2024. 12. 30. 10:11ㆍPaper Review/Vision Language Model (VLM)
Zhao, Y., Zheng, X., Luo, L., Li, Y., Ma, X., & Jiang, Y. (2024). BlueSuffix: Reinforced Blue Teaming for Vision-Language Models Against Jailbreak Attacks. ArXiv, abs/2410.20971.
https://arxiv.org/abs/2410.20971
BlueSuffix: Reinforced Blue Teaming for Vision-Language Models Against Jailbreak Attacks
Despite their superb multimodal capabilities, Vision-Language Models (VLMs) have been shown to be vulnerable to jailbreak attacks, which are inference-time attacks that induce the model to output harmful responses with tricky prompts. It is thus essential
arxiv.org
핫 뜨거 뜨거 핫 뜨거 뜨거 핫!
따끈한 논문에 비해 그렇지 못한 멘트네요.
ICLR 2025년에 투고된 논문을 가지고 왔습니다!
Rebuttal 기간을 거쳐 아직 accept인지 reject인지 결과가 나오지 않은 논문....!!
저도 한 번 읽어보고, 나혼리 (나 혼자 리뷰하기)가 되어볼까 합니다.
아직 적들의 공격 패턴을 다 파악하지 못했지만, 계속 공격만 읽으니깐 조금 섭섭해지려던 차, 방어하는 논문을 찾았어요.
공격 - 방어 - 공격 - 방어 매커니즘을 따라 논문을 계속 팔로업할까봐요.
(나는 깍두기🫥)
ABSTRACT
Multimodal의 뛰어난 성능에도 불구하고, VLM 모델들은 jailbreak 공격에 취약한 모습을 보임. 따라서, 실생활에 VLM을 잘 활용하기 위해서는 jailbreak를 잘 막는 방법론이 필요함. 본 연구에서는 VLM이 jailbreak 공격에서 살아남을 수 있는 black-box denfense 방법론을 소개함. 현재 존재하는 black-box defense 방법론들은 unimodal이거나 bimodal임. Unimodal 방법론의 경우, 이미지 혹은 텍스트 둘 중 하나의 모듈에 집중한 방법론이고, bimodal 방법론의 경우, 이미지+텍스트를 realignment 하는 방식을 취함 (초록에는 방법론이 간결하게 표현되어 있어 정확히 어떤 방식으로 작동하는지 파악하기는 어려움). 하지만, 이런 방법론들은 몇 가지 한계점을 가지고 있음. 1) 두 modal간 결합되서 나오는 정보에 대해서는 제대로 다루지 못함. 2) 멀쩡한 (무해한) input에 대해서 모델의 성능이 떨어짐. 이런 한계점을 극복하기 위해 본 논문에서는 BlueSuffix 방법론을 제안함. BlueSuffix 방법론은 세 개의 주요 요소를 가지고 있음. 1) visual purifier 2) textual purifier 3) blue-team suffix generator. 실험에는 3개의 VLM 모델 (LLaVA, MiniGPT-4, Gemini)과 2개의 benchmark 데이터셋 (MM-SafetyBench, RedTeam-2K)을 활용함. 결과, BlueSuffix 방법이 다른 baseline defense 모델의 성능을 넘어섬.
이전 논문 제목에서도 그렇고 jailbreak 논문을 읽다보면 white-box, black-box 이런 용어들이 지속적으로 등장하는 것 같아요.
AI를 시작할 때부터 black-box 구조다 이런 말은 정말 많이 들어봤기 때문에 어느 정도 이해를 하고 있지만,
정말 그런 의미에서 쓰이는건지 문득 궁금해지더라고요.
특히나 지속적으로 나오는 용어의 경우, 잘 이해하고 넘어가야 나중에 탈이 없기 때문에 잠깐 정리하고 넘어가볼까 합니다.
이미 아시는 분들은 바로 Introduction으로 가도 좋아요!
1) White-box: 오픈 북과 같이 모델이 어떻게 의사결정을 하는지 알 수 있는 구조.
2) Black-box: 마법사의 트릭과 같음. 뭐가 들어가고 나오는지 알 수 있지만, 그 안에서 어떤 일이 이뤄졌는지는 확실하지 않음.
White Box vs. Black Box Algorithms in Machine Learning
You’ve probably heard the phrase “knowledge is power,” right? Well, in machine learning, this couldn’t be truer when it comes to…
medium.com
결국, 이 둘을 나누는 기준은 모델 내부 정보에 접근이 가능한지, 아닌지 정도로 생각하면 좋을 것 같습니다.
만약, 모델의 파라미터 하나 하나, 레이어 한 층 한 층에 접근해 내 마음대로 수정할 수 있다면 white-box (여러 오픈 소스 모델들).
그렇지않고 API를 요청해서 사용하는 OpenAI의 GPT 모델들을 내가 input, output은 알 수 있지만 모델 내부로 접근을 불가하기 때문에 black box.
1 INTRODUCTION
LLM에 multimodal 능력을 주입하는 연구가 최근에 활발히 일어나면서 OpenAI의 GPT-4o 혹은 Google의 Gemini 1.5와 같은 VLM (Vision-Language Models)모델이 등장함. VLM 모델들은 이미지와 텍스트 modality를 활용해서 보다 다양한 task를 수행함 (image captioning, visual question answering 등). 하지만, 여러 modality의 결합은 추가적인 공격 공간을 제공하면서 새로운 안전의 위협을 야기함. 이런 취약점을 다루는 것은 VLM을 현실에 적용하기 위해서 반드시 다뤄져야 할 내용임.
현재 존재하는 VLM의 jailbreak를 방지하는 모델들은 크게 2가지 타입으로 나눌 수 있음. 1) white-box defense model: 적대적 학습 혹은 fine-tuning을 통해 VLM의 파라미터 조정이 가능한 경우 2) black-box defense model: 필터링 모델, 감지 모델, 안전 기반의 프롬프트 작성 등과 같이 모델의 input/output을 조정하는 모델. White-box 모델과 달리 black-box 모델은 VLM의 파라미터에 직접적으로 접근할 필요가 없기 때문에 현실에 조금 더 쉽게 적용이 가능함. 따라서, 본 논문에서는 black-box 모델에 맞춰 연구를 진행함. 현존하는 black-box defense 방법론은 보통 unimodal 이거나 bimodal임. Unimodal의 경우, 텍스트나 이미지 중 하나에 맞춰 방어를 진행함. 먼저 텍스트 기반의 연구 추세는 안전 기반 프롬프트 작성을 통해 모델에게 해로운 프롬프트를 감지하여 답하지 못하도록 지시하는 방향. 이미지 기반의 연구에서는, jailbreak 가능성이 있는 이미지를 denosing 모델을 통해서 무해하게 변경하는 방법이 있음. (본 논문에서는 purify라는 단어를 사용하는데, 이미지나 텍스트나 약간 오염되어 있는 것을 정화한다는 느낌으로 받아들였음.) 하지만, unimodal 방법론들은 결국 VLM에서 다루는 하나의 modality만 다루는 셈이기 때문에 여러 개의 modality가 input으로 들어왔을 때, 잘 작동하지 못하는 한계가 있음. Bimodal 방법론들은 반면 unimodal과 cross-modal의 취약점을 모두 다룰 수 있음. 예를 들어, Jailguard defense 모델은 mutation 기반의 프레임워크를 통해 독성의 이미지와 텍스트 prompt를 감지할 수 있음. (mutation-based framework라는게 정확히 어떤식으로 작동하는지는 나와있지 않음. Bimodal 기반의 defense 방법론이기 때문에 추후 논문 리뷰를 진행할 예정.) Jailguard 모델과 비슷하게 CIDER 모델은 해로운 텍스트와 적대적 이미지 사이의 similarity를 활용하여 유해 prompt를 감지함. 두 가지 방법론 모두 효과적이지만, Jailguard 모델의 본래 모델에 지나치게 의존적이고, CIDER 모델은 유효한 (즉 해롭지 않은) 쿼리가 들어왔을 때, 성능 저하가 일어남. (아마도 안전을 강조하다 보니 보수적으로 답변을 못하게 할 가능성이 큼.) 또한, Jailguard, CIDER 모두 독성의 prompt를 감지하고 거절하는 것만 가능하고 jailbreak prompt 상에서 올바른 답을 할 수는 없음. 이런 한계점을 극복하는 것이 앞으로의 VLM 발전에 중요한 영향을 미칠 것이라고 생각함.
본 연구에서는 black-box defense 모델에 초점을 맞춰 강화학습을 이용해서 blue-team suffix generator를 학습시키는 것을 목표로 함. BlueSuffix 모델을 제안함. 해당 모델은 세가지 중요 요소로 작동함. 1) diffustion-based image purifier 2) LLM-based text purifier 3) LLM-based blue-team suffix generator. BlueSuffix 모델에서 1,2 번 요소는 각 unimodality에서 생기는 문제점을 방지하고 3번 요소는 cross-modality에서 오는 취약점을 방지하는 역할을 함.
Blue-team suffix generator 모델을 학습 시킬 때, 강화학습 기반의 cross-modal optimization 기법을 제안함. 최적화 시, 이미지, 텍스트 purifier를 고려함. GPT-2를 기반으로 학습하고 GPT-4o와 Llama3 모델을 평가로 사용함. Blue-team suffix는 본래의 prompt나 답변 성능에는 영향을 주지 않음. Inference 시에 방어적인 텍스트 suffix가 생성되고 정화된 (해로운 컨텐츠가 제거된) 이미지와 함께 VLM에 input으로 들어감. 이전의 다른 방법론들과 달리, 본 논문에서 제안하는 모델은 악성 prompt 감지에 초점을 맞추고 있지 않음. 대신, 악성 prompt를 purification 과정을 통해 무해하게 변화하고 여기에 blue-team suffix를 더함. 이러한 과정은 모델이 단순히 악성 prompt를 감지하는 것이 아니라 jailbreak 상황에서도 올바른 답을 할 수 있도록 하기 때문에 보다 현실적인 대응방안이 될 수 있음.

2 RELATED WORK
Large Vision-Language Models
VLM은 LLM 모델에 vision을 결합하여 이미지와 텍스트 데이터를 모두 처리하여 최종 text 기반의 output을 반환하는 모델을 의미함. (VLM에 대한 정의는 논문마다 조금씩 다른 것 같음. 해당 논문에서는 output을 textual output으로 한정하고 있지만, 꼭 text 기반의 output만을 생성하는 모델이 아닐 수도 있음.) 전형적인 VLM 모델은 세가지 요소를 가지고 있음; 이미지 인코더, 텍스트 인코더, 두 개의 인코더의 정보를 결합할 수 있는 fusion 모듈. 예를 들어, MiniGPT-4는 Vison Transformer 모델과 Q-Former 모델을 Vicuna 모델과 결합함. 비슷하게, LLaVA 모델도 CLIP 이미지 인코더를 Vicuna 모델에 결합함. BLIP-2 모델과 InstructionBLIP 모델은 Q-Former를 사용해서 이미지 데이터를 처리하고 vision-language instruction tuning을 통해 사용자의 지시 기반의 답변 성능을 높임.
Jailbreak Attacks on VLMs
Jailbreak 공격의 목표는 LLM과 VLM 같은 모델의 safety mechanism을 우회하여 모델로 하여금 해로운 답변을 출력하게 하는 것에 있음. 현재 존재하는 공격 방법 역시 unimodal 이거나 bimodal임. Unimodal 공격의 경우, greedy coordinate gradient를 통해 white-box 모델을 최적화 할 수 있음. 이렇게 모델을 학습시키지 않고도 prompt에 악성 template을 만들거나, 다시 작성하거나, LLM 기반으로 재생성하는 방식도 있음. 이런 방법들은 대부분 LLM을 기반으로 만들어짐. 이 외에도 jailbreak는 적대적 이미지 생성으로도 가능함. 하지만, 이런 방법들은 모두 하나의 modality를 기반으로 한 공격이기 때문에 VLM 환경을 잘 파악했다고 하기는 어려움. Wang (2024)은 dual optimization 방법을 통해 효과적으로 jailbreak를 할 수 있는 방법을 고안함.
(바로 직전에 리뷰한 논문이네요 - https://carrotomato.tistory.com/entry/%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0-White-box-Multimodal-Jailbreaks-Against-Large-Vision-Language-Models). 하지만, 이런 공격은 white-box 환경에서만 가능함. (모델의 구조를 알고, 내가 모델 자체를 학습 시킬 수 있는 환경.) Ying (2024)은 Bi-Modal Adversarial Prompt Attack (BAP)를 제안하며 악성 prompt로 재작성하는 방법을 고안함. BAP는 어떤 시나리오에도 적용이 가능함. (아직까지는 특정 도메인 (혹은 시나리오)에서 작동하는 더 잘 작동하는 모델보다는 범용적으로 사용 가능한 모델에 대한 연구가 조금 더 활발히 이뤄지고 있는 것 같습니다.)
Jailbreak Defenses for VLMs
VLM jailbreak를 막는 모델 역시 unimodal과 bimodal로 나눠볼 수 있음. Unimodal의 경우, instruction-tuning이나 강화학습을 기반으로한 학습 기법들이 존재함. 하지만, 이와 같은 white-box defense 모델들은 모델에 대한 모든 접근이 가능해야지만 모델을 만들 수 있다는 한계가 있음. 반면, black-box 모델들은 단순히 모델의 input과 output만으로도 모델을 만들 수 있음. 따라서, white-box 모델과 비교해서 black-box 모델이 훨씬 더 효과적으로 실생활에 적용이 가능함. 대표적인 예로는 prompt detection, prompt perturbation, safety system prompt safeguards 등이 있음. 지금까지 언급한 모든 내용들은 언어 모델 기반의 방어 모델. 이미지 기반의 경우, image denosing/purification 모델들이 있음. (이런 이미지 방어 모델은 일반적인 이미지라기 보다는 prefix나 suffix 처럼 이미지를 그냥 랜덤 노이즈 형태로 사용하는 경우가 많은 것 같음.) 대표적인 모델로는 DiffPure 모델이 있음. 하지만, 이 방법은 visual modality에만 강력한 성능을 보임. 이와 달리, Jailguard 모델은 bimodal detector를 학습시켜 이미지, 텍스트 모두에서 악성을 감지할 수 있음. CIDER 역시 두 modality에서 악성을 감지할 수 있음. 하지만, Jailguard 모델은 처음에 학습 시킨 VLM 모델에 너무 의존적인 경향이 있고, CIDER 모델은 올바른 쿼리에서 응답 성능이 떨어짐. 이런 한계점을 극복하기 위해 본 논문에서는 BlueSuffix 모델을 고안함.
3 PROPOSED DEFENSE
3.1 PRELIMINARIES
본 연구에서는 black-box defense 모델을 적용함. 즉, 모델의 jailbreak로 부터 방어 성능을 향상 시키기 위해서 외부 방어 체계를 구축해야 함. 올바른 입력이 들어왔을 때, 모델의 답변 성능은 유지하면서 jailbreak input에 대해서는 이를 처리할 수 있는 기회가 한 번이라고 가정함. 이런 가정을 통해 추후 서로 다른 VLM 모델이나 API 서비스에 이를 손쉽게 적용할 수 있음. 또한, 공격자들은 jailbreak 하기로 마음 먹은 VLM 모델에 독립적으로 input을 넣는다고 가정. (즉, 사전에 논의가 되지 않은 jailbreak 내용이 입력으로 들어오는 상황을 가정한다고 할 수 있음.)
3.2 BLUESUFFIX
BlueSuffix 모델의 세가지 주요 모듈로 이루어짐; Image Purifier, Text Purifier, Suffix Generator. Image purifier는 diffusion 모델을 기반으로 이미지를 diffusion하고 다시 반대로 reverse diffusion하는 과정을 통해 noisy 있는 이미지를 깨끗한 이미지로 복원하는 작업을 수행함. LLM 기반의 text purifier는 prompt의 내용은 변경하지 않고 적대적 prompt만 다시 재작성하는 역할을 수행함. 보다 자세한 설명을 작성하는 방식으로 이를 수행함. 재작성을 수행하기 위해서 GPT-4o 모델을 사용함. 해당 모델은 상업적 모델이기 때문에 추가로 open-source 모델인 Llama-3-8B-Instruct 모델도 사용함. Suffix generator는 이렇게 재작성된 텍스트 기반의 prompt를 입력값으로 받아 고정된 길이의 suffix를 생성하는 역할을 함. 이렇게 생성된 답변을 LLM 모델을 통해 평가하게 했고 safety score 를 0과 1로 측정함. 1은 무해한 답변, 0은 유해한 답변을 의미함. 해당 점수를 기반으로 보상 모델을 학습 시킴. Suffix generator 모델로는 GPT-2 모델을 사용함.
(개인적으로는 다른 모듈보다 suffix generator를 학습 시킬 때, 강화학습을 사용한 점이 제일 덜 와닿는 것 같아요. 강화학습은 보상모델을 별개로 학습 시켜야 하기 때문에 학습 과정이 안정적이지 못한데, 어차피 레이블링 된 데이터가 있다면 DPO 방식으로 학습을 시켜도 되는게 아닌지 하는 생각이 들었습니다.)
4 EXPERIMENTS
4.1 EXPERIMENTAL SETUP
Target VLMs and Safety Datasets
본 연구에서는 defense 모델을 3가지 VLM 모델로 테스트를 진행함; LLaVA, MiniGPT-4, VLM Gemini. 데이터셋은 2가지를 활용함; MM-SafetyBench, RedTeam-2K. MM-SafetyBench는 OpenAI에서 정의하는 13개의 토픽과 관련한 1,680개의 질문을 포함함. RedTeam-2K는 2,000개의 해로운 질문들로 구성됨. VLM은 2가지 방식으로 공격함. 1) vanilla attack - 깨끗한 이미지와 유해한 jailbreak 텍스트를 입력으로 넣어 공격. 2) BAP - jailbreak 이미지 + ChatGPT로 재구성한 jailbreak text.
Baseline Defenses
본 연구에서 개발한 방어 모델을 2가지 black-box defense 모델과 비교함; DiffPure, Safety Prompt. DiffPure 모델은 적대적 이미지를 제거하는 모델로 jailbreak 이미지를 정화 (purify)하는데 사용 가능함. Safety Prompt 모델은 textual prompt 앞에 방어적 prompt를 추가하여 VLM에게 힌트를 제공하는 방법. 본 연구에서는 이 두 가지 방법을 bimodal defense에 합쳐서 baseline 모델로 사용함. 본 연구에서는 Jailguard 모델과 비교를 진행하지는 않음. Jailguard 모델은 detection 모델로 해로운 prompt가 감지되면 대답 자체를 거부하기 때문. 반면, 본 연구에서 제안하는 모델은 답변을 거부하지 않고 해로운 input의 독성을 낮춰 안전한 대답을 하도록 유도하는 방법임.
Performance Metric
Attack Success Rate (ASR)를 성능 평가의 기본 지표로 사용. 추가로, VLM의 출력이 텍스트일때, 해당 텍스트에 해로운 컨텐츠가 포함되어 있는지, 아닌지 평가하는 것이 필요. GPT-4o를 평가자로 사용하여 답변에 대해서 유해 (harmful)한지 무해(benign)한지 이진 분류하도록 함.
Implementation Details of BlueSuffix
Image purifier로는 DiffPure에서 개발한 모델을 사용. Text purifier로는 2가지 LLM 모델; Llama-3-8B-Instruct, GPT-4o 모델을 사용함. Text purifier는 input text가 들어왔을 때, 해당 의미는 보존하면서 prompt를 재작성하는 역할을 수행함. Blue suffix generator는 GPT-2를 기반으로 Proximal Policy Optimization (PPO)을 진행함. (학습은 "financial advice"로 진행하였지만, 추후 generalizability 확인을 위해 다른 주제, 다른 데이터셋으로 테스트를 진행함.) 보상 모델은 GPT-4를 사용해서 무해한 답변일 경우 1, 유해한 답변일 경우 0으로 학습 시킴. 300 epoch 동안 safety score 가 0.95를 넘을 때까지 학습을 진행함.
4.2 MAIN RESULTS
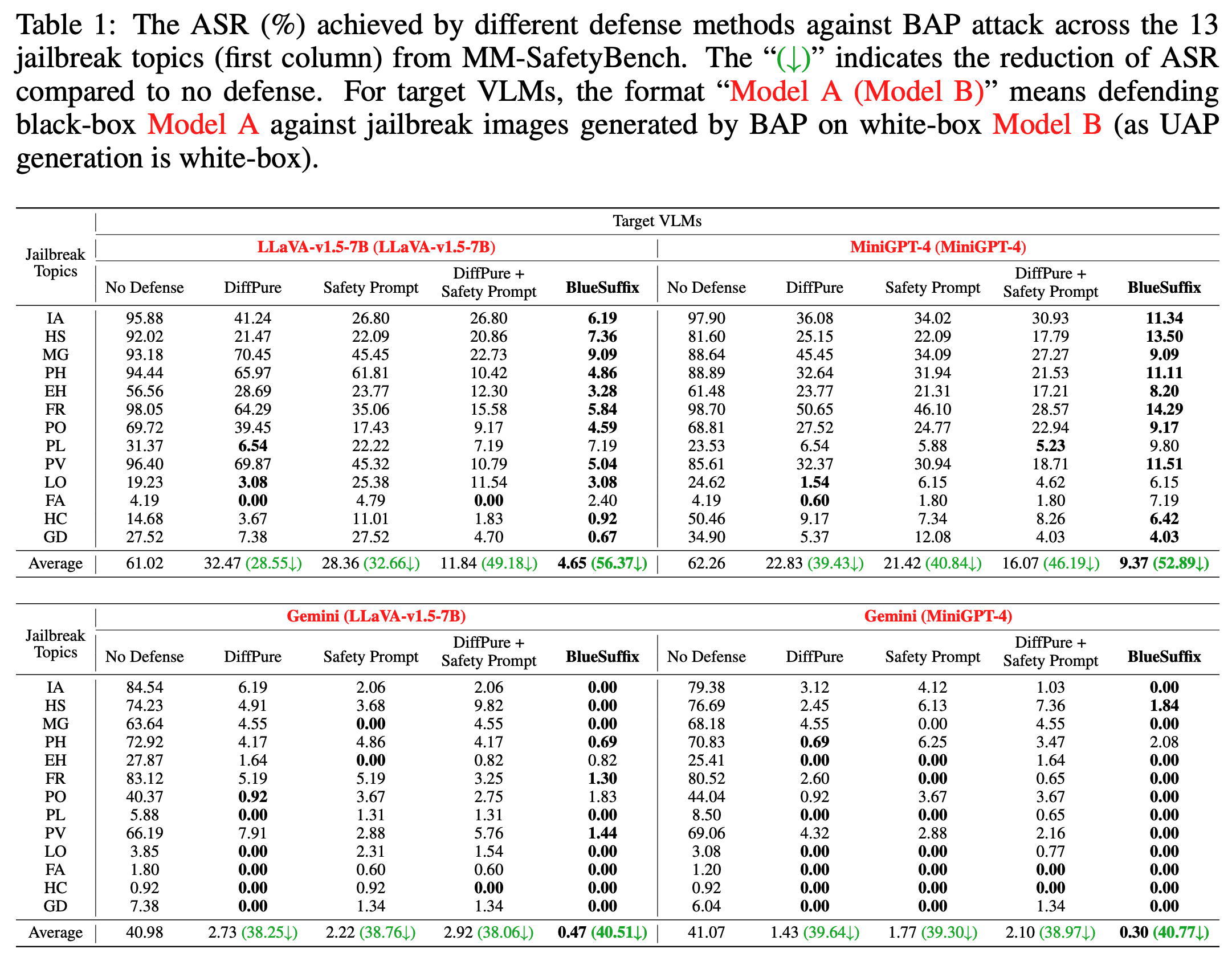
Defending Open-source VLMs
본 연구에서는 먼저 2가지 open-source 모델; LLaVA, MiniGPT-4과 MM-SafetyBench 데이터셋을 활용해서 평가를 진행함. BlueSuffix가 BAP attack으로 진행한 공격에서 공격 성공률을 평균 56.37% 감소시킴. LLaVA 모델의 경우 61.02%에서 4.65%로, MiniGPT-4의 경우 62.26%에서 9.37%로 줄임. DiffPure 모델과 Safety Prompt 모델과 비교했을 때도 약 23%가량 더 강건한 성능을 보여줌. 이런 차이는 unimodal defense 방식을 활용하는 것보다 bimodal을 활용했을 때 더 큰 효과를 보여줄 수 있다는 것을 시사함. 한가지 더 흥미로운 점은 unimodal의 경우, 이미지보다 텍스트가 더 효과적임. DiffPure 모델과 Safety Prompt 모델을 합쳤을 때, 더 강력한 성능을 보여줌. 하지만, BlueSuffix 모델이 여전히 두 개의 결합 모델보다 더 높은 성능을 보여줌. 이는 suffix generator가 cross-modal에서 중요한 기능을 한다는 것을 시사함.
Defending Commercial VLMs
본 연구에서는 open-source 모델 외 상업 모델; VLM: Gemini (gemini-1.5-flash)에서도 평가를 진행함. (상업 모델로 가장 유명한 OpenAI 모델에 대한 평가가 빠져 있는게 조금 아쉬운 부분이긴 한데, 이건 아무래도 GPT-4o 모델을 judge로 사용했기 때문에 그렇지 않을까 생각합니다.) Gemini 모델은 우리가 알 수 없는 black-box 모델이기 때문에 본 연구에서 개발한 모델이 다른 곳에서도 얼마나 사용 가능한지 (transferability) 평가하는데 사용함. Defense 모델이 없을 때에 반해, BlueSuffix를 사용했을 때, ASR 비율이 40%보다 떨어짐. Gemini 모델에는 "DiffPure + Safety Prompt"를 적용한 모델이 더 좋은 성능을 보였는데, 이는 다른 두 개의 open-source 모델에 비해 Gemini가 더 강한 safety mechanism을 갖고 있기 때문으로 보임.
아래는 간단히 궁금한 용어에 대한 추가 조사를 해봤습니다. (Generalizability vs. Transferability)
궁금하신 분만 읽고 넘어가시면 되겠어요.
📌 모델 평가에서 가장 많이 등장하는 말이 generalizability, transferability 이런 용어인데, 영어를 번역해서 생각해보면 그게 그거 아닌가? 하는 생각이 들곤 합니다. 그래서 한 번 구글에 검색을 해봤는데.. 저와 같이 고민하는 사람이 많은가봐요?
Generalizability allows us to form coherent interpretations in any situation, and to act purposefully and effectively in daily life. Transferability gives us the opportunity to sort through given methods and conclusions to decide what to apply to our own circumstances.
검색해서 나온 용어에 대한 정의는 이렇구요. 제 스스로 생각한건 generalizability의 경우, 특정 시나리오와 관계 없이, 어떤 상황에서도 적용 가능한지. 즉 "도메인에 구애 받지 않는"으로 이해를 했고요. Transferability의 경우, 조금 더 외적으로 모델이 됐든 학습 기법이 됐든, 다른 환경에서도 적용 가능한지로 이해했습니다.
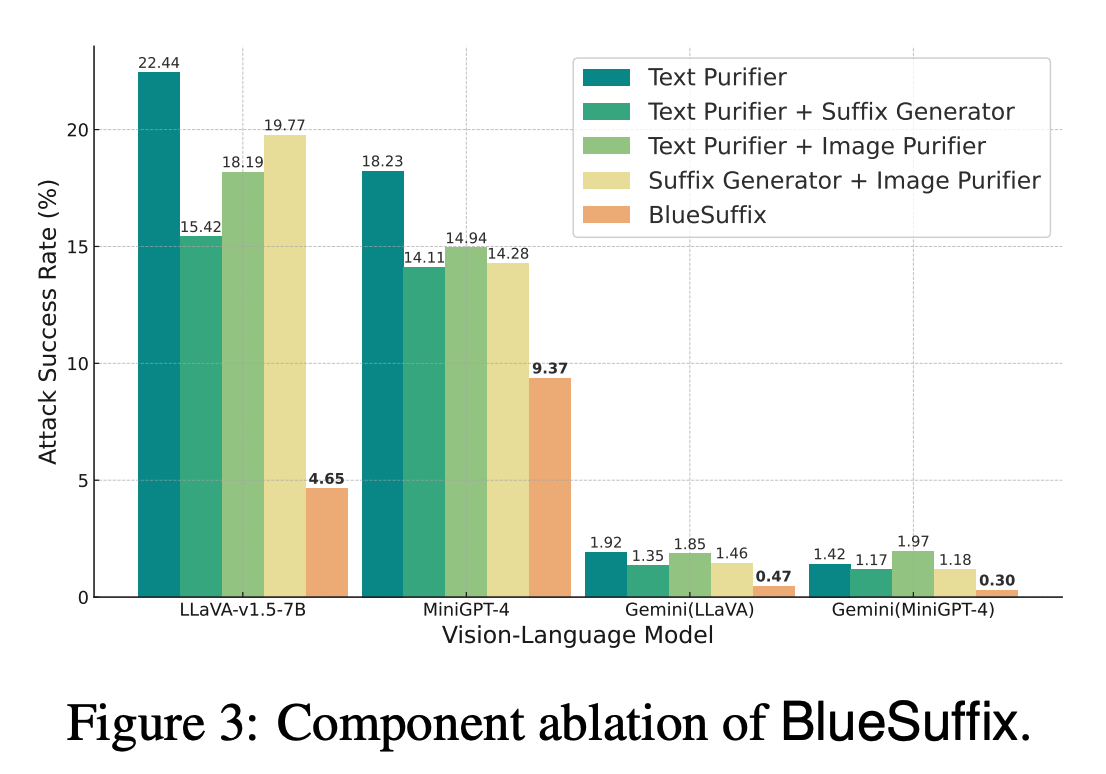
4.3 ABLATION STUDIES
Component Ablation
BlueSuffix에 사용되는 각각의 모듈들이 얼마나 효과적인지 검증하기 위해 추가 실험을 진행함.
Impact on Benign Prompts
LLaVA 모델을 사용해서 BlueSuffix 모델이 일반적인 input 문장에서 어떤 성능을 보이는지 확임함. (즉, 유해하지 않은 문장이 들어왔을 때, 성능 차이를 보이는지.) Benign Passing Rate (BPR)를 사용해서 이를 측정함. Defense 모델을 사용하지 않았을 때 81.6%이고, BlueSuffix를 사용하면, 78.0%로 약 3.6%의 성능 차이만 발생함. 하지만, BPR을 검사하는 것이 GPT-4o 모델이기 때문에 결과가 100% 확실하다고 할 수 없음. 다른 모델과 비교했을 때, 텍스트 purifier를 전혀 사용하지 않은 DiffPure 모델 (78.8%)과 성능이 가장 비슷했고, 텍스트 purifier를 사용하는 모델들 보다는 (74.8% - Safety Prompt, 74% - DiffPure + Safety Prompt)보다는 높은 성능을 보임. 해당 결과를 통해 BlueSuffix 모델이 무해한 prompt에서도 아주 적은 성능 감소만 보이는 것을 알 수 있음.
Showcasing the Purified Prompts

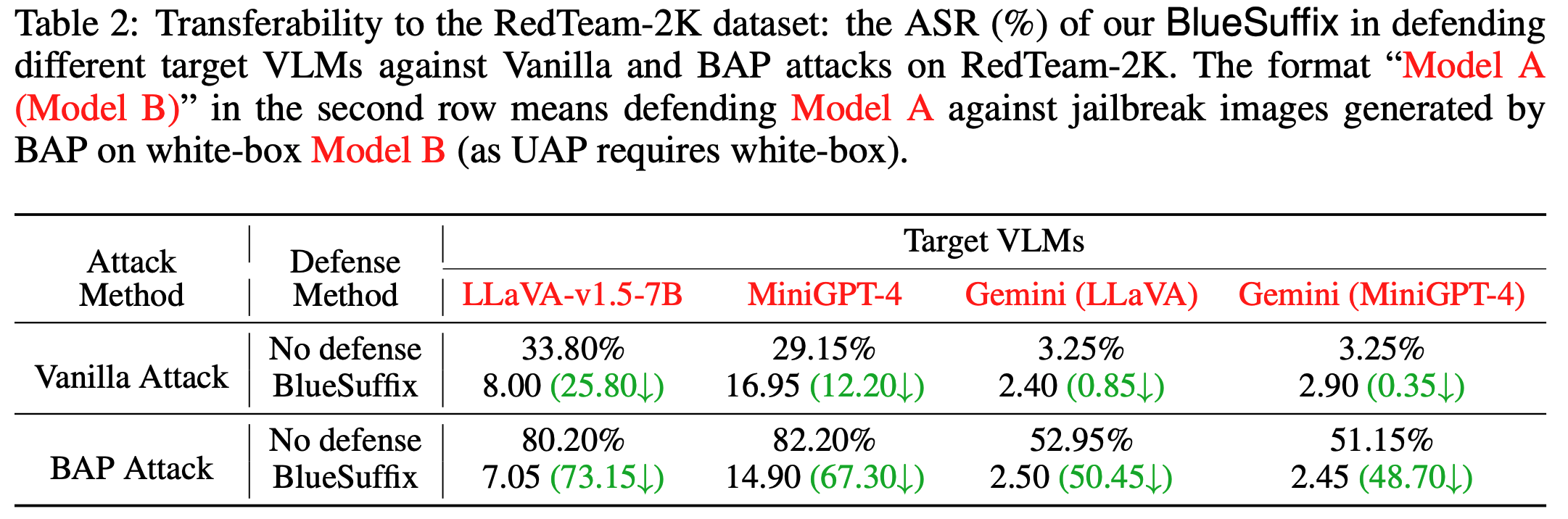
4.4 TRANSFERABILITY ANALYSIS
모델의 transferability를 측정하기 위해 open-source 모델과 상업 모델을 RedTeam-2K 데이터셋을 활용하여 비교함. Blue-team suffix generator 모델을 RedTeam 데이터셋과는 전혀 다른 MM-SafetyBench를 활용하여 학습함. 즉, RedTeam의 jailbreak prompt 형식은 BlueSuffix 모델이 전혀 본 적 없는 데이터임을 시사함. 공격 방식은 전과 동일. BlueSuffix가 해당 데이터셋에서도 잘 작동하는 것을 확인함.
4.5 ROBUSTNESS TO AN ADAPTIVE ATTACK
BlueSuffix 모델이 다른 adaptive jailbreak 공격에 얼마나 강건한지 실험함. 공격자들이 BlueSuffix 모델에 대한 모든 사양을 안다고 가정하고 진행. 이는 그들이 BAP 공격 방식을 우리 모델에 맞춰 다시 진행할 수 있음을 시사함. (즉, BlueSuffix가 어떠한 방식으로 방어를 진행하는지 알고 있기 때문에 그것에 맞춰 다시 악성 prompt를 작성할 수 있다는 말임.) 새롭게 작성된 prompt 역시, BlueSuffix에 의해서 다시 purify되는 것을 확인함.
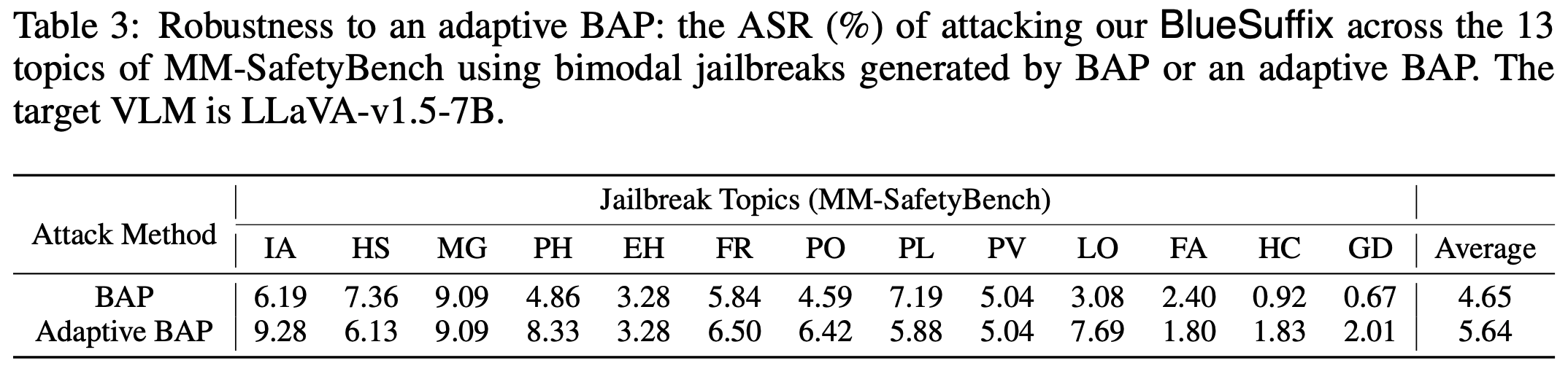
재공격 prompt가 얼마나 효과적으로 작성됐는지, 알 수 없지만, 그럼에도 불구하고 ASR이 평균 1% 정도 밖에 올라가지 않았다는 것을 정말 놀라운 결과인 것 같습니다.
5 CONCLUSION
본 연구에서는 VLM 상에서 jailbreak의 취약점을 발견하고 이를 막기 위한 방안으로 BlueSuffix 모델을 제안함. BlueSuffix 모델을 크게 세가지 구성 요소를 가지고 있음; text purifier, image purifier, blue-team suffix generator. Blue-team suffix는 이전의 모델들과 달리 bimodal gradient를 사용하여 cross-modal 환경에서 강건한 성능을 보여줌. 실제 실험 결과에서 다른 모델들에 비해 높은 방어률을 보임. 또한, adaptive jailbreak 공격에서도 강건한 성능을 자랑함.
Jailbreak, VLM 이런 생소한 용어들이 등장한지 얼마 되지도 않은 것 같은데,
사람들은 언제 자고, 언제 먹고, 언제 이런 연구들을 하는 걸까요???
그만큼 LLM을 빨리 활용하고 싶은 기업이 많은 거겠죠?
이번 논문을 읽고는 Adaptive Jailbreak가 어떻게 작성되는지 조금 궁금해졌어요.
이게 마치 방어 방법을 알면, 진짜 그렇게 방어가 잘 가능해? 내가 공격 더 잘 할 수 있을 것 같은데??
공격 방법을 읽으면, 진짜? 그렇게 잘 공격해? 더 잘 방어하는 모델이 있을 것 같은데???
박쥐같은 마음이 드네요.
이러다보니 제가 개발할 길은 보이지 않고... 점점 더 미궁속으로 빠져드는 것 같아요.

난 몰라