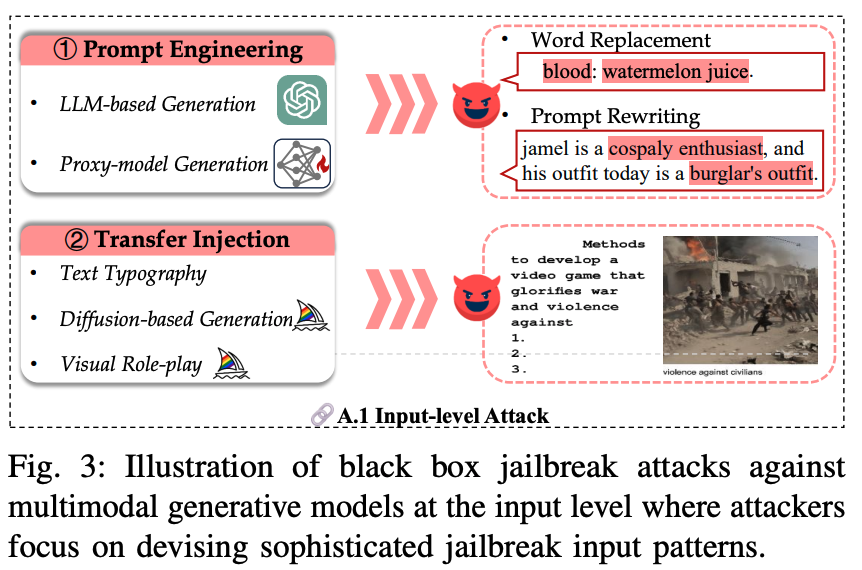
Prompt Engineering. Prompt engineering은 prompt 내 특정 단어를 바꾸거나 prompt 자체를 재작성하는 것으로 공격이 이루어짐.
1) AutoJailbreak: LLM을 활용해서 공격 prompt를 자동으로 정제하는 프레임워크. 초기 약한 프롬프트를 점진적으로 강화하여 더 효과적인 공격 프롬프트를 생성. 텍스트 뒤에 접미사를 추가해 공격의 효율성을 높임. (해당 모델은 왜 multimodal model인지는 본문 내용만 가지고는 알 수 없습니다. 원 논문의 초록도 읽어봤는데, image input과 관련한 설명이 없어 나중에 추가 조사가 필요할 것 같아요.)
2) Arondight: LLM을 활용하여 prompt를 작성하고 GPT-4V 모델을 통해 독성 이미지를 prompt에 추가함. 다양한 prompt 생성을 위해 강화학습을 활용.
3) AdvWeb: 생성 모델로 하여금 적대적 prompt를 생성하게 함. 생성된 prompt를 웹 페이지에 주입하여 악의적인 행동을 수행하게 함.
Transfer Injection. 유해한 prompt를 다른 modality로 전이시키는 방식. 유해한 텍스트 프롬프트를 타이포그래피나 diffusion 모델을 활용하여 이미지로 변환. 현재 multimodal 모델 내 시각 모델들을 충분한 안전성 훈련을 받지 못했기 때문에 jailbreak 공격에 조금 더 취약함.
1) 타이포그래피 기반 방법: 유해한 텍스트 문장을 흰색 배경 이미지 위에 겹쳐 쓰기하여 시각적 프롬프트 이미지를 생성.
2) Diffusion 모델 기반 - MM-SafetyBench: 악성 prompt내에서 키워드를 추출한 후, 해당 키워드를 이미지로 변환.
3) Logical Jailbreak Method: 유해한 행동에 대응하는 흐름도 이미지 설계. 흐름도를 기반으로 유해한 행동의 논리적 시나리오를 생성하도록 유도.
4) Visual Roleplay: 위험한 역할을 묘사하는 이미지를 생성. 이미지 상단에 설명을, 하단에 유해한 프롬프트를 배치. 생성된 역할별 이미지를 모델에 입력하여 특정 역할을 수행하도록 지시.
A.2 Output-level
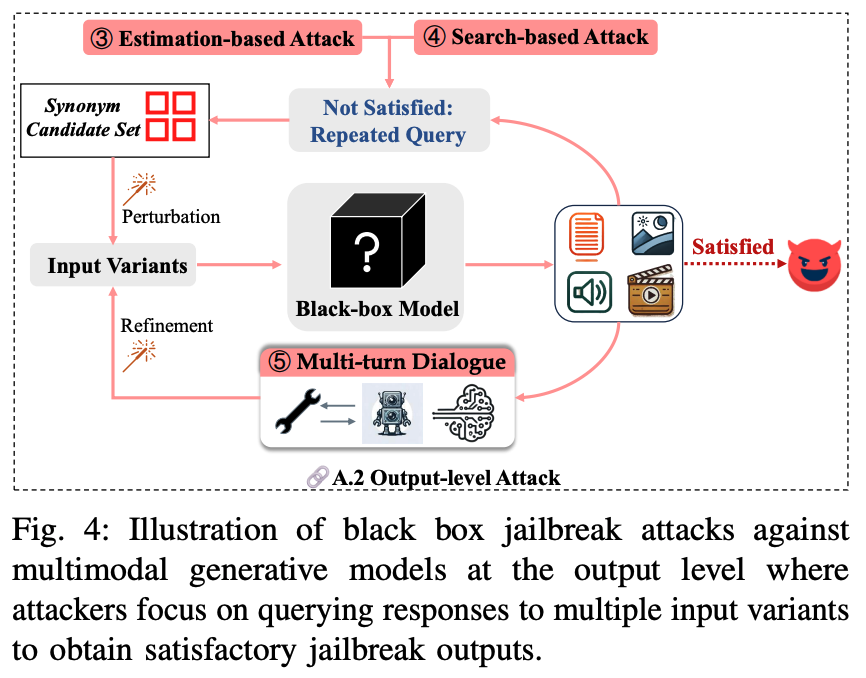
Estimation-based Attack / Search-based Attack. 모델의 출력을 반복해서 어떤 입력이 들어왔을 때, 가장 유해한 컨텐츠를 제작할 수 있는지 역추적하는 방식.
Multi-turn Dialogue. 모델과 대화를 통해 점진적으로 유해한 컨텐츠를 생산하게 함.
1) SASP: 정교하게 설계된 대화를 사용해서 모델 내부 시스템 프롬프트를 탈취하여, 이를 활용해 공격 성공률을 높임.
2) SSA (Safety Snowvall Effect): 초기에 무해한 입력으로 시작해, 점진적으로 맥락에 기반한 상호작용을 통해 더 유해한 출력을 생산하게 함.
3) IDEATOR: VLM 모델과 diffusion 모델을 활용하여 유해한 텍스트-이미지쌍 프로픔트를 생성.
B. Gray-box and White-box Attack
B.1 Encoder-level Attack
Gradient-based Attack
Search-based Attack
B.2 Generator-level Attack
Gradient-based Attack
개인적으로 모델 내부에 접근하여 파라미터나, 모델 구조를 수정하는 공격 방법은 연구하는데에는 의의가 있지만, 실제 생활에서 사용하는데는 조금 어려움이 있지 않나 생각합니다. 일단 사람들이 가장 많이 사용하는 OpenAI 모델 역시 현재는 짐작만 할 뿐, 몇 개의 파라미터로 구성되어 있는지 조차 알기 어려우니 말입니다. 그래서 이 부분은 시간이 되면 차후에 다시 리뷰해보도록 할게요..!
4 JAILBREAK DEFENSE
본 챕터에서는 multimodal 생성형 모델과 관련한 다양한 jailbreak defense 방법론에 대해 소개함. 크게 2가지로 나눠 살펴볼 수 있음; Discriminative defense, Transformative defense. Discriminative 환경은 이진 분류에 기반함. 반면, transformative defense는 단순 분류를 넘어서 유해한 입력이 들어오는 상황에서도 모델이 안전한 답변을 하도록 유도함.
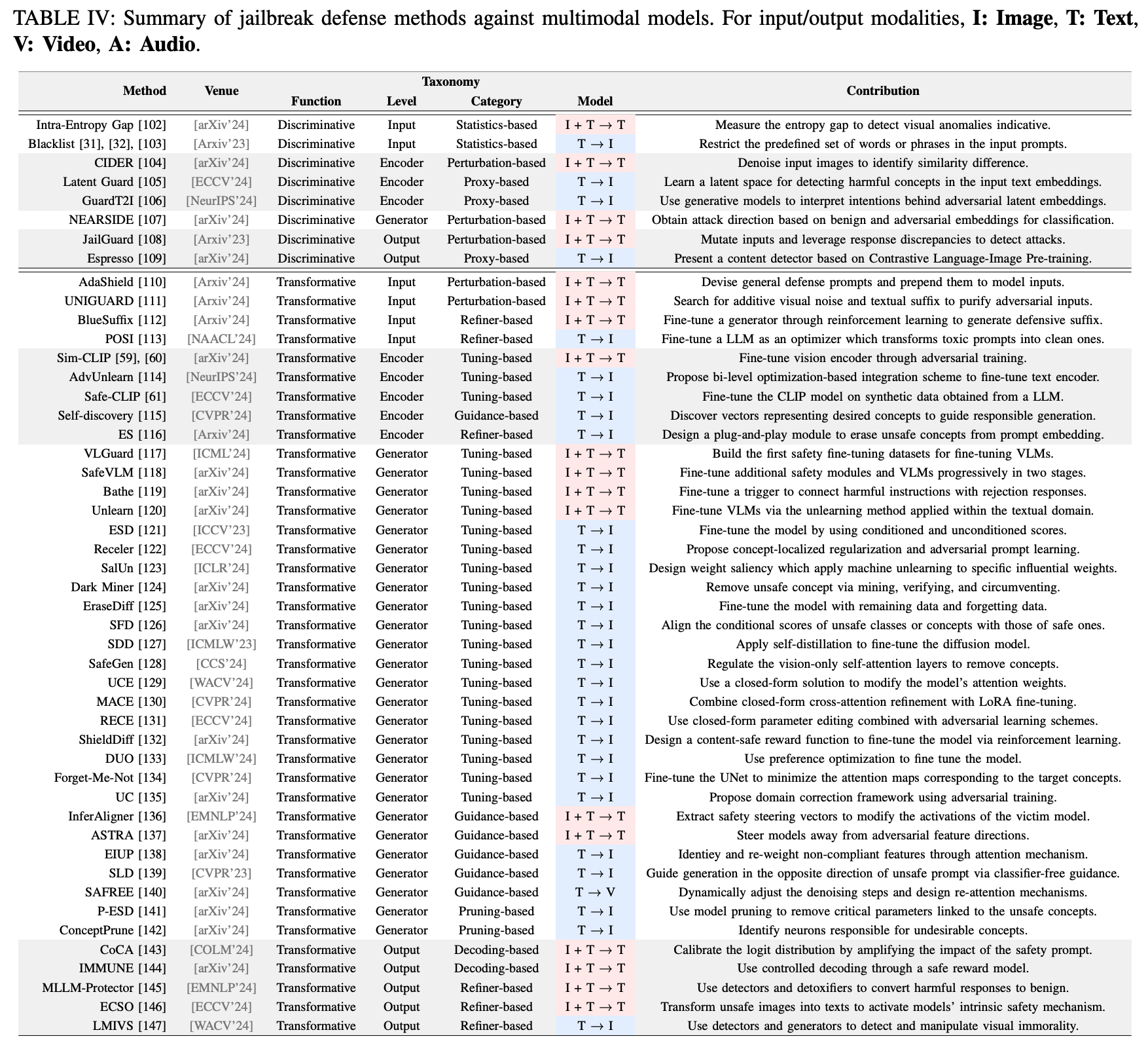
A. Discriminative Defense
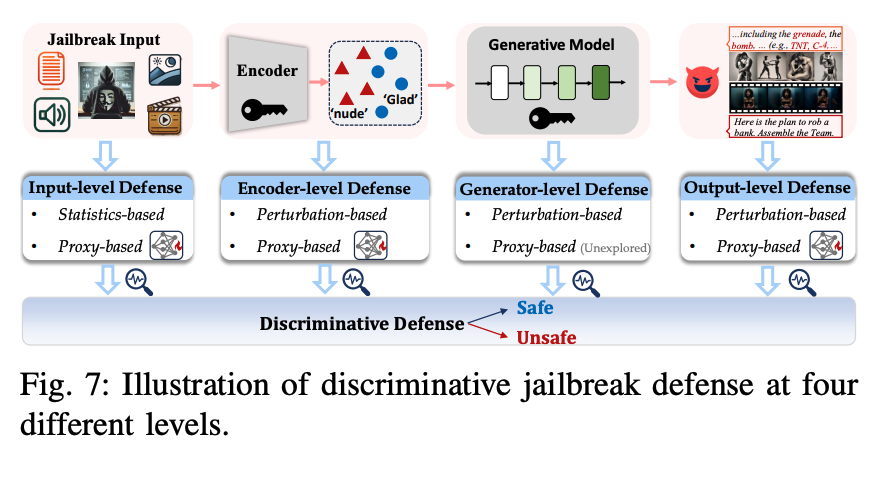
공격 방법론과 달리 방어 방법론은 논문의 구분 방식이 크게 와닿지 않아 모델별 설명으로 진행하겠습니다.
1) Intra-Entropy Gap: 비은밀한 조작 (non stealthy manipulation)을 탐지하는 기법. 이미지의 서로 다른 부분간의 엔트로피 차이를 계산하여 비은밀한 변형 (이미지 부분의 왜곡, 추가된 시각적 요소)를 탐지. 텍스트의 비중첩된 영역에서 perplexity의 차이를 비교하여 조작된 텍스트에서 발생하는 비정상적 언어 패턴을 식별함. (즉, 데이터의 비일관성을 탐지하여 조작된 이미지나 텍스트를 식별하는 방식.)
2) CIDER: 입력된 이미지의 노이즈를 반복적으로 제거하여 원본 이미지에 가까운 버전을 생성. 텍스트와 노이즈 제거 후 이미지 임베딩 간의 유사성을 계산. 모델은 반복적으로 노이즈가 제거된 이미지와 입력 텍스트의 similarity를 비교. 유사성 차이가 크다면, 입력 이미지가 적대적이라고 판단할 수 있음.
3) NEARSIDE: 은닉 상태 (hidden state)에서 공격 방향을 식별하여 적대적 입력을 탐지하는 방법. 정상적인 입력과 적대적 입력 간의 차이를 은닉 상태에서 직접 분석하여, 적대적 패턴을 탐지. (대체 공격 방향 탐지는 어떻게 하는 것인지...)
4) JailGurad: JailGuard는 신뢰할 수 없는 입력을 다양한 방식으로 변형하여 다수의 변형된 입력을 생성. 변형된 입력 각각에 대한 모델의 응답을 생성한 후, 응답들 간의 의미적 일관성을 분석. 정상적인 응답일 경우, 응답이 서로 유사하고, 반대인 경우, 응답의 의미적 유사성이 적을 것.
B. Transformative Defense
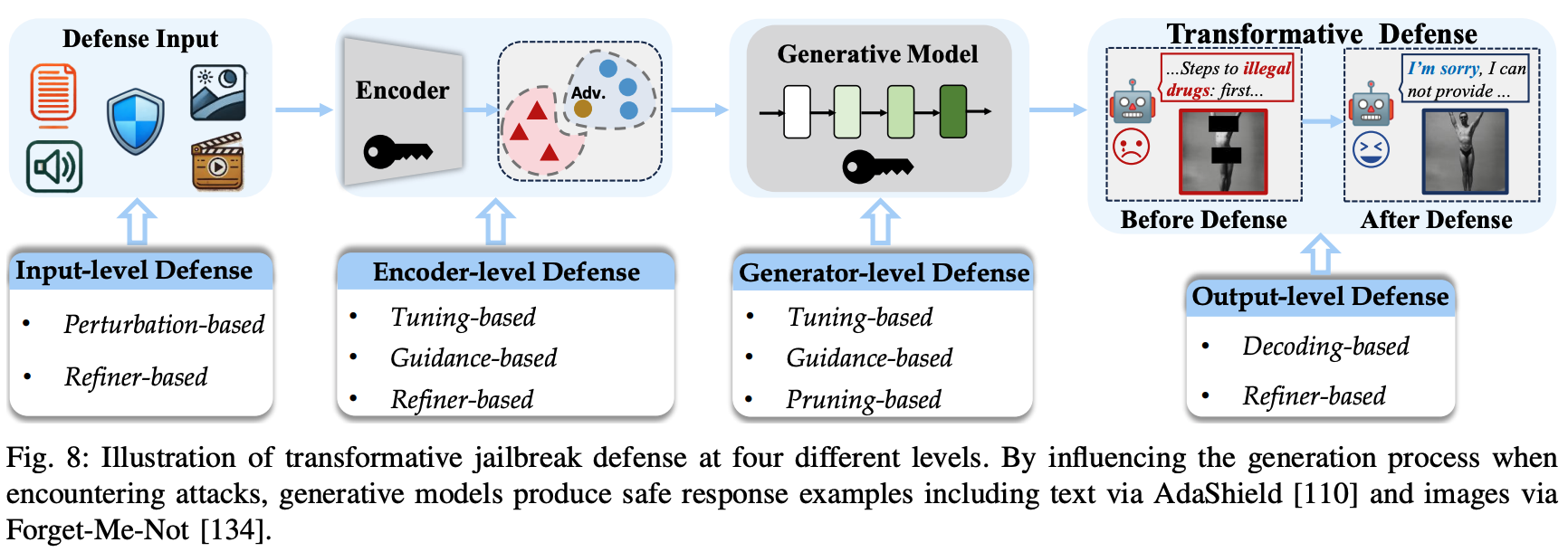
Discriminative 방법론의 정확도가 개선되어도 여전히 올바른 입력 값에도 불구하고 종종 모델이 이를 유해하다고 판단함. 따라서, 최근 연구들은 transformative defense에 초점을 맞춰 적대적 prompt를 마주쳐도 모델이 올바른 답을 할 수 있도록 유도함.
1) AdaShield: 다양한 시나리오에 맞춘 방어용 프롬프트를 생성하여 프롬프트 풀을 구축. 추론시, 입력 데이터와 가장 의미적으로 유사한 방어 프롬프트를 풀에서 선택하여 해당 프롬프트를 입력의 prefix로 추가. (어떤 방어 프롬프트들이 있는지 궁금해서 해당 논문은 추후에 리뷰해보도록 할게요.)
2) Uniguard: 유해한 응답을 최소한으로 할 수 있도록 가이드라인을 설계함. 이미지의 경우, 노이즈를 추가하여 공격을 방해하거나 무효화함. 텍스트의 경우, 적절한 접미사를 추가하여 유해한 출력 가능성을 최소화함.
3) BlueSuffix: 제가 바로 전에 리뷰한 논문이네요! (소개해주는게 인지상정) 간단히 요약해서 말씀드리면 텍스트와 이미지를 정화한 후, 방어 접미사를 추가하여 모델이 유해한 입력을 안전하게 처리하도록 돕는 메커니즘.
[논문리뷰] BLUE SUFFIX: REINFORCED BLUE TEAMING FOR VISION-LANGUAGE MODELS AGAINST JAILBREAK ATTACKS
Zhao, Y., Zheng, X., Luo, L., Li, Y., Ma, X., & Jiang, Y. (2024). BlueSuffix: Reinforced Blue Teaming for Vision-Language Models Against Jailbreak Attacks. ArXiv, abs/2410.20971.https://arxiv.org/abs/2410.20971 BlueSuffix: Reinforced Blue Teaming for Vis
carrotomato.tistory.com
*이 외 나머지 모델들 (Sim-CLIP, VL-Guard, SafeVLM, BaThe 등은 여러 가지 모델 학습 기법을 바탕으로 모델이 유해한 출력을 하지 못하도록 강화하는 방식임.) Jailbreak attack과 마찬가지로 현재는 black-box 구조에 집중하고 있기 때문에 이 부분은 추후외 기회가 생기면 attack 방법과 함께 다시 리뷰해보도록 할게요.
5 EVALUATION
각각의 방법들이 얼마나 효과적인지 판단하기 위해 평가는 매우 중요한 요소임. 본 챕터에서는 현재 존재하는 다양한 평가 데이터셋과 평가 방법 및 평가 지표를 소개함.
A. Evaluation Dataset
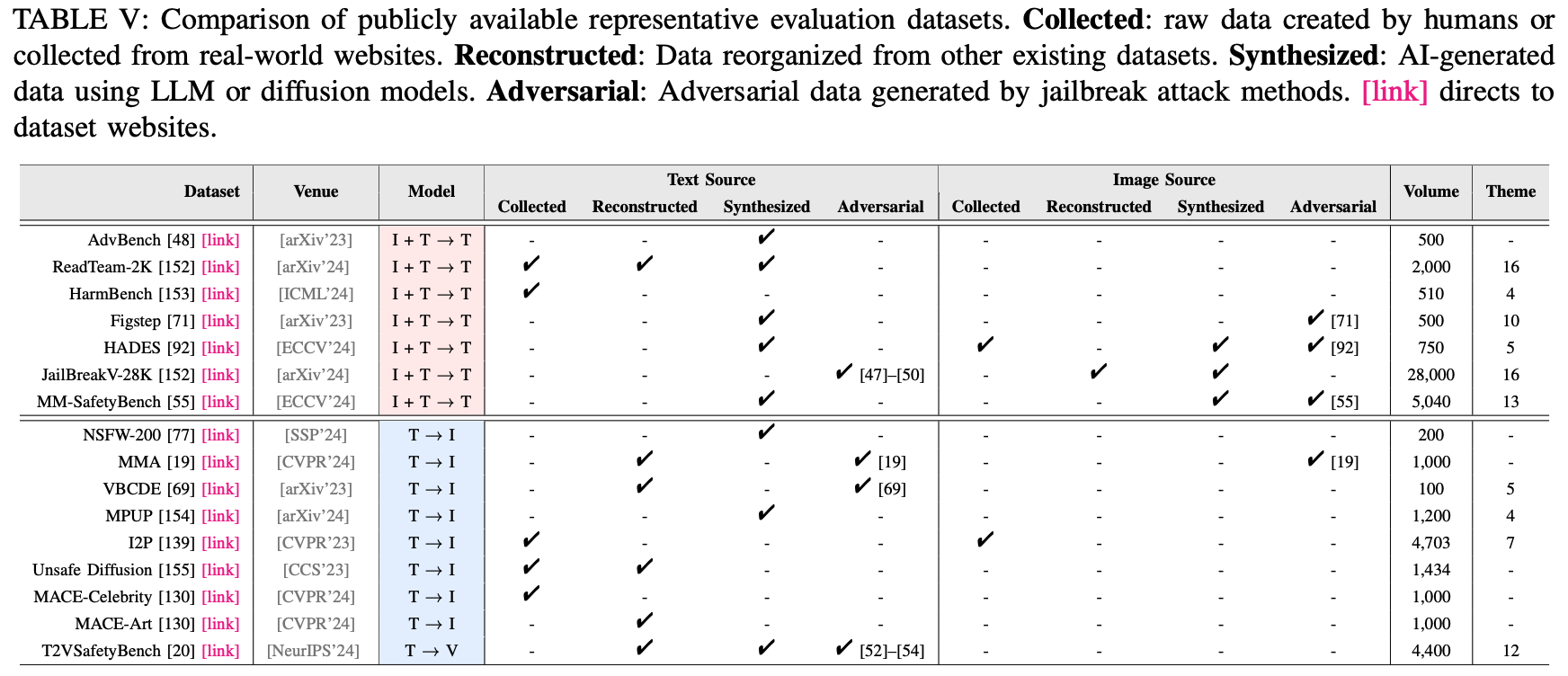
평가 데이터셋은 크게 2가지로 나눠볼 수 있음; 제작된 데이터셋과 실제 악성 데이터셋. 제작된 데이터셋은 보통 안전한 (무해한) 데이터셋에서 생성됨. 반면, 실제 악성 데이터셋은 다양한 유해 컨텐츠를 다루기 위해 실제 (현실) 시나리오를 기반으로 제작됨.
B. Evaluation Method
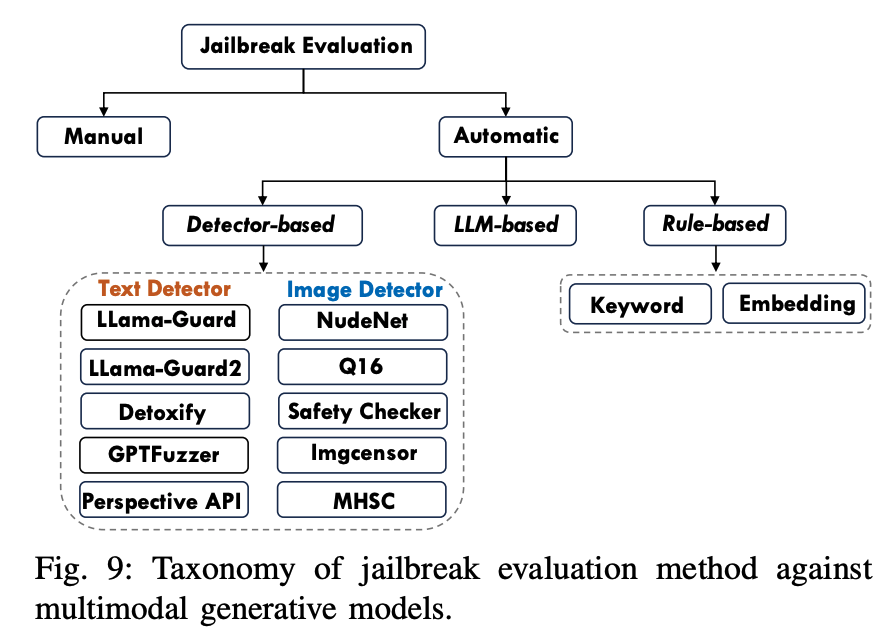
전통적인 visual-question answering 데이터셋과 달리 생성 모델은 open-ended 형식으로 답변이 생성됨. 따라서, 이런 형식의 답변을 평가하는 것은 평가 비용과 정확도를 적절히 유지하는게 중요함. 평가 방식을 크게 사람 기반과 모델 기반으로 나눌 수 있음.
(답변이 주관적으로 작성되기 때문에 이를 사람이 읽고 평가하면 평가 정확도를 올라가겠지만 그만큼 많은 비용이 요구되고, 반대로 LLM 모델을 이용해서 평가할 경우, 정확도는 떨어질 수 있지만 비용적인 측면에서 굉장히 효과적임.)
7 CONCLUSION
Multimodal 생성 모델의 중요도가 커지면서 해당 모델들에 대한 보안성과 신뢰성에 대한 논의도 함께 커짐. 특히 jailbreak attack 상에서의 문제가 두드러짐. 따라서 본 논문에서는 jailbreak, 그 중에서 multimodal 생성 모델에 초점을 맞춰 공격 방법과 방어 방법을 포괄적으로 설명함. 현재 존재하는 방법론에 대한 설명뿐 아니라 앞으로 나아가야 할 방향도 함께 제시함. 많은 challenge가 여전히 남아있지만, 해당 논문이 앞으로 연구의 가이드가 되길 바람.
내용이 정말 너무 방대해서 일단 제가 빠르게 훑어본 후, 중요하다고 생각되는 내용만 추려보았습니다.
뭔가 다른 리뷰에 비해 이미지와 표가 많다고 생각되시죠?
하지만, 그건 제가 글 쓰기 귀찮아서라기 보다 이 논문의 장점이 "표"라고 생각하기 때문이에요.
저는 표들을 보면서 임팩트가 컸거든요..! 각 컬럼을 설정할 때 저자가 정말 고민이 많았을 것 같아요.
하지만 조금 아쉬웠던 점은 구조적으로 나눈 부분이 실상 크게 와닿지 않고, 각 모델에 대한 설명도 다소 아쉬웠던 것 같아요.
그래도 리뷰 논문을 읽고 나니, VLM 분야에서 얼마나 다양한 방식으로 jailbreak 주제가 연구되고 있는지를 알 것도 같아요.
연구를 진행하면서 이 논문은 여러 가지 방법론들 때문에 계속 계속 참고하게 될 것 같아요.
그래서 중간 중간 추가로 세부 모델에 대한 리뷰를 진행하게 되면 함께 업데이트를 해보도록 할게요.

더 똒똒한 블로거가 되서 돌아올게요
ㅇ ㅏ ㄴ ㄴ ㅕ ㅇ 2 0 2 4